 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePay Attention to Sequence Split: Uncovering the Impacts of Sub-Sequence Splitting on Sequential Recommendation Models
Apr 07, 2026Sub-sequence splitting (SSS) has been demonstrated as an effective approach to mitigate data sparsity in sequential recommendation (SR) by splitting a raw user interaction sequence into multiple sub-sequences. Previous studies have demonstrated its ability to enhance the performance of SR models significantly. However, in this work, we discover that \textbf{(i). SSS may interfere with the evaluation of the model's actual performance.} We observed that many recent state-of-the-art SR models employ SSS during the data reading stage (not mentioned in the papers). When we removed this operation, performance significantly declined, even falling below that of earlier classical SR models. The varying improvements achieved by SSS and different splitting methods across different models prompt us to analyze further when SSS proves effective. We find that \textbf{(ii). SSS demonstrates strong capabilities only when specific splitting methods, target strategies, and loss functions are used together.} Inappropriate combinations may even harm performance. Furthermore, we analyze why sub-sequence splitting yields such remarkable performance gains and find that \textbf{(iii). it evens out the distribution of training data while increasing the likelihood that different items are targeted.} Finally, we provide suggestions for overcoming SSS interference, along with a discussion on data augmentation methods and future directions. We hope this work will prompt the broader community to re-examine the impact of data splitting on SR and promote fairer, more rigorous model evaluation. All analysis code and data will be made available upon acceptance. We provide a simple, anonymous implementation at https://github.com/KingGugu/SSS4SR.
Tail-Aware Data Augmentation for Long-Tail Sequential Recommendation
Jan 16, 2026Sequential recommendation (SR) learns user preferences based on their historical interaction sequences and provides personalized suggestions. In real-world scenarios, most users can only interact with a handful of items, while the majority of items are seldom consumed. This pervasive long-tail challenge limits the model's ability to learn user preferences. Despite previous efforts to enrich tail items/users with knowledge from head parts or improve tail learning through additional contextual information, they still face the following issues: 1) They struggle to improve the situation where interactions of tail users/items are scarce, leading to incomplete preferences learning for the tail parts. 2) Existing methods often degrade overall or head parts performance when improving accuracy for tail users/items, thereby harming the user experience. We propose Tail-Aware Data Augmentation (TADA) for long-tail sequential recommendation, which enhances the interaction frequency for tail items/users while maintaining head performance, thereby promoting the model's learning capabilities for the tail. Specifically, we first capture the co-occurrence and correlation among low-popularity items by a linear model. Building upon this, we design two tail-aware augmentation operators, T-Substitute and T-Insert. The former replaces the head item with a relevant item, while the latter utilizes co-occurrence relationships to extend the original sequence by incorporating both head and tail items. The augmented and original sequences are mixed at the representation level to preserve preference knowledge. We further extend the mix operation across different tail-user sequences and augmented sequences to generate richer augmented samples, thereby improving tail performance. Comprehensive experiments demonstrate the superiority of our method. The codes are provided at https://github.com/KingGugu/TADA.
MoFu: Scale-Aware Modulation and Fourier Fusion for Multi-Subject Video Generation
Dec 26, 2025Multi-subject video generation aims to synthesize videos from textual prompts and multiple reference images, ensuring that each subject preserves natural scale and visual fidelity. However, current methods face two challenges: scale inconsistency, where variations in subject size lead to unnatural generation, and permutation sensitivity, where the order of reference inputs causes subject distortion. In this paper, we propose MoFu, a unified framework that tackles both challenges. For scale inconsistency, we introduce Scale-Aware Modulation (SMO), an LLM-guided module that extracts implicit scale cues from the prompt and modulates features to ensure consistent subject sizes. To address permutation sensitivity, we present a simple yet effective Fourier Fusion strategy that processes the frequency information of reference features via the Fast Fourier Transform to produce a unified representation. Besides, we design a Scale-Permutation Stability Loss to jointly encourage scale-consistent and permutation-invariant generation. To further evaluate these challenges, we establish a dedicated benchmark with controlled variations in subject scale and reference permutation. Extensive experiments demonstrate that MoFu significantly outperforms existing methods in preserving natural scale, subject fidelity, and overall visual quality.
Causal Negative Sampling via Diffusion Model for Out-of-Distribution Recommendation
Aug 10, 2025



Heuristic negative sampling enhances recommendation performance by selecting negative samples of varying hardness levels from predefined candidate pools to guide the model toward learning more accurate decision boundaries. However, our empirical and theoretical analyses reveal that unobserved environmental confounders (e.g., exposure or popularity biases) in candidate pools may cause heuristic sampling methods to introduce false hard negatives (FHNS). These misleading samples can encourage the model to learn spurious correlations induced by such confounders, ultimately compromising its generalization ability under distribution shifts. To address this issue, we propose a novel method named Causal Negative Sampling via Diffusion (CNSDiff). By synthesizing negative samples in the latent space via a conditional diffusion process, CNSDiff avoids the bias introduced by predefined candidate pools and thus reduces the likelihood of generating FHNS. Moreover, it incorporates a causal regularization term to explicitly mitigate the influence of environmental confounders during the negative sampling process, leading to robust negatives that promote out-of-distribution (OOD) generalization. Comprehensive experiments under four representative distribution shift scenarios demonstrate that CNSDiff achieves an average improvement of 13.96% across all evaluation metrics compared to state-of-the-art baselines, verifying its effectiveness and robustness in OOD recommendation tasks.
RAGAR: Retrieval Augment Personalized Image Generation Guided by Recommendation
May 03, 2025Personalized image generation is crucial for improving the user experience, as it renders reference images into preferred ones according to user visual preferences. Although effective, existing methods face two main issues. First, existing methods treat all items in the user historical sequence equally when extracting user preferences, overlooking the varying semantic similarities between historical items and the reference item. Disproportionately high weights for low-similarity items distort users' visual preferences for the reference item. Second, existing methods heavily rely on consistency between generated and reference images to optimize the generation, which leads to underfitting user preferences and hinders personalization. To address these issues, we propose Retrieval Augment Personalized Image GenerAtion guided by Recommendation (RAGAR). Our approach uses a retrieval mechanism to assign different weights to historical items according to their similarities to the reference item, thereby extracting more refined users' visual preferences for the reference item. Then we introduce a novel rank task based on the multi-modal ranking model to optimize the personalization of the generated images instead of forcing depend on consistency. Extensive experiments and human evaluations on three real-world datasets demonstrate that RAGAR achieves significant improvements in both personalization and semantic metrics compared to five baselines.
Data Augmentation as Free Lunch: Exploring the Test-Time Augmentation for Sequential Recommendation
Apr 07, 2025Data augmentation has become a promising method of mitigating data sparsity in sequential recommendation. Existing methods generate new yet effective data during model training to improve performance. However, deploying them requires retraining, architecture modification, or introducing additional learnable parameters. The above steps are time-consuming and costly for well-trained models, especially when the model scale becomes large. In this work, we explore the test-time augmentation (TTA) for sequential recommendation, which augments the inputs during the model inference and then aggregates the model's predictions for augmented data to improve final accuracy. It avoids significant time and cost overhead from loss calculation and backward propagation. We first experimentally disclose the potential of existing augmentation operators for TTA and find that the Mask and Substitute consistently achieve better performance. Further analysis reveals that these two operators are effective because they retain the original sequential pattern while adding appropriate perturbations. Meanwhile, we argue that these two operators still face time-consuming item selection or interference information from mask tokens. Based on the analysis and limitations, we present TNoise and TMask. The former injects uniform noise into the original representation, avoiding the computational overhead of item selection. The latter blocks mask token from participating in model calculations or directly removes interactions that should have been replaced with mask tokens. Comprehensive experiments demonstrate the effectiveness, efficiency, and generalizability of our method. We provide an anonymous implementation at https://github.com/KingGugu/TTA4SR.
Can LLM-Driven Hard Negative Sampling Empower Collaborative Filtering? Findings and Potentials
Apr 07, 2025Hard negative samples can accelerate model convergence and optimize decision boundaries, which is key to improving the performance of recommender systems. Although large language models (LLMs) possess strong semantic understanding and generation capabilities, systematic research has not yet been conducted on how to generate hard negative samples effectively. To fill this gap, this paper introduces the concept of Semantic Negative Sampling and exploreshow to optimize LLMs for high-quality, hard negative sampling. Specifically, we design an experimental pipeline that includes three main modules, profile generation, semantic negative sampling, and semantic alignment, to verify the potential of LLM-driven hard negative sampling in enhancing the accuracy of collaborative filtering (CF). Experimental results indicate that hard negative samples generated based on LLMs, when semantically aligned and integrated into CF, can significantly improve CF performance, although there is still a certain gap compared to traditional negative sampling methods. Further analysis reveals that this gap primarily arises from two major challenges: noisy samples and lack of behavioral constraints. To address these challenges, we propose a framework called HNLMRec, based on fine-tuning LLMs supervised by collaborative signals. Experimental results show that this framework outperforms traditional negative sampling and other LLM-driven recommendation methods across multiple datasets, providing new solutions for empowering traditional RS with LLMs. Additionally, we validate the excellent generalization ability of the LLM-based semantic negative sampling method on new datasets, demonstrating its potential in alleviating issues such as data sparsity, popularity bias, and the problem of false hard negative samples. Our implementation code is available at https://github.com/user683/HNLMRec.
Distributionally Robust Graph Out-of-Distribution Recommendation via Diffusion Model
Jan 26, 2025The distributionally robust optimization (DRO)-based graph neural network methods improve recommendation systems' out-of-distribution (OOD) generalization by optimizing the model's worst-case performance. However, these studies fail to consider the impact of noisy samples in the training data, which results in diminished generalization capabilities and lower accuracy. Through experimental and theoretical analysis, this paper reveals that current DRO-based graph recommendation methods assign greater weight to noise distribution, leading to model parameter learning being dominated by it. When the model overly focuses on fitting noise samples in the training data, it may learn irrelevant or meaningless features that cannot be generalized to OOD data. To address this challenge, we design a Distributionally Robust Graph model for OOD recommendation (DRGO). Specifically, our method first employs a simple and effective diffusion paradigm to alleviate the noisy effect in the latent space. Additionally, an entropy regularization term is introduced in the DRO objective function to avoid extreme sample weights in the worst-case distribution. Finally, we provide a theoretical proof of the generalization error bound of DRGO as well as a theoretical analysis of how our approach mitigates noisy sample effects, which helps to better understand the proposed framework from a theoretical perspective. We conduct extensive experiments on four datasets to evaluate the effectiveness of our framework against three typical distribution shifts, and the results demonstrate its superiority in both independently and identically distributed distributions (IID) and OOD.
Self-supervised Hierarchical Representation for Medication Recommendation
Nov 05, 2024



Medication recommender is to suggest appropriate medication combinations based on a patient's health history, e.g., diagnoses and procedures. Existing works represent different diagnoses/procedures well separated by one-hot encodings. However, they ignore the latent hierarchical structures of these medical terms, undermining the generalization performance of the model. For example, "Respiratory Diseases", "Chronic Respiratory Diseases" and "Chronic Bronchiti" have a hierarchical relationship, progressing from general to specific. To address this issue, we propose a novel hierarchical encoder named HIER to hierarchically represent diagnoses and procedures, which is based on standard medical codes and compatible with any existing methods. Specifically, the proposed method learns relation embedding with a self-supervised objective for incorporating the neighbor hierarchical structure. Additionally, we develop the position encoding to explicitly introduce global hierarchical position. Extensive experiments demonstrate significant and consistent improvements in recommendation accuracy across four baselines and two real-world clinical datasets.
Double-Side Delay Alignment Modulation for Multi-User Millimeter Wave and TeraHertz Communications
Oct 22, 2024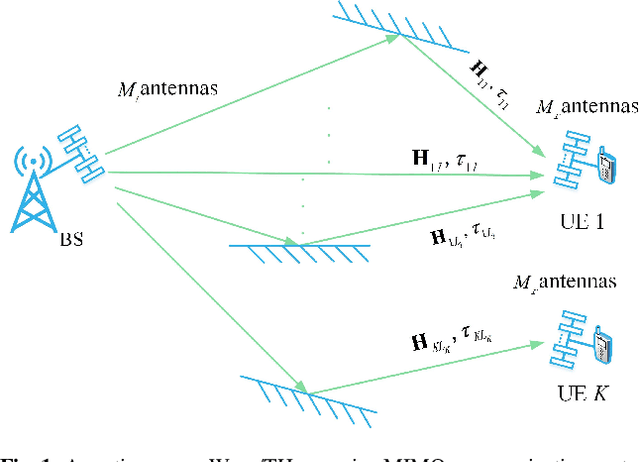
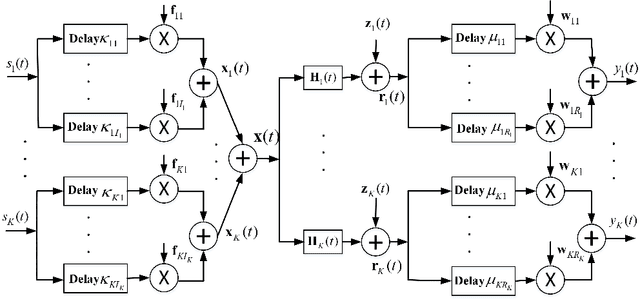
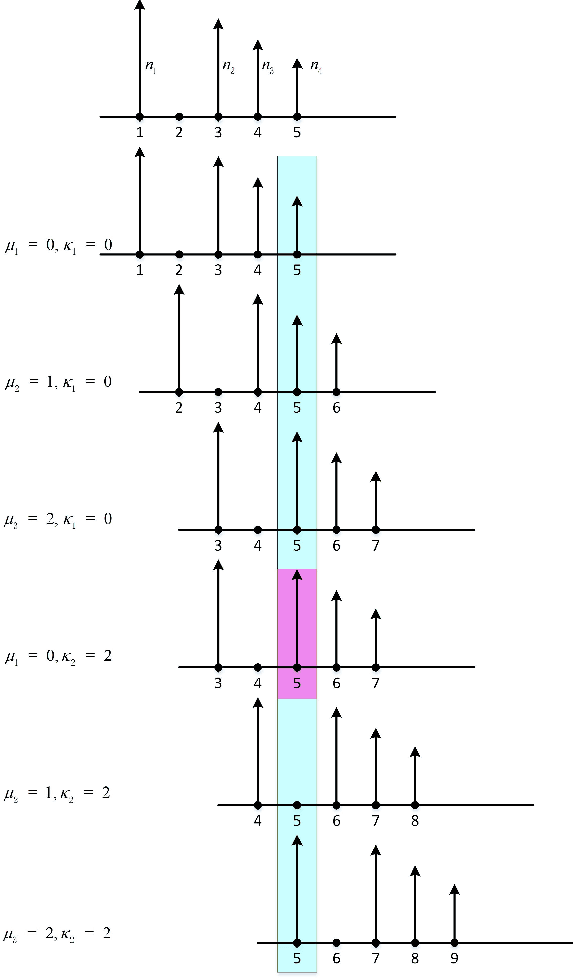
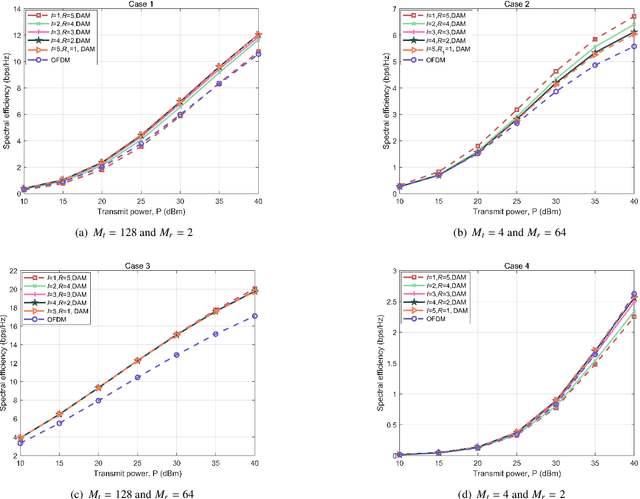
Delay alignment modulation (DAM) is an innovative broadband modulation technique well suited for millimeter wave (mmWave) and terahertz (THz) massive multiple-input multiple-output (MIMO) communication systems. Leveraging the high spatial resolution and sparsity of multi-path channels, DAM mitigates inter-symbol interference (ISI) effectively, by aligning all multi-path components through a combination of delay pre/post-compensation and path-based beamforming. As such, ISI is eliminated while preserving multi-path power gains. In this paper, we explore multi-user double-side DAM with both delay pre-compensation at the transmitter and post-compensation at the receiver, contrasting with prior one-side DAM that primarily focuses on delay pre-compensation only. Firstly, we reveal the constraint for the introduced delays and the delay pre/post-compensation vectors tailored for multi-user double-side DAM, given a specific number of delay pre/post-compensations. Furthermore, we show that as long as the number of base station (BS)/user equipment (UE) antennas is sufficiently large, single-side DAM, where delay compensation is only performed at the BS/UE, is preferred than double-side DAM since the former results in less ISI to be spatially eliminated. Next, we propose two low-complexity path-based beamforming strategies based on the eigen-beamforming transmission and ISI-zero forcing (ZF) principles, respectively, based on which the achievable sum rates are studied. Simulation results verify that with sufficiently large BS/UE antennas, single-side DAM is sufficient. Furthermore, compared to the benchmark scheme of orthogonal frequency division multiplexing (OFDM), multi-user BS-side DAM achieves higher spectral efficiency and/or lower peak-to-average power ratio (PAPR).