 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneReason Technical Report
Jun 04, 2026Generative recommendation models in the OneRec family have been widely deployed in many real-world services, such as short-video, live-streaming, advertising, and e-commerce. However, these generative models can only benefit from the scaling advantage, while their reasoning ability is hard to activate, since we cannot construct meaningful Chain-of-Thought (CoT) sequences consisting of itemic tokens only. Inspired by the success of the reasoning-style ``think before answer'' paradigm in the LLM field, we conduct preliminary studies (i.e., OneRec-Think, OpenOneRec) to explore reasoning capability in generative recommendation. Nevertheless, we notice an unexpected phenomenon: the thinking mode does not show advantages over the non-thinking mode. Drawing insights from recent findings on CoT robustness in multi-modal language models, we argue that effective reasoning in recommendation rests on two factors: perception, the ability to ground itemic tokens in their underlying language semantics, and cognition, the ability to reorganize a user's behavior sequence into coherent latent interest points. We therefore propose OneReason, which includes: (1) strong itemic token perception in pre-training, (2) a three-level cognition-enhanced CoT format for recommendation tasks in SFT, and (3) a specialize-then-unify training recipe in RL to enhance the thinking ability.
Not only where, But when: Temporal Scheduling for RLVR
May 25, 2026Reinforcement learning with verifiable rewards (RLVR) has become a core technique for post-training of Large Language Models (LLMs). While policy optimization is driven by all sampled tokens under a globally broadcast scalar reward, the heterogeneous policy behaviors exhibited along trajectories are largely overlooked without differentiation. Existing works address this by credit allocation, including token-level advantage reweighting, and selective token optimization, however, the allocation criterion are principally stagnant throughout training, limiting resilient policy evolution. In this work, we argue that \textit{when} learning signals are scheduled can be as important as \textit{where} they are allocated across tokens, and introduce the temporal dimension that scheduling the credit allocation criteria over the course of RLVR optimization. We find that prioritizing targeted tokens emphasized with specific policy behaviors, and gradually attenuating toward general optimization leads to more stable and efficient learning dynamics. Furthermore, we show that simple trajectory percentiles provide a natural perspective for distinguishing policy behaviors, and works effectively with temporal scheduling. Our analysis reveals that standard optimization substantially sacrifices policy entropy when simultaneously accommodating heterogeneous behaviors, whereas temporal scheduling yields healthier policy evolution dynamics. Experiments across mathematical and general reasoning benchmarks demonstrate consistent improvements, suggesting that temporal scheduling constitutes a promising optimization dimension.
Kwai Summary Attention Technical Report
Apr 27, 2026Long-context ability, has become one of the most important iteration direction of next-generation Large Language Models, particularly in semantic understanding/reasoning, code agentic intelligence and recommendation system. However, the standard softmax attention exhibits quadratic time complexity with respect to sequence length. As the sequence length increases, this incurs substantial overhead in long-context settings, leading the training and inference costs of extremely long sequences deteriorate rapidly. Existing solutions mitigate this issue through two technique routings: i) Reducing the KV cache per layer, such as from the head-level compression GQA, and the embedding dimension-level compression MLA, but the KV cache remains linearly dependent on the sequence length at a 1:1 ratio. ii) Interleaving with KV Cache friendly architecture, such as local attention SWA, linear kernel GDN, but often involve trade-offs among KV Cache and long-context modeling effectiveness. Besides the two technique routings, we argue that there exists an intermediate path not well explored: {Maintaining a linear relationship between the KV cache and sequence length, but performing semantic-level compression through a specific ratio $k$}. This $O(n/k)$ path does not pursue a ``minimum KV cache'', but rather trades acceptable memory costs for complete, referential, and interpretable retention of long distant dependency. Motivated by this, we propose Kwai Summary Attention (KSA), a novel attention mechanism that reduces sequence modeling cost by compressing historical contexts into learnable summary tokens.
SEA-Eval: A Benchmark for Evaluating Self-Evolving Agents Beyond Episodic Assessment
Apr 14, 2026Current LLM-based agents demonstrate strong performance in episodic task execution but remain constrained by static toolsets and episodic amnesia, failing to accumulate experience across task boundaries. This paper presents the first formal definition of the Self-Evolving Agent (SEA), formalizes the Evolutionary Flywheel as its minimal sufficient architecture, and introduces SEA-Eval -- the first benchmark designed specifically for evaluating SEAs. Grounded in Flywheel theory, SEA-Eval establishes $SR$ and $T$ as primary metrics and enables through sequential task stream design the independent quantification of evolutionary gain, evolutionary stability, and implicit alignment convergence. Empirical evaluation reveals that under identical success rates, token consumption differs by up to 31.2$\times$ across frameworks, with divergent evolutionary trajectories under sequential analysis -- demonstrating that success rate alone creates a capability illusion and that the sequential convergence of $T$ is the key criterion for distinguishing genuine evolution from pseudo-evolution.
Kelix Technical Report
Feb 12, 2026Autoregressive large language models (LLMs) scale well by expressing diverse tasks as sequences of discrete natural-language tokens and training with next-token prediction, which unifies comprehension and generation under self-supervision. Extending this paradigm to multimodal data requires a shared, discrete representation across modalities. However, most vision-language models (VLMs) still rely on a hybrid interface: discrete text tokens paired with continuous Vision Transformer (ViT) features. Because supervision is largely text-driven, these models are often biased toward understanding and cannot fully leverage large-scale self-supervised learning on non-text data. Recent work has explored discrete visual tokenization to enable fully autoregressive multimodal modeling, showing promising progress toward unified understanding and generation. Yet existing discrete vision tokens frequently lose information due to limited code capacity, resulting in noticeably weaker understanding than continuous-feature VLMs. We present Kelix, a fully discrete autoregressive unified model that closes the understanding gap between discrete and continuous visual representations.
ToolWeaver: Weaving Collaborative Semantics for Scalable Tool Use in Large Language Models
Jan 29, 2026Prevalent retrieval-based tool-use pipelines struggle with a dual semantic challenge: their retrievers often employ encoders that fail to capture complex semantics, while the Large Language Model (LLM) itself lacks intrinsic tool knowledge from its natural language pretraining. Generative methods offer a powerful alternative by unifying selection and execution, tasking the LLM to directly learn and generate tool identifiers. However, the common practice of mapping each tool to a unique new token introduces substantial limitations: it creates a scalability and generalization crisis, as the vocabulary size explodes and each tool is assigned a semantically isolated token. This approach also creates a semantic bottleneck that hinders the learning of collaborative tool relationships, as the model must infer them from sparse co-occurrences of monolithic tool IDs within a vast library. To address these limitations, we propose ToolWeaver, a novel generative tool learning framework that encodes tools into hierarchical sequences. This approach makes vocabulary expansion logarithmic to the number of tools. Crucially, it enables the model to learn collaborative patterns from the dense co-occurrence of shared codes, rather than the sparse co-occurrence of monolithic tool IDs. We generate these structured codes through a novel tokenization process designed to weave together a tool's intrinsic semantics with its extrinsic co-usage patterns. These structured codes are then integrated into the LLM through a generative alignment stage, where the model is fine-tuned to produce the hierarchical code sequences. Evaluation results with nearly 47,000 tools show that ToolWeaver significantly outperforms state-of-the-art methods, establishing a more scalable, generalizable, and semantically-aware foundation for advanced tool-augmented agents.
OpenOneRec Technical Report
Dec 31, 2025While the OneRec series has successfully unified the fragmented recommendation pipeline into an end-to-end generative framework, a significant gap remains between recommendation systems and general intelligence. Constrained by isolated data, they operate as domain specialists-proficient in pattern matching but lacking world knowledge, reasoning capabilities, and instruction following. This limitation is further compounded by the lack of a holistic benchmark to evaluate such integrated capabilities. To address this, our contributions are: 1) RecIF Bench & Open Data: We propose RecIF-Bench, a holistic benchmark covering 8 diverse tasks that thoroughly evaluate capabilities from fundamental prediction to complex reasoning. Concurrently, we release a massive training dataset comprising 96 million interactions from 160,000 users to facilitate reproducible research. 2) Framework & Scaling: To ensure full reproducibility, we open-source our comprehensive training pipeline, encompassing data processing, co-pretraining, and post-training. Leveraging this framework, we demonstrate that recommendation capabilities can scale predictably while mitigating catastrophic forgetting of general knowledge. 3) OneRec-Foundation: We release OneRec Foundation (1.7B and 8B), a family of models establishing new state-of-the-art (SOTA) results across all tasks in RecIF-Bench. Furthermore, when transferred to the Amazon benchmark, our models surpass the strongest baselines with an average 26.8% improvement in Recall@10 across 10 diverse datasets (Figure 1). This work marks a step towards building truly intelligent recommender systems. Nonetheless, realizing this vision presents significant technical and theoretical challenges, highlighting the need for broader research engagement in this promising direction.
CultureScope: A Dimensional Lens for Probing Cultural Understanding in LLMs
Sep 19, 2025As large language models (LLMs) are increasingly deployed in diverse cultural environments, evaluating their cultural understanding capability has become essential for ensuring trustworthy and culturally aligned applications. However, most existing benchmarks lack comprehensiveness and are challenging to scale and adapt across different cultural contexts, because their frameworks often lack guidance from well-established cultural theories and tend to rely on expert-driven manual annotations. To address these issues, we propose CultureScope, the most comprehensive evaluation framework to date for assessing cultural understanding in LLMs. Inspired by the cultural iceberg theory, we design a novel dimensional schema for cultural knowledge classification, comprising 3 layers and 140 dimensions, which guides the automated construction of culture-specific knowledge bases and corresponding evaluation datasets for any given languages and cultures. Experimental results demonstrate that our method can effectively evaluate cultural understanding. They also reveal that existing large language models lack comprehensive cultural competence, and merely incorporating multilingual data does not necessarily enhance cultural understanding. All code and data files are available at https://github.com/HoganZinger/Culture
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
OneRec Technical Report
Jun 16, 2025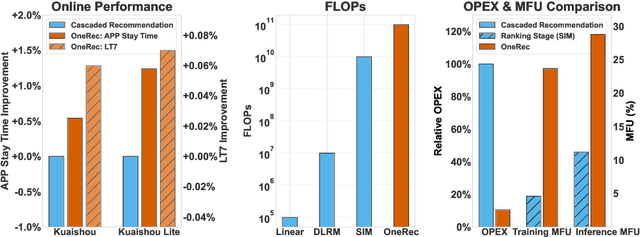

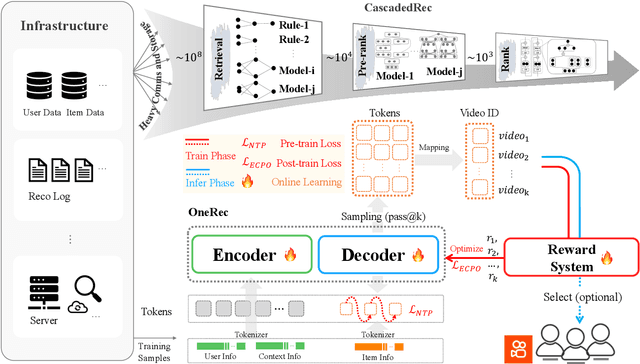

Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.