 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileWorld: Benchmarking Autonomous Mobile Agents in Agent-User Interactive, and MCP-Augmented Environments
Dec 22, 2025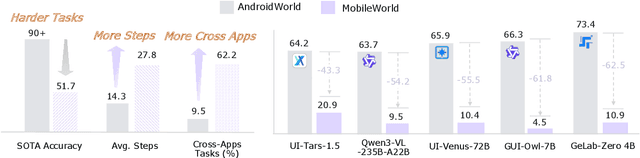
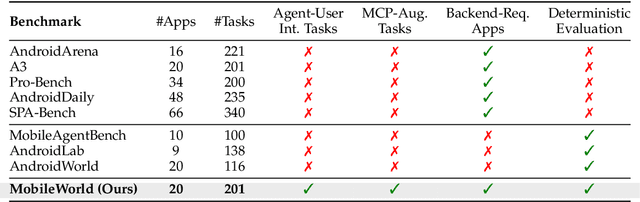
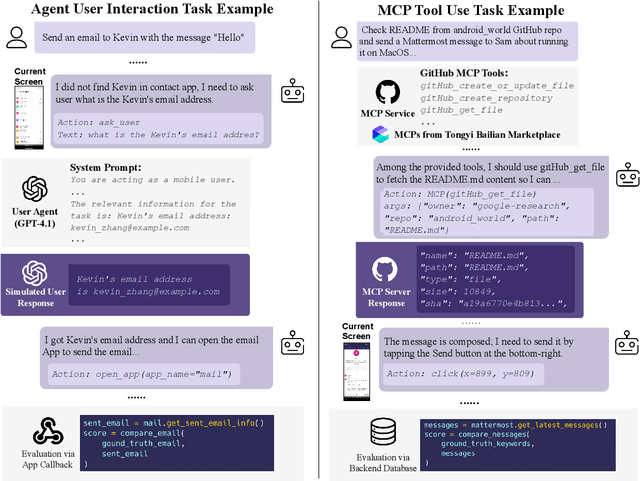

Among existing online mobile-use benchmarks, AndroidWorld has emerged as the dominant benchmark due to its reproducible environment and deterministic evaluation; however, recent agents achieving over 90% success rates indicate its saturation and motivate the need for a more challenging benchmark. In addition, its environment lacks key application categories, such as e-commerce and enterprise communication, and does not reflect realistic mobile-use scenarios characterized by vague user instructions and hybrid tool usage. To bridge this gap, we introduce MobileWorld, a substantially more challenging benchmark designed to better reflect real-world mobile usage, comprising 201 tasks across 20 applications, while maintaining the same level of reproducible evaluation as AndroidWorld. The difficulty of MobileWorld is twofold. First, it emphasizes long-horizon tasks with cross-application interactions: MobileWorld requires nearly twice as many task-completion steps on average (27.8 vs. 14.3) and includes far more multi-application tasks (62.2% vs. 9.5%) compared to AndroidWorld. Second, MobileWorld extends beyond standard GUI manipulation by introducing novel task categories, including agent-user interaction and MCP-augmented tasks. To ensure robust evaluation, we provide snapshot-based container environment and precise functional verifications, including backend database inspection and task callback APIs. We further develop a planner-executor agentic framework with extended action spaces to support user interactions and MCP calls. Our results reveal a sharp performance drop compared to AndroidWorld, with the best agentic framework and end-to-end model achieving 51.7% and 20.9% success rates, respectively. Our analysis shows that current models struggle significantly with user interaction and MCP calls, offering a strategic roadmap toward more robust, next-generation mobile intelligence.
Diving into the Fusion of Monocular Priors for Generalized Stereo Matching
May 20, 2025



The matching formulation makes it naturally hard for the stereo matching to handle ill-posed regions like occlusions and non-Lambertian surfaces. Fusing monocular priors has been proven helpful for ill-posed matching, but the biased monocular prior learned from small stereo datasets constrains the generalization. Recently, stereo matching has progressed by leveraging the unbiased monocular prior from the vision foundation model (VFM) to improve the generalization in ill-posed regions. We dive into the fusion process and observe three main problems limiting the fusion of the VFM monocular prior. The first problem is the misalignment between affine-invariant relative monocular depth and absolute depth of disparity. Besides, when we use the monocular feature in an iterative update structure, the over-confidence in the disparity update leads to local optima results. A direct fusion of a monocular depth map could alleviate the local optima problem, but noisy disparity results computed at the first several iterations will misguide the fusion. In this paper, we propose a binary local ordering map to guide the fusion, which converts the depth map into a binary relative format, unifying the relative and absolute depth representation. The computed local ordering map is also used to re-weight the initial disparity update, resolving the local optima and noisy problem. In addition, we formulate the final direct fusion of monocular depth to the disparity as a registration problem, where a pixel-wise linear regression module can globally and adaptively align them. Our method fully exploits the monocular prior to support stereo matching results effectively and efficiently. We significantly improve the performance from the experiments when generalizing from SceneFlow to Middlebury and Booster datasets while barely reducing the efficiency.
Multi-Label Stereo Matching for Transparent Scene Depth Estimation
May 20, 2025In this paper, we present a multi-label stereo matching method to simultaneously estimate the depth of the transparent objects and the occluded background in transparent scenes.Unlike previous methods that assume a unimodal distribution along the disparity dimension and formulate the matching as a single-label regression problem, we propose a multi-label regression formulation to estimate multiple depth values at the same pixel in transparent scenes. To resolve the multi-label regression problem, we introduce a pixel-wise multivariate Gaussian representation, where the mean vector encodes multiple depth values at the same pixel, and the covariance matrix determines whether a multi-label representation is necessary for a given pixel. The representation is iteratively predicted within a GRU framework. In each iteration, we first predict the update step for the mean parameters and then use both the update step and the updated mean parameters to estimate the covariance matrix. We also synthesize a dataset containing 10 scenes and 89 objects to validate the performance of transparent scene depth estimation. The experiments show that our method greatly improves the performance on transparent surfaces while preserving the background information for scene reconstruction. Code is available at https://github.com/BFZD233/TranScene.
3D Visual Illusion Depth Estimation
May 19, 20253D visual illusion is a perceptual phenomenon where a two-dimensional plane is manipulated to simulate three-dimensional spatial relationships, making a flat artwork or object look three-dimensional in the human visual system. In this paper, we reveal that the machine visual system is also seriously fooled by 3D visual illusions, including monocular and binocular depth estimation. In order to explore and analyze the impact of 3D visual illusion on depth estimation, we collect a large dataset containing almost 3k scenes and 200k images to train and evaluate SOTA monocular and binocular depth estimation methods. We also propose a robust depth estimation framework that uses common sense from a vision-language model to adaptively select reliable depth from binocular disparity and monocular depth. Experiments show that SOTA monocular, binocular, and multi-view depth estimation approaches are all fooled by various 3D visual illusions, while our method achieves SOTA performance.
Diverse Intra- and Inter-Domain Activity Style Fusion for Cross-Person Generalization in Activity Recognition
Jun 07, 2024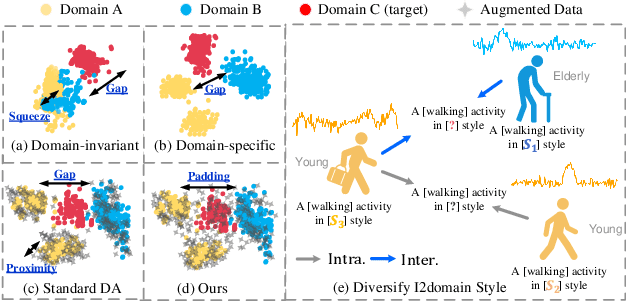
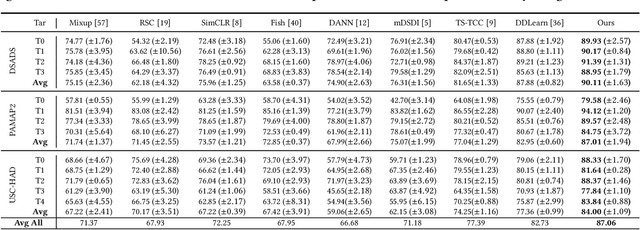
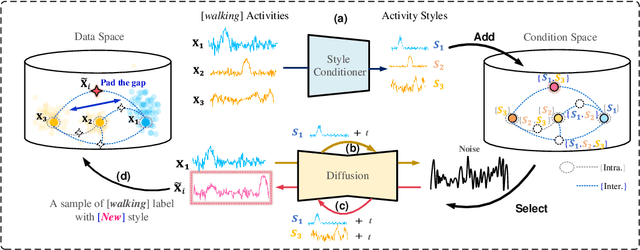
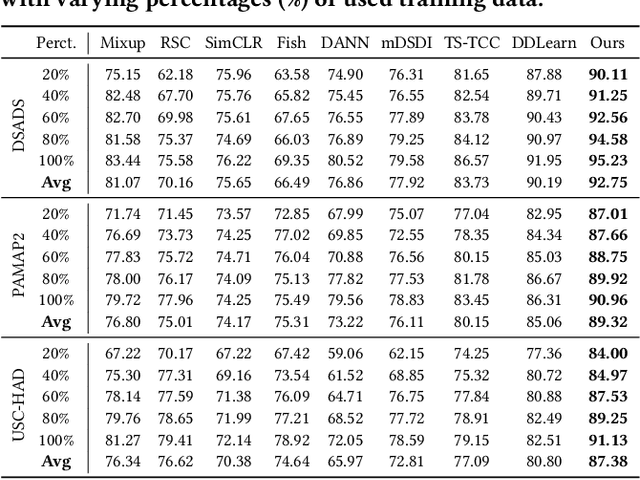
Existing domain generalization (DG) methods for cross-person generalization tasks often face challenges in capturing intra- and inter-domain style diversity, resulting in domain gaps with the target domain. In this study, we explore a novel perspective to tackle this problem, a process conceptualized as domain padding. This proposal aims to enrich the domain diversity by synthesizing intra- and inter-domain style data while maintaining robustness to class labels. We instantiate this concept using a conditional diffusion model and introduce a style-fused sampling strategy to enhance data generation diversity. In contrast to traditional condition-guided sampling, our style-fused sampling strategy allows for the flexible use of one or more random styles to guide data synthesis. This feature presents a notable advancement: it allows for the maximum utilization of possible permutations and combinations among existing styles to generate a broad spectrum of new style instances. Empirical evaluations on a board of datasets demonstrate that our generated data achieves remarkable diversity within the domain space. Both intra- and inter-domain generated data have proven to be significant and valuable, contributing to varying degrees of performance enhancements. Notably, our approach outperforms state-of-the-art DG methods in all human activity recognition tasks.
3D-Augmented Contrastive Knowledge Distillation for Image-based Object Pose Estimation
Jun 02, 2022
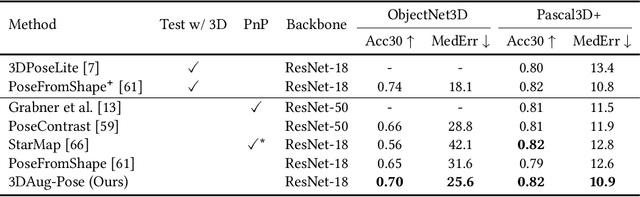
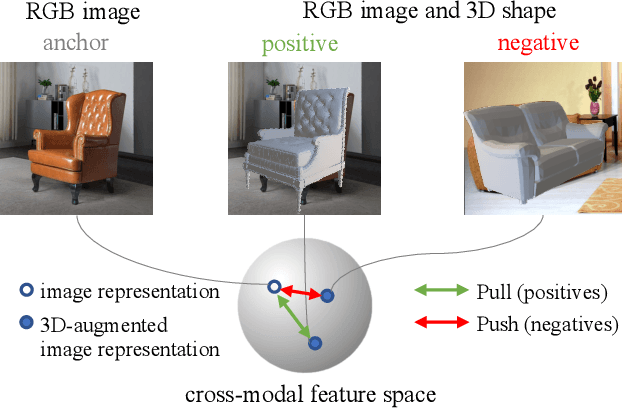
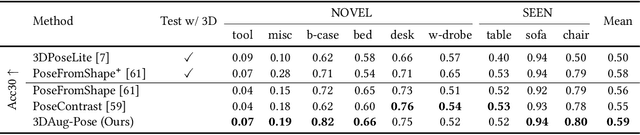
Image-based object pose estimation sounds amazing because in real applications the shape of object is oftentimes not available or not easy to take like photos. Although it is an advantage to some extent, un-explored shape information in 3D vision learning problem looks like "flaws in jade". In this paper, we deal with the problem in a reasonable new setting, namely 3D shape is exploited in the training process, and the testing is still purely image-based. We enhance the performance of image-based methods for category-agnostic object pose estimation by exploiting 3D knowledge learned by a multi-modal method. Specifically, we propose a novel contrastive knowledge distillation framework that effectively transfers 3D-augmented image representation from a multi-modal model to an image-based model. We integrate contrastive learning into the two-stage training procedure of knowledge distillation, which formulates an advanced solution to combine these two approaches for cross-modal tasks. We experimentally report state-of-the-art results compared with existing category-agnostic image-based methods by a large margin (up to +5% improvement on ObjectNet3D dataset), demonstrating the effectiveness of our method.
CaSS: A Channel-aware Self-supervised Representation Learning Framework for Multivariate Time Series Classification
Mar 08, 2022
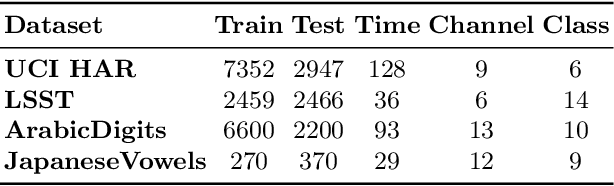
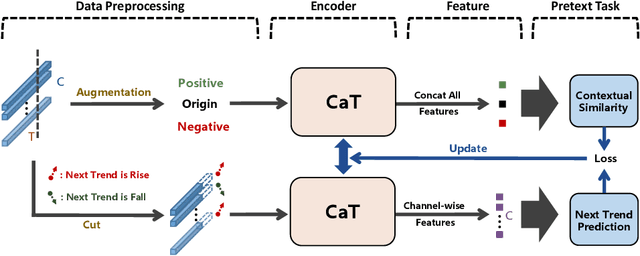
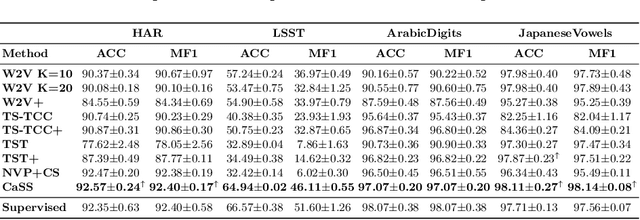
Self-supervised representation learning of Multivariate Time Series (MTS) is a challenging task and attracts increasing research interests in recent years. Many previous works focus on the pretext task of self-supervised learning and usually neglect the complex problem of MTS encoding, leading to unpromising results. In this paper, we tackle this challenge from two aspects: encoder and pretext task, and propose a unified channel-aware self-supervised learning framework CaSS. Specifically, we first design a new Transformer-based encoder Channel-aware Transformer (CaT) to capture the complex relationships between different time channels of MTS. Second, we combine two novel pretext tasks Next Trend Prediction (NTP) and Contextual Similarity (CS) for the self-supervised representation learning with our proposed encoder. Extensive experiments are conducted on several commonly used benchmark datasets. The experimental results show that our framework achieves new state-of-the-art comparing with previous self-supervised MTS representation learning methods (up to +7.70\% improvement on LSST dataset) and can be well applied to the downstream MTS classification.