 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGAR: Retrieval Augment Personalized Image Generation Guided by Recommendation
May 03, 2025Personalized image generation is crucial for improving the user experience, as it renders reference images into preferred ones according to user visual preferences. Although effective, existing methods face two main issues. First, existing methods treat all items in the user historical sequence equally when extracting user preferences, overlooking the varying semantic similarities between historical items and the reference item. Disproportionately high weights for low-similarity items distort users' visual preferences for the reference item. Second, existing methods heavily rely on consistency between generated and reference images to optimize the generation, which leads to underfitting user preferences and hinders personalization. To address these issues, we propose Retrieval Augment Personalized Image GenerAtion guided by Recommendation (RAGAR). Our approach uses a retrieval mechanism to assign different weights to historical items according to their similarities to the reference item, thereby extracting more refined users' visual preferences for the reference item. Then we introduce a novel rank task based on the multi-modal ranking model to optimize the personalization of the generated images instead of forcing depend on consistency. Extensive experiments and human evaluations on three real-world datasets demonstrate that RAGAR achieves significant improvements in both personalization and semantic metrics compared to five baselines.
Efficient Prompt Tuning by Multi-Space Projection and Prompt Fusion
May 19, 2024



Prompt tuning is a promising method to fine-tune a pre-trained language model without retraining its large-scale parameters. Instead, it attaches a soft prompt to the input text, whereby downstream tasks can be well adapted by merely learning the embeddings of prompt tokens. Nevertheless, existing methods still suffer from two challenges: (i) they are hard to balance accuracy and efficiency. A longer (shorter) soft prompt generally leads to a better (worse) accuracy but at the cost of more (less) training time. (ii) The performance may not be consistent when adapting to different downstream tasks. We attribute it to the same embedding space but responsible for different requirements of downstream tasks. To address these issues, we propose an Efficient Prompt Tuning method (EPT) by multi-space projection and prompt fusion. Specifically, it decomposes a given soft prompt into a shorter prompt and two low-rank matrices, whereby the number of parameters is greatly reduced as well as the training time. The accuracy is also enhanced by leveraging low-rank matrices and the short prompt as additional knowledge sources to enrich the semantics of the original short prompt. In addition, we project the soft prompt into multiple subspaces to improve the performance consistency, and then adaptively learn the combination weights of different spaces through a gating network. Experimental experiments on 13 natural language processing downstream tasks show that our method significantly and consistently outperforms 11 comparison methods with the relative percentage of improvements up to 28.8%, and training time decreased by 14%.
Repeated Padding as Data Augmentation for Sequential Recommendation
Mar 11, 2024



Sequential recommendation aims to provide users with personalized suggestions based on their historical interactions. When training sequential models, padding is a widely adopted technique for two main reasons: 1) The vast majority of models can only handle fixed-length sequences; 2) Batching-based training needs to ensure that the sequences in each batch have the same length. The special value \emph{0} is usually used as the padding content, which does not contain the actual information and is ignored in the model calculations. This common-sense padding strategy leads us to a problem that has never been explored before: \emph{Can we fully utilize this idle input space by padding other content to further improve model performance and training efficiency?} In this paper, we propose a simple yet effective padding method called \textbf{Rep}eated \textbf{Pad}ding (\textbf{RepPad}). Specifically, we use the original interaction sequences as the padding content and fill it to the padding positions during model training. This operation can be performed a finite number of times or repeated until the input sequences' length reaches the maximum limit. Our RepPad can be viewed as a sequence-level data augmentation strategy. Unlike most existing works, our method contains no trainable parameters or hyperparameters and is a plug-and-play data augmentation operation. Extensive experiments on various categories of sequential models and five real-world datasets demonstrate the effectiveness and efficiency of our approach. The average recommendation performance improvement is up to 60.3\% on GRU4Rec and 24.3\% on SASRec. We also provide in-depth analysis and explanation of what makes RepPad effective from multiple perspectives. The source code will be released to ensure the reproducibility of our experiments.
ID Embedding as Subtle Features of Content and Structure for Multimodal Recommendation
Nov 10, 2023


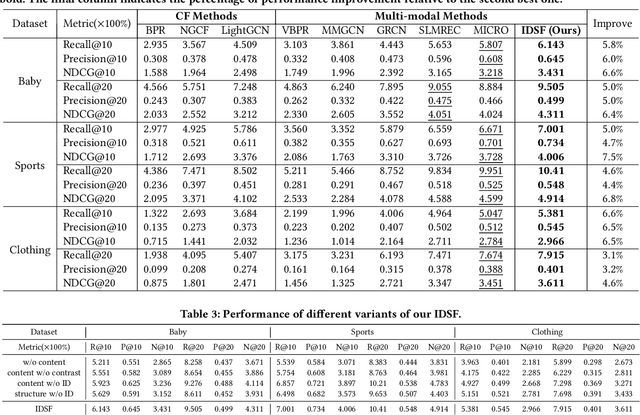
Multimodal recommendation aims to model user and item representations comprehensively with the involvement of multimedia content for effective recommendations. Existing research has shown that it is beneficial for recommendation performance to combine (user- and item-) ID embeddings with multimodal salient features, indicating the value of IDs. However, there is a lack of a thorough analysis of the ID embeddings in terms of feature semantics in the literature. In this paper, we revisit the value of ID embeddings for multimodal recommendation and conduct a thorough study regarding its semantics, which we recognize as subtle features of content and structures. Then, we propose a novel recommendation model by incorporating ID embeddings to enhance the semantic features of both content and structures. Specifically, we put forward a hierarchical attention mechanism to incorporate ID embeddings in modality fusing, coupled with contrastive learning, to enhance content representations. Meanwhile, we propose a lightweight graph convolutional network for each modality to amalgamate neighborhood and ID embeddings for improving structural representations. Finally, the content and structure representations are combined to form the ultimate item embedding for recommendation. Extensive experiments on three real-world datasets (Baby, Sports, and Clothing) demonstrate the superiority of our method over state-of-the-art multimodal recommendation methods and the effectiveness of fine-grained ID embeddings.
Video and Audio are Images: A Cross-Modal Mixer for Original Data on Video-Audio Retrieval
Aug 26, 2023



Cross-modal retrieval has become popular in recent years, particularly with the rise of multimedia. Generally, the information from each modality exhibits distinct representations and semantic information, which makes feature tends to be in separate latent spaces encoded with dual-tower architecture and makes it difficult to establish semantic relationships between modalities, resulting in poor retrieval performance. To address this issue, we propose a novel framework for cross-modal retrieval which consists of a cross-modal mixer, a masked autoencoder for pre-training, and a cross-modal retriever for downstream tasks.In specific, we first adopt cross-modal mixer and mask modeling to fuse the original modality and eliminate redundancy. Then, an encoder-decoder architecture is applied to achieve a fuse-then-separate task in the pre-training phase.We feed masked fused representations into the encoder and reconstruct them with the decoder, ultimately separating the original data of two modalities. In downstream tasks, we use the pre-trained encoder to build the cross-modal retrieval method. Extensive experiments on 2 real-world datasets show that our approach outperforms previous state-of-the-art methods in video-audio matching tasks, improving retrieval accuracy by up to 2 times. Furthermore, we prove our model performance by transferring it to other downstream tasks as a universal model.
Uniform Sequence Better: Time Interval Aware Data Augmentation for Sequential Recommendation
Dec 16, 2022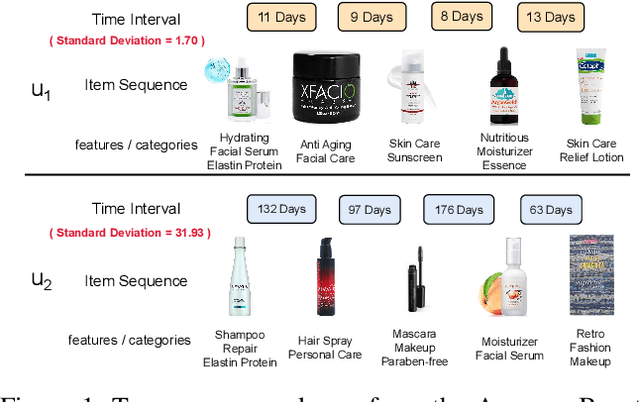
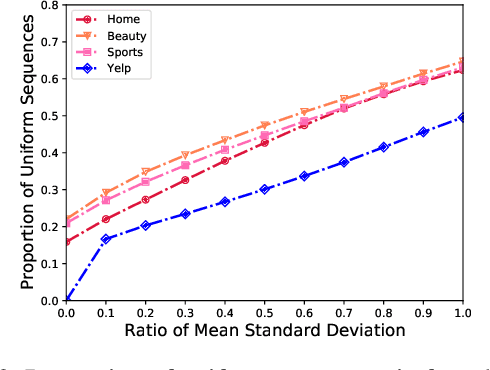
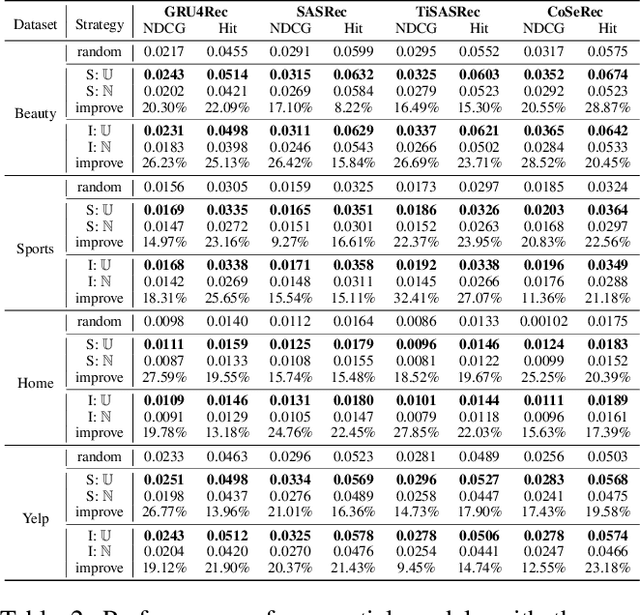
Sequential recommendation is an important task to predict the next-item to access based on a sequence of interacted items. Most existing works learn user preference as the transition pattern from the previous item to the next one, ignoring the time interval between these two items. However, we observe that the time interval in a sequence may vary significantly different, and thus result in the ineffectiveness of user modeling due to the issue of \emph{preference drift}. In fact, we conducted an empirical study to validate this observation, and found that a sequence with uniformly distributed time interval (denoted as uniform sequence) is more beneficial for performance improvement than that with greatly varying time interval. Therefore, we propose to augment sequence data from the perspective of time interval, which is not studied in the literature. Specifically, we design five operators (Ti-Crop, Ti-Reorder, Ti-Mask, Ti-Substitute, Ti-Insert) to transform the original non-uniform sequence to uniform sequence with the consideration of variance of time intervals. Then, we devise a control strategy to execute data augmentation on item sequences in different lengths. Finally, we implement these improvements on a state-of-the-art model CoSeRec and validate our approach on four real datasets. The experimental results show that our approach reaches significantly better performance than the other 11 competing methods. Our implementation is available: https://github.com/KingGugu/TiCoSeRec.