 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCFNet: Bidirectional face-bone transformation via a Transformer-based coarse-to-fine point movement network
Aug 20, 2025Computer-aided surgical simulation is a critical component of orthognathic surgical planning, where accurately simulating face-bone shape transformations is significant. The traditional biomechanical simulation methods are limited by their computational time consumption levels, labor-intensive data processing strategies and low accuracy. Recently, deep learning-based simulation methods have been proposed to view this problem as a point-to-point transformation between skeletal and facial point clouds. However, these approaches cannot process large-scale points, have limited receptive fields that lead to noisy points, and employ complex preprocessing and postprocessing operations based on registration. These shortcomings limit the performance and widespread applicability of such methods. Therefore, we propose a Transformer-based coarse-to-fine point movement network (TCFNet) to learn unique, complicated correspondences at the patch and point levels for dense face-bone point cloud transformations. This end-to-end framework adopts a Transformer-based network and a local information aggregation network (LIA-Net) in the first and second stages, respectively, which reinforce each other to generate precise point movement paths. LIA-Net can effectively compensate for the neighborhood precision loss of the Transformer-based network by modeling local geometric structures (edges, orientations and relative position features). The previous global features are employed to guide the local displacement using a gated recurrent unit. Inspired by deformable medical image registration, we propose an auxiliary loss that can utilize expert knowledge for reconstructing critical organs.Compared with the existing state-of-the-art (SOTA) methods on gathered datasets, TCFNet achieves outstanding evaluation metrics and visualization results. The code is available at https://github.com/Runshi-Zhang/TCFNet.
* 17 pages, 11 figures
Self-Route: Automatic Mode Switching via Capability Estimation for Efficient Reasoning
May 27, 2025While reasoning-augmented large language models (RLLMs) significantly enhance complex task performance through extended reasoning chains, they inevitably introduce substantial unnecessary token consumption, particularly for simpler problems where Short Chain-of-Thought (Short CoT) suffices. This overthinking phenomenon leads to inefficient resource usage without proportional accuracy gains. To address this issue, we propose Self-Route, a dynamic reasoning framework that automatically selects between general and reasoning modes based on model capability estimation. Our approach introduces a lightweight pre-inference stage to extract capability-aware embeddings from hidden layer representations, enabling real-time evaluation of the model's ability to solve problems. We further construct Gradient-10K, a model difficulty estimation-based dataset with dense complexity sampling, to train the router for precise capability boundary detection. Extensive experiments demonstrate that Self-Route achieves comparable accuracy to reasoning models while reducing token consumption by 30-55\% across diverse benchmarks. The proposed framework demonstrates consistent effectiveness across models with different parameter scales and reasoning paradigms, highlighting its general applicability and practical value.
Bridging the Long-Term Gap: A Memory-Active Policy for Multi-Session Task-Oriented Dialogue
May 26, 2025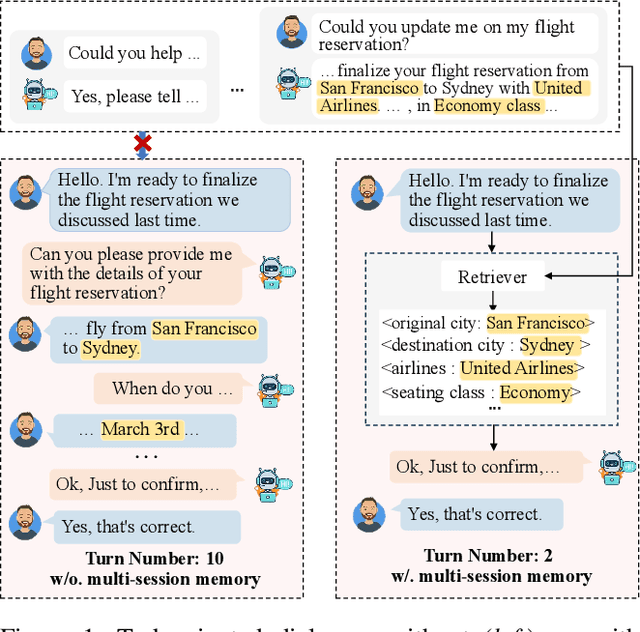
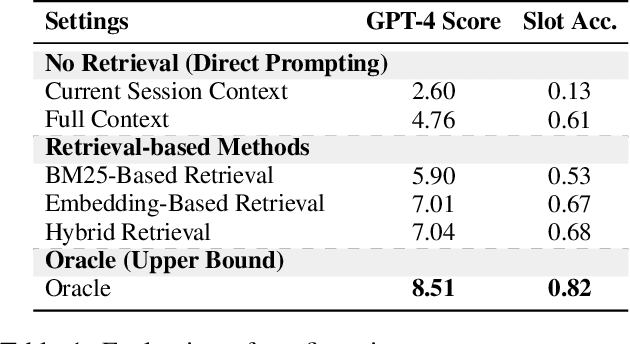
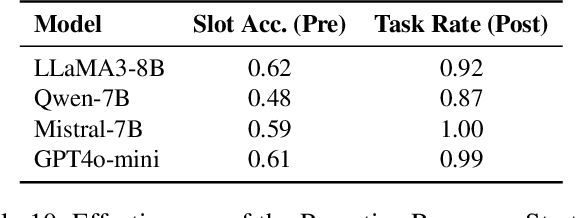
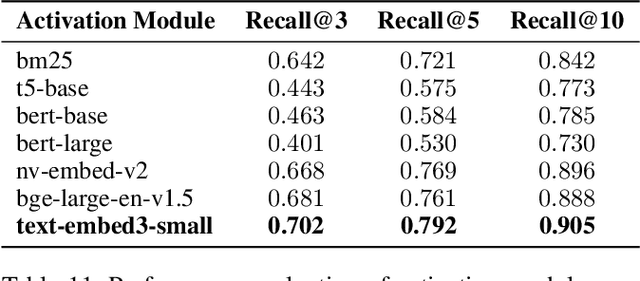
Existing Task-Oriented Dialogue (TOD) systems primarily focus on single-session dialogues, limiting their effectiveness in long-term memory augmentation. To address this challenge, we introduce a MS-TOD dataset, the first multi-session TOD dataset designed to retain long-term memory across sessions, enabling fewer turns and more efficient task completion. This defines a new benchmark task for evaluating long-term memory in multi-session TOD. Based on this new dataset, we propose a Memory-Active Policy (MAP) that improves multi-session dialogue efficiency through a two-stage approach. 1) Memory-Guided Dialogue Planning retrieves intent-aligned history, identifies key QA units via a memory judger, refines them by removing redundant questions, and generates responses based on the reconstructed memory. 2) Proactive Response Strategy detects and correct errors or omissions, ensuring efficient and accurate task completion. We evaluate MAP on MS-TOD dataset, focusing on response quality and effectiveness of the proactive strategy. Experiments on MS-TOD demonstrate that MAP significantly improves task success and turn efficiency in multi-session scenarios, while maintaining competitive performance on conventional single-session tasks.
Explicit and Implicit Representations in AI-based 3D Reconstruction for Radiology: A systematic literature review
Apr 15, 2025The demand for high-quality medical imaging in clinical practice and assisted diagnosis has made 3D reconstruction in radiological imaging a key research focus. Artificial intelligence (AI) has emerged as a promising approach to enhancing reconstruction accuracy while reducing acquisition and processing time, thereby minimizing patient radiation exposure and discomfort and ultimately benefiting clinical diagnosis. This review explores state-of-the-art AI-based 3D reconstruction algorithms in radiological imaging, categorizing them into explicit and implicit approaches based on their underlying principles. Explicit methods include point-based, volume-based, and Gaussian representations, while implicit methods encompass implicit prior embedding and neural radiance fields. Additionally, we examine commonly used evaluation metrics and benchmark datasets. Finally, we discuss the current state of development, key challenges, and future research directions in this evolving field. Our project available on: https://github.com/Bean-Young/AI4Med.
Rethinking Large-scale Dataset Compression: Shifting Focus From Labels to Images
Feb 10, 2025



Dataset distillation and dataset pruning are two prominent techniques for compressing datasets to improve computational and storage efficiency. Despite their overlapping objectives, these approaches are rarely compared directly. Even within each field, the evaluation protocols are inconsistent across various methods, which complicates fair comparisons and hinders reproducibility. Considering these limitations, we introduce in this paper a benchmark that equitably evaluates methodologies across both distillation and pruning literatures. Notably, our benchmark reveals that in the mainstream dataset distillation setting for large-scale datasets, which heavily rely on soft labels from pre-trained models, even randomly selected subsets can achieve surprisingly competitive performance. This finding suggests that an overemphasis on soft labels may be diverting attention from the intrinsic value of the image data, while also imposing additional burdens in terms of generation, storage, and application. To address these issues, we propose a new framework for dataset compression, termed Prune, Combine, and Augment (PCA), which focuses on leveraging image data exclusively, relies solely on hard labels for evaluation, and achieves state-of-the-art performance in this setup. By shifting the emphasis back to the images, our benchmark and PCA framework pave the way for more balanced and accessible techniques in dataset compression research. Our code is available at: https://github.com/ArmandXiao/Rethinking-Dataset-Compression
Swift Cross-Dataset Pruning: Enhancing Fine-Tuning Efficiency in Natural Language Understanding
Jan 05, 2025Dataset pruning aims to select a subset of a dataset for efficient model training. While data efficiency in natural language processing has primarily focused on within-corpus scenarios during model pre-training, efficient dataset pruning for task-specific fine-tuning across diverse datasets remains challenging due to variability in dataset sizes, data distributions, class imbalance and label spaces. Current cross-dataset pruning techniques for fine-tuning often rely on computationally expensive sample ranking processes, typically requiring full dataset training or reference models. We address this gap by proposing Swift Cross-Dataset Pruning (SCDP). Specifically, our approach uses TF-IDF embeddings with geometric median to rapidly evaluate sample importance. We then apply dataset size-adaptive pruning to ensure diversity: for smaller datasets, we retain samples far from the geometric median, while for larger ones, we employ distance-based stratified pruning. Experimental results on six diverse datasets demonstrate the effectiveness of our method, spanning various tasks and scales while significantly reducing computational resources. Source code is available at: https://github.com/he-y/NLP-Dataset-Pruning
Knowledge as a Breaking of Ergodicity
Dec 21, 2024We construct a thermodynamic potential that can guide training of a generative model defined on a set of binary degrees of freedom. We argue that upon reduction in description, so as to make the generative model computationally-manageable, the potential develops multiple minima. This is mirrored by the emergence of multiple minima in the free energy proper of the generative model itself. The variety of training samples that employ N binary degrees of freedom is ordinarily much lower than the size 2^N of the full phase space. The non-represented configurations, we argue, should be thought of as comprising a high-temperature phase separated by an extensive energy gap from the configurations composing the training set. Thus, training amounts to sampling a free energy surface in the form of a library of distinct bound states, each of which breaks ergodicity. The ergodicity breaking prevents escape into the near continuum of states comprising the high-temperature phase; thus it is necessary for proper functionality. It may however have the side effect of limiting access to patterns that were underrepresented in the training set. At the same time, the ergodicity breaking within the library complicates both learning and retrieval. As a remedy, one may concurrently employ multiple generative models -- up to one model per free energy minimum.
Bayesian Deep Learning Approach for Real-time Lane-based Arrival Curve Reconstruction at Intersection using License Plate Recognition Data
Nov 12, 2024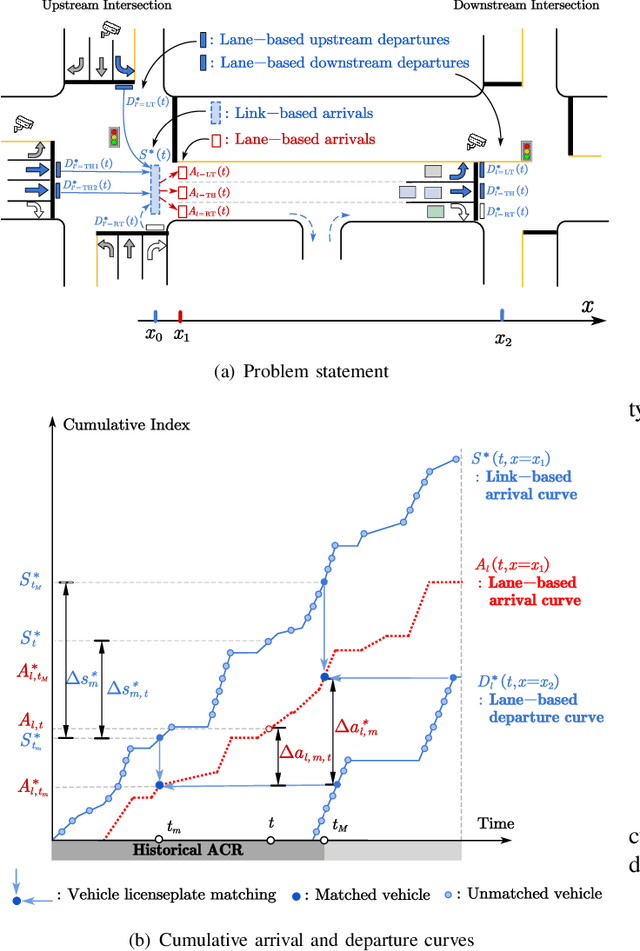
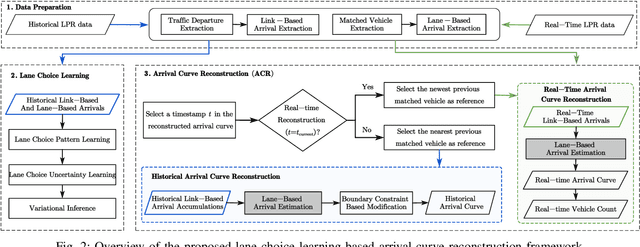
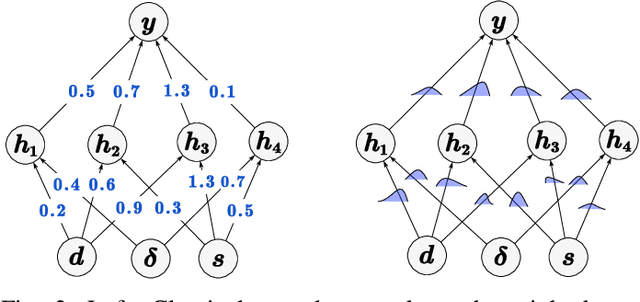
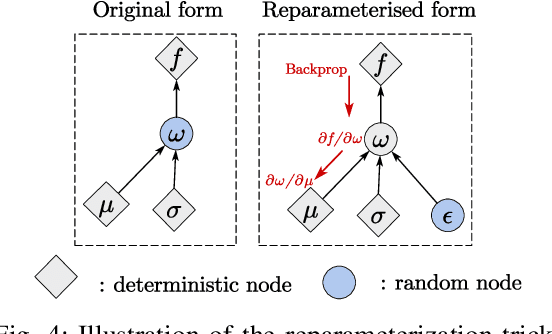
The acquisition of real-time and accurate traffic arrival information is of vital importance for proactive traffic control systems, especially in partially connected vehicle environments. License plate recognition (LPR) data that record both vehicle departures and identities are proven to be desirable in reconstructing lane-based arrival curves in previous works. Existing LPR databased methods are predominantly designed for reconstructing historical arrival curves. For real-time reconstruction of multi-lane urban roads, it is pivotal to determine the lane choice of real-time link-based arrivals, which has not been exploited in previous studies. In this study, we propose a Bayesian deep learning approach for real-time lane-based arrival curve reconstruction, in which the lane choice patterns and uncertainties of link-based arrivals are both characterized. Specifically, the learning process is designed to effectively capture the relationship between partially observed link-based arrivals and lane-based arrivals, which can be physically interpreted as lane choice proportion. Moreover, the lane choice uncertainties are characterized using Bayesian parameter inference techniques, minimizing arrival curve reconstruction uncertainties, especially in low LPR data matching rate conditions. Real-world experiment results conducted in multiple matching rate scenarios demonstrate the superiority and necessity of lane choice modeling in reconstructing arrival curves.
UTSRMorph: A Unified Transformer and Superresolution Network for Unsupervised Medical Image Registration
Oct 27, 2024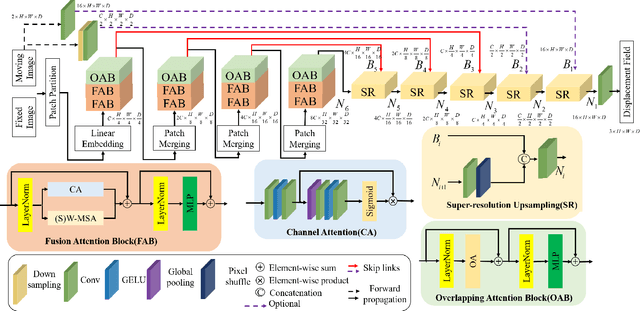
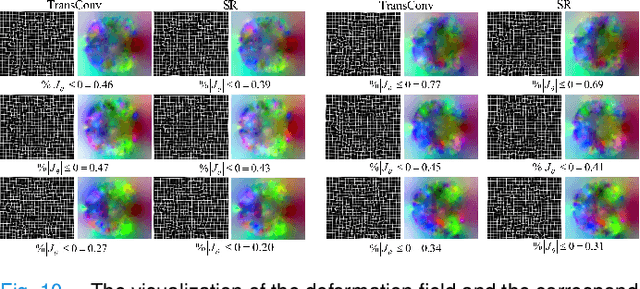

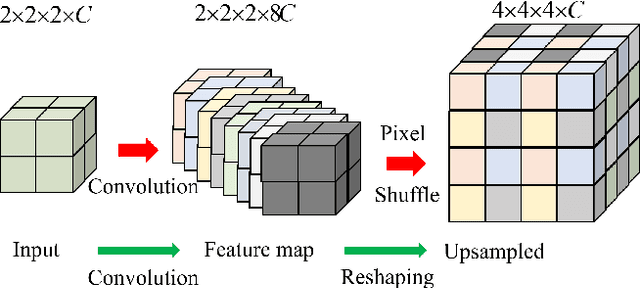
Complicated image registration is a key issue in medical image analysis, and deep learning-based methods have achieved better results than traditional methods. The methods include ConvNet-based and Transformer-based methods. Although ConvNets can effectively utilize local information to reduce redundancy via small neighborhood convolution, the limited receptive field results in the inability to capture global dependencies. Transformers can establish long-distance dependencies via a self-attention mechanism; however, the intense calculation of the relationships among all tokens leads to high redundancy. We propose a novel unsupervised image registration method named the unified Transformer and superresolution (UTSRMorph) network, which can enhance feature representation learning in the encoder and generate detailed displacement fields in the decoder to overcome these problems. We first propose a fusion attention block to integrate the advantages of ConvNets and Transformers, which inserts a ConvNet-based channel attention module into a multihead self-attention module. The overlapping attention block, a novel cross-attention method, uses overlapping windows to obtain abundant correlations with match information of a pair of images. Then, the blocks are flexibly stacked into a new powerful encoder. The decoder generation process of a high-resolution deformation displacement field from low-resolution features is considered as a superresolution process. Specifically, the superresolution module was employed to replace interpolation upsampling, which can overcome feature degradation. UTSRMorph was compared to state-of-the-art registration methods in the 3D brain MR (OASIS, IXI) and MR-CT datasets. The qualitative and quantitative results indicate that UTSRMorph achieves relatively better performance. The code and datasets are publicly available at https://github.com/Runshi-Zhang/UTSRMorph.
* 13pages,10 figures
Are Large-scale Soft Labels Necessary for Large-scale Dataset Distillation?
Oct 21, 2024



In ImageNet-condensation, the storage for auxiliary soft labels exceeds that of the condensed dataset by over 30 times. However, are large-scale soft labels necessary for large-scale dataset distillation? In this paper, we first discover that the high within-class similarity in condensed datasets necessitates the use of large-scale soft labels. This high within-class similarity can be attributed to the fact that previous methods use samples from different classes to construct a single batch for batch normalization (BN) matching. To reduce the within-class similarity, we introduce class-wise supervision during the image synthesizing process by batching the samples within classes, instead of across classes. As a result, we can increase within-class diversity and reduce the size of required soft labels. A key benefit of improved image diversity is that soft label compression can be achieved through simple random pruning, eliminating the need for complex rule-based strategies. Experiments validate our discoveries. For example, when condensing ImageNet-1K to 200 images per class, our approach compresses the required soft labels from 113 GB to 2.8 GB (40x compression) with a 2.6% performance gain. Code is available at: https://github.com/he-y/soft-label-pruning-for-dataset-distillation