 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnmasking Reasoning Processes: A Process-aware Benchmark for Evaluating Structural Mathematical Reasoning in LLMs
Jan 31, 2026Recent large language models (LLMs) achieve near-saturation accuracy on many established mathematical reasoning benchmarks, raising concerns about their ability to diagnose genuine reasoning competence. This saturation largely stems from the dominance of template-based computation and shallow arithmetic decomposition in existing datasets, which underrepresent reasoning skills such as multi-constraint coordination, constructive logical synthesis, and spatial inference. To address this gap, we introduce ReasoningMath-Plus, a benchmark of 150 carefully curated problems explicitly designed to evaluate structural reasoning. Each problem emphasizes reasoning under interacting constraints, constructive solution formation, or non-trivial structural insight, and is annotated with a minimal reasoning skeleton to support fine-grained process-level evaluation. Alongside the dataset, we introduce HCRS (Hazard-aware Chain-based Rule Score), a deterministic step-level scoring function, and train a Process Reward Model (PRM) on the annotated reasoning traces. Empirically, while leading models attain relatively high final-answer accuracy (up to 5.8/10), HCRS-based holistic evaluation yields substantially lower scores (average 4.36/10, best 5.14/10), showing that answer-only metrics can overestimate reasoning robustness.
Towards End-to-End Alignment of User Satisfaction via Questionnaire in Video Recommendation
Jan 28, 2026Short-video recommender systems typically optimize ranking models using dense user behavioral signals, such as clicks and watch time. However, these signals are only indirect proxies of user satisfaction and often suffer from noise and bias. Recently, explicit satisfaction feedback collected through questionnaires has emerged as a high-quality direct alignment supervision, but is extremely sparse and easily overwhelmed by abundant behavioral data, making it difficult to incorporate into online recommendation models. To address these challenges, we propose a novel framework which is towards End-to-End Alignment of user Satisfaction via Questionaire, named EASQ, to enable real-time alignment of ranking models with true user satisfaction. Specifically, we first construct an independent parameter pathway for sparse questionnaire signals by combining a multi-task architecture and a lightweight LoRA module. The multi-task design separates sparse satisfaction supervision from dense behavioral signals, preventing the former from being overwhelmed. The LoRA module pre-inject these preferences in a parameter-isolated manner, ensuring stability in the backbone while optimizing user satisfaction. Furthermore, we employ a DPO-based optimization objective tailored for online learning, which aligns the main model outputs with sparse satisfaction signals in real time. This design enables end-to-end online learning, allowing the model to continuously adapt to new questionnaire feedback while maintaining the stability and effectiveness of the backbone. Extensive offline experiments and large-scale online A/B tests demonstrate that EASQ consistently improves user satisfaction metrics across multiple scenarios. EASQ has been successfully deployed in a production short-video recommendation system, delivering significant and stable business gains.
S$^2$GR: Stepwise Semantic-Guided Reasoning in Latent Space for Generative Recommendation
Jan 26, 2026Generative Recommendation (GR) has emerged as a transformative paradigm with its end-to-end generation advantages. However, existing GR methods primarily focus on direct Semantic ID (SID) generation from interaction sequences, failing to activate deeper reasoning capabilities analogous to those in large language models and thus limiting performance potential. We identify two critical limitations in current reasoning-enhanced GR approaches: (1) Strict sequential separation between reasoning and generation steps creates imbalanced computational focus across hierarchical SID codes, degrading quality for SID codes; (2) Generated reasoning vectors lack interpretable semantics, while reasoning paths suffer from unverifiable supervision. In this paper, we propose stepwise semantic-guided reasoning in latent space (S$^2$GR), a novel reasoning enhanced GR framework. First, we establish a robust semantic foundation via codebook optimization, integrating item co-occurrence relationship to capture behavioral patterns, and load balancing and uniformity objectives that maximize codebook utilization while reinforcing coarse-to-fine semantic hierarchies. Our core innovation introduces the stepwise reasoning mechanism inserting thinking tokens before each SID generation step, where each token explicitly represents coarse-grained semantics supervised via contrastive learning against ground-truth codebook cluster distributions ensuring physically grounded reasoning paths and balanced computational focus across all SID codes. Extensive experiments demonstrate the superiority of S$^2$GR, and online A/B test confirms efficacy on large-scale industrial short video platform.
Logics-STEM: Empowering LLM Reasoning via Failure-Driven Post-Training and Document Knowledge Enhancement
Jan 08, 2026We present Logics-STEM, a state-of-the-art reasoning model fine-tuned on Logics-STEM-SFT-Dataset, a high-quality and diverse dataset at 10M scale that represents one of the largest-scale open-source long chain-of-thought corpora. Logics-STEM targets reasoning tasks in the domains of Science, Technology, Engineering, and Mathematics (STEM), and exhibits exceptional performance on STEM-related benchmarks with an average improvement of 4.68% over the next-best model at 8B scale. We attribute the gains to our data-algorithm co-design engine, where they are jointly optimized to fit a gold-standard distribution behind reasoning. Data-wise, the Logics-STEM-SFT-Dataset is constructed from a meticulously designed data curation engine with 5 stages to ensure the quality, diversity, and scalability, including annotation, deduplication, decontamination, distillation, and stratified sampling. Algorithm-wise, our failure-driven post-training framework leverages targeted knowledge retrieval and data synthesis around model failure regions in the Supervised Fine-tuning (SFT) stage to effectively guide the second-stage SFT or the reinforcement learning (RL) for better fitting the target distribution. The superior empirical performance of Logics-STEM reveals the vast potential of combining large-scale open-source data with carefully designed synthetic data, underscoring the critical role of data-algorithm co-design in enhancing reasoning capabilities through post-training. We make both the Logics-STEM models (8B and 32B) and the Logics-STEM-SFT-Dataset (10M and downsampled 2.2M versions) publicly available to support future research in the open-source community.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
An End-to-End Multi-objective Ensemble Ranking Framework for Video Recommendation
Aug 07, 2025We propose a novel End-to-end Multi-objective Ensemble Ranking framework (EMER) for the multi-objective ensemble ranking module, which is the most critical component of the short video recommendation system. EMER enhances personalization by replacing manually-designed heuristic formulas with an end-to-end modeling paradigm. EMER introduces a meticulously designed loss function to address the fundamental challenge of defining effective supervision for ensemble ranking, where no single ground-truth signal can fully capture user satisfaction. Moreover, EMER introduces novel sample organization method and transformer-based network architecture to capture the comparative relationships among candidates, which are critical for effective ranking. Additionally, we have proposed an offline-online consistent evaluation system to enhance the efficiency of offline model optimization, which is an established yet persistent challenge within the multi-objective ranking domain in industry. Abundant empirical tests are conducted on a real industrial dataset, and the results well demonstrate the effectiveness of our proposed framework. In addition, our framework has been deployed in the primary scenarios of Kuaishou, a short video recommendation platform with hundreds of millions of daily active users, achieving a 1.39% increase in overall App Stay Time and a 0.196% increase in 7-day user Lifetime(LT7), which are substantial improvements.
OneRec Technical Report
Jun 16, 2025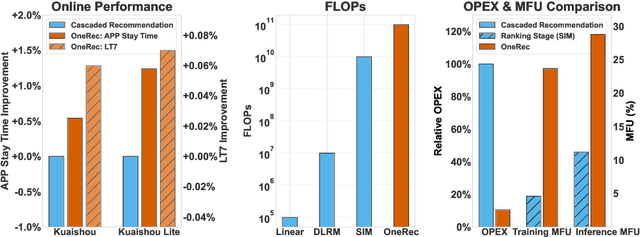

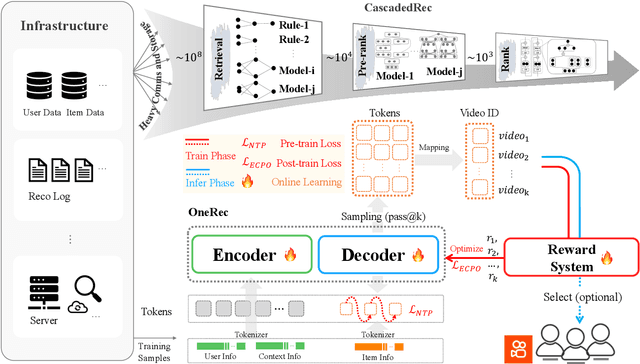

Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
Incorporating Group Prior into Variational Inference for Tail-User Behavior Modeling in CTR Prediction
Oct 19, 2024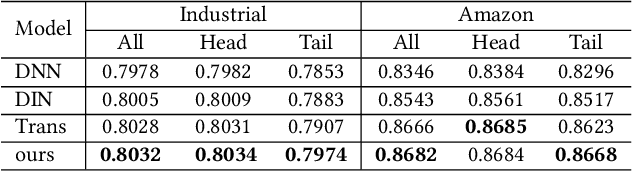


User behavior modeling -- which aims to extract user interests from behavioral data -- has shown great power in Click-through rate (CTR) prediction, a key component in recommendation systems. Recently, attention-based algorithms have become a promising direction, as attention mechanisms emphasize the relevant interactions from rich behaviors. However, the methods struggle to capture the preferences of tail users with sparse interaction histories. To address the problem, we propose a novel variational inference approach, namely Group Prior Sampler Variational Inference (GPSVI), which introduces group preferences as priors to refine latent user interests for tail users. In GPSVI, the extent of adjustments depends on the estimated uncertainty of individual preference modeling. In addition, We further enhance the expressive power of variational inference by a volume-preserving flow. An appealing property of the GPSVI method is its ability to revert to traditional attention for head users with rich behavioral data while consistently enhancing performance for long-tail users with sparse behaviors. Rigorous analysis and extensive experiments demonstrate that GPSVI consistently improves the performance of tail users. Moreover, online A/B testing on a large-scale real-world recommender system further confirms the effectiveness of our proposed approach.
Evaluating Semantic Variation in Text-to-Image Synthesis: A Causal Perspective
Oct 14, 2024
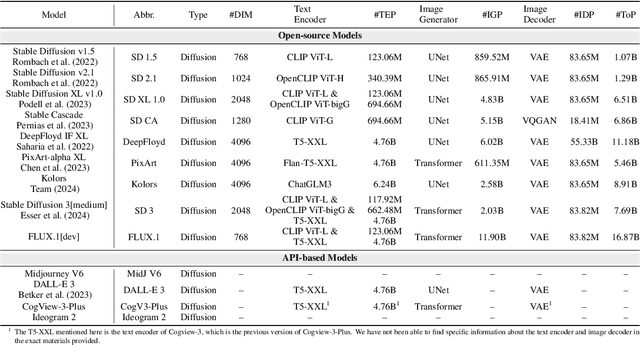
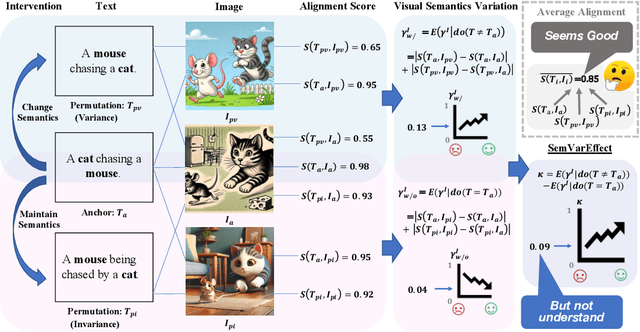
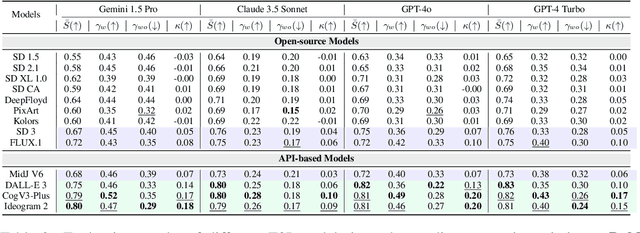
Accurate interpretation and visualization of human instructions are crucial for text-to-image (T2I) synthesis. However, current models struggle to capture semantic variations from word order changes, and existing evaluations, relying on indirect metrics like text-image similarity, fail to reliably assess these challenges. This often obscures poor performance on complex or uncommon linguistic patterns by the focus on frequent word combinations. To address these deficiencies, we propose a novel metric called SemVarEffect and a benchmark named SemVarBench, designed to evaluate the causality between semantic variations in inputs and outputs in T2I synthesis. Semantic variations are achieved through two types of linguistic permutations, while avoiding easily predictable literal variations. Experiments reveal that the CogView-3-Plus and Ideogram 2 performed the best, achieving a score of 0.2/1. Semantic variations in object relations are less understood than attributes, scoring 0.07/1 compared to 0.17-0.19/1. We found that cross-modal alignment in UNet or Transformers plays a crucial role in handling semantic variations, a factor previously overlooked by a focus on textual encoders. Our work establishes an effective evaluation framework that advances the T2I synthesis community's exploration of human instruction understanding.
Learning Social Graph for Inactive User Recommendation
May 08, 2024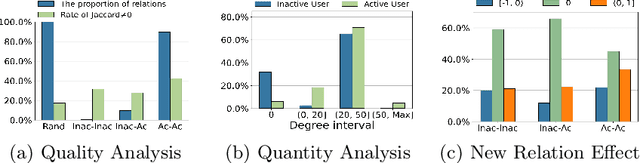

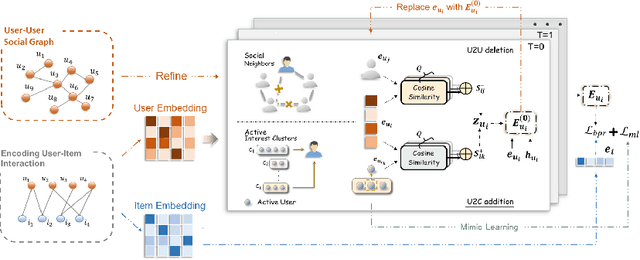
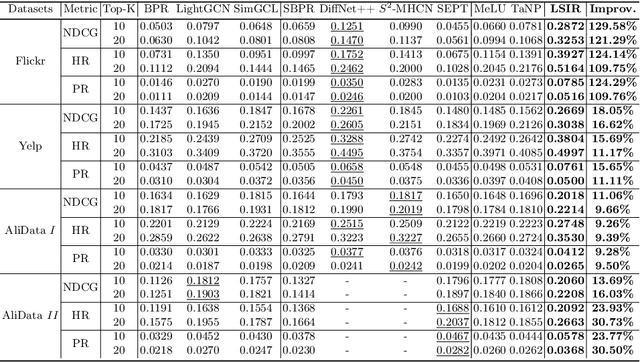
Social relations have been widely incorporated into recommender systems to alleviate data sparsity problem. However, raw social relations don't always benefit recommendation due to their inferior quality and insufficient quantity, especially for inactive users, whose interacted items are limited. In this paper, we propose a novel social recommendation method called LSIR (\textbf{L}earning \textbf{S}ocial Graph for \textbf{I}nactive User \textbf{R}ecommendation) that learns an optimal social graph structure for social recommendation, especially for inactive users. LSIR recursively aggregates user and item embeddings to collaboratively encode item and user features. Then, graph structure learning (GSL) is employed to refine the raw user-user social graph, by removing noisy edges and adding new edges based on the enhanced embeddings. Meanwhile, mimic learning is implemented to guide active users in mimicking inactive users during model training, which improves the construction of new edges for inactive users. Extensive experiments on real-world datasets demonstrate that LSIR achieves significant improvements of up to 129.58\% on NDCG in inactive user recommendation. Our code is available at~\url{https://github.com/liun-online/LSIR}.