 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeek-CAD: A Self-refined Generative Modeling for 3D Parametric CAD Using Local Inference via DeepSeek
May 23, 2025The advent of Computer-Aided Design (CAD) generative modeling will significantly transform the design of industrial products. The recent research endeavor has extended into the realm of Large Language Models (LLMs). In contrast to fine-tuning methods, training-free approaches typically utilize the advanced closed-source LLMs, thereby offering enhanced flexibility and efficiency in the development of AI agents for generating CAD parametric models. However, the substantial cost and limitations of local deployment of the top-tier closed-source LLMs pose challenges in practical applications. The Seek-CAD is the pioneer exploration of locally deployed open-source inference LLM DeepSeek-R1 for CAD parametric model generation with a training-free methodology. This study is the first investigation to incorporate both visual and Chain-of-Thought (CoT) feedback within the self-refinement mechanism for generating CAD models. Specifically, the initial generated parametric CAD model is rendered into a sequence of step-wise perspective images, which are subsequently processed by a Vision Language Model (VLM) alongside the corresponding CoTs derived from DeepSeek-R1 to assess the CAD model generation. Then, the feedback is utilized by DeepSeek-R1 to refine the initial generated model for the next round of generation. Moreover, we present an innovative 3D CAD model dataset structured around the SSR (Sketch, Sketch-based feature, and Refinements) triple design paradigm. This dataset encompasses a wide range of CAD commands, thereby aligning effectively with industrial application requirements and proving suitable for the generation of LLMs. Extensive experiments validate the effectiveness of Seek-CAD under various metrics.
CAD-Llama: Leveraging Large Language Models for Computer-Aided Design Parametric 3D Model Generation
May 07, 2025Recently, Large Language Models (LLMs) have achieved significant success, prompting increased interest in expanding their generative capabilities beyond general text into domain-specific areas. This study investigates the generation of parametric sequences for computer-aided design (CAD) models using LLMs. This endeavor represents an initial step towards creating parametric 3D shapes with LLMs, as CAD model parameters directly correlate with shapes in three-dimensional space. Despite the formidable generative capacities of LLMs, this task remains challenging, as these models neither encounter parametric sequences during their pretraining phase nor possess direct awareness of 3D structures. To address this, we present CAD-Llama, a framework designed to enhance pretrained LLMs for generating parametric 3D CAD models. Specifically, we develop a hierarchical annotation pipeline and a code-like format to translate parametric 3D CAD command sequences into Structured Parametric CAD Code (SPCC), incorporating hierarchical semantic descriptions. Furthermore, we propose an adaptive pretraining approach utilizing SPCC, followed by an instruction tuning process aligned with CAD-specific guidelines. This methodology aims to equip LLMs with the spatial knowledge inherent in parametric sequences. Experimental results demonstrate that our framework significantly outperforms prior autoregressive methods and existing LLM baselines.
PanoSwin: a Pano-style Swin Transformer for Panorama Understanding
Aug 28, 2023



In panorama understanding, the widely used equirectangular projection (ERP) entails boundary discontinuity and spatial distortion. It severely deteriorates the conventional CNNs and vision Transformers on panoramas. In this paper, we propose a simple yet effective architecture named PanoSwin to learn panorama representations with ERP. To deal with the challenges brought by equirectangular projection, we explore a pano-style shift windowing scheme and novel pitch attention to address the boundary discontinuity and the spatial distortion, respectively. Besides, based on spherical distance and Cartesian coordinates, we adapt absolute positional embeddings and relative positional biases for panoramas to enhance panoramic geometry information. Realizing that planar image understanding might share some common knowledge with panorama understanding, we devise a novel two-stage learning framework to facilitate knowledge transfer from the planar images to panoramas. We conduct experiments against the state-of-the-art on various panoramic tasks, i.e., panoramic object detection, panoramic classification, and panoramic layout estimation. The experimental results demonstrate the effectiveness of PanoSwin in panorama understanding.
Did the Models Understand Documents? Benchmarking Models for Language Understanding in Document-Level Relation Extraction
Jun 20, 2023



Document-level relation extraction (DocRE) attracts more research interest recently. While models achieve consistent performance gains in DocRE, their underlying decision rules are still understudied: Do they make the right predictions according to rationales? In this paper, we take the first step toward answering this question and then introduce a new perspective on comprehensively evaluating a model. Specifically, we first conduct annotations to provide the rationales considered by humans in DocRE. Then, we conduct investigations and reveal the fact that: In contrast to humans, the representative state-of-the-art (SOTA) models in DocRE exhibit different decision rules. Through our proposed RE-specific attacks, we next demonstrate that the significant discrepancy in decision rules between models and humans severely damages the robustness of models and renders them inapplicable to real-world RE scenarios. After that, we introduce mean average precision (MAP) to evaluate the understanding and reasoning capabilities of models. According to the extensive experimental results, we finally appeal to future work to consider evaluating both performance and the understanding ability of models for the development of their applications. We make our annotations and code publicly available.
Few-shot Single-view 3D Reconstruction with Memory Prior Contrastive Network
Jul 30, 2022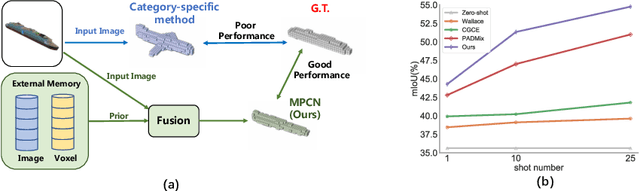
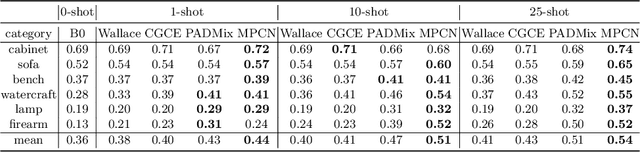
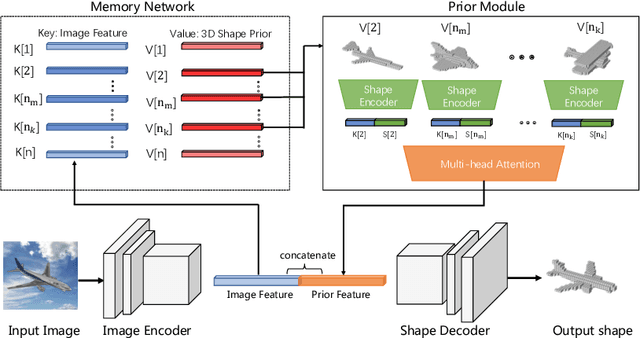
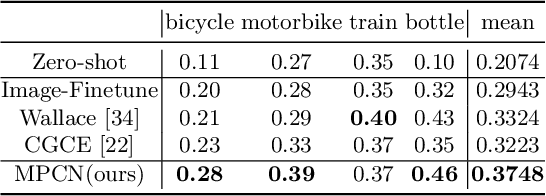
3D reconstruction of novel categories based on few-shot learning is appealing in real-world applications and attracts increasing research interests. Previous approaches mainly focus on how to design shape prior models for different categories. Their performance on unseen categories is not very competitive. In this paper, we present a Memory Prior Contrastive Network (MPCN) that can store shape prior knowledge in a few-shot learning based 3D reconstruction framework. With the shape memory, a multi-head attention module is proposed to capture different parts of a candidate shape prior and fuse these parts together to guide 3D reconstruction of novel categories. Besides, we introduce a 3D-aware contrastive learning method, which can not only complement the retrieval accuracy of memory network, but also better organize image features for downstream tasks. Compared with previous few-shot 3D reconstruction methods, MPCN can handle the inter-class variability without category annotations. Experimental results on a benchmark synthetic dataset and the Pascal3D+ real-world dataset show that our model outperforms the current state-of-the-art methods significantly.
3D-Augmented Contrastive Knowledge Distillation for Image-based Object Pose Estimation
Jun 02, 2022
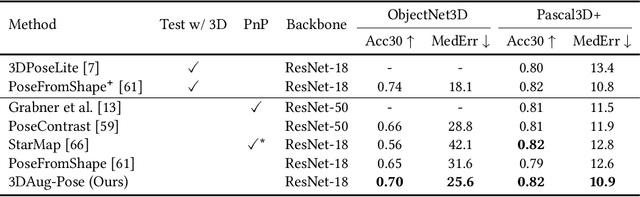
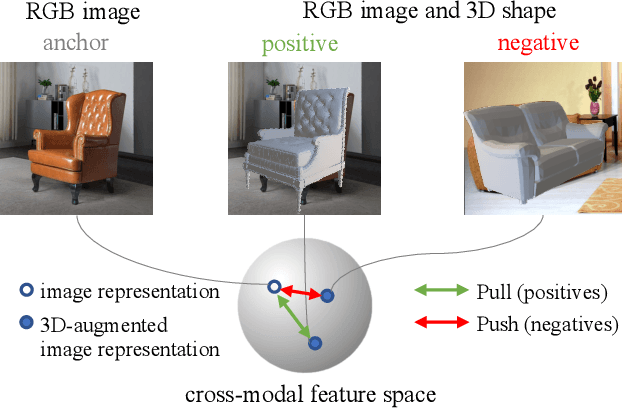
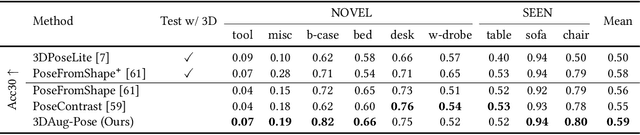
Image-based object pose estimation sounds amazing because in real applications the shape of object is oftentimes not available or not easy to take like photos. Although it is an advantage to some extent, un-explored shape information in 3D vision learning problem looks like "flaws in jade". In this paper, we deal with the problem in a reasonable new setting, namely 3D shape is exploited in the training process, and the testing is still purely image-based. We enhance the performance of image-based methods for category-agnostic object pose estimation by exploiting 3D knowledge learned by a multi-modal method. Specifically, we propose a novel contrastive knowledge distillation framework that effectively transfers 3D-augmented image representation from a multi-modal model to an image-based model. We integrate contrastive learning into the two-stage training procedure of knowledge distillation, which formulates an advanced solution to combine these two approaches for cross-modal tasks. We experimentally report state-of-the-art results compared with existing category-agnostic image-based methods by a large margin (up to +5% improvement on ObjectNet3D dataset), demonstrating the effectiveness of our method.
CaSS: A Channel-aware Self-supervised Representation Learning Framework for Multivariate Time Series Classification
Mar 08, 2022
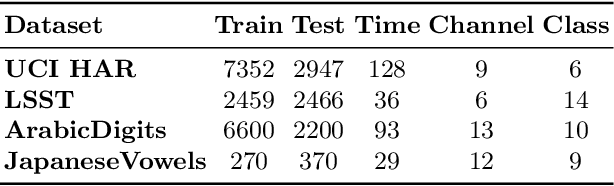
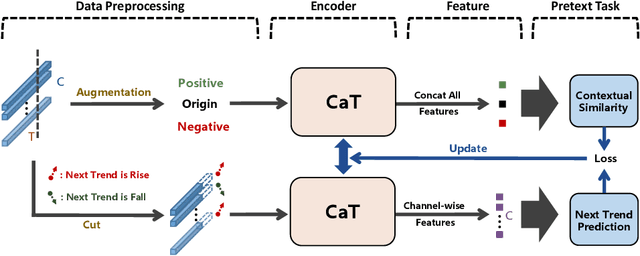
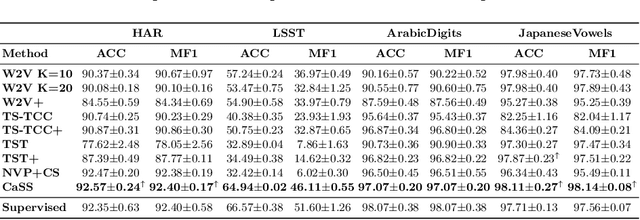
Self-supervised representation learning of Multivariate Time Series (MTS) is a challenging task and attracts increasing research interests in recent years. Many previous works focus on the pretext task of self-supervised learning and usually neglect the complex problem of MTS encoding, leading to unpromising results. In this paper, we tackle this challenge from two aspects: encoder and pretext task, and propose a unified channel-aware self-supervised learning framework CaSS. Specifically, we first design a new Transformer-based encoder Channel-aware Transformer (CaT) to capture the complex relationships between different time channels of MTS. Second, we combine two novel pretext tasks Next Trend Prediction (NTP) and Contextual Similarity (CS) for the self-supervised representation learning with our proposed encoder. Extensive experiments are conducted on several commonly used benchmark datasets. The experimental results show that our framework achieves new state-of-the-art comparing with previous self-supervised MTS representation learning methods (up to +7.70\% improvement on LSST dataset) and can be well applied to the downstream MTS classification.
Aerial-PASS: Panoramic Annular Scene Segmentation in Drone Videos
May 15, 2021

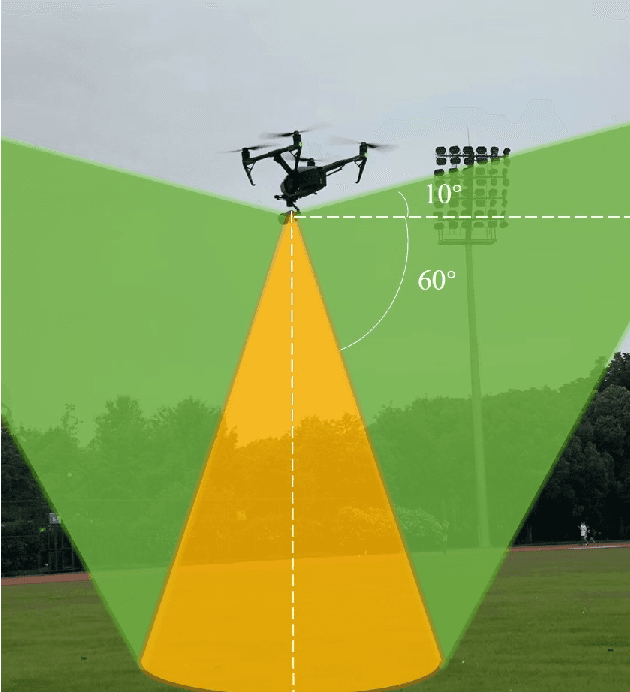

Aerial pixel-wise scene perception of the surrounding environment is an important task for UAVs (Unmanned Aerial Vehicles). Previous research works mainly adopt conventional pinhole cameras or fisheye cameras as the imaging device. However, these imaging systems cannot achieve large Field of View (FoV), small size, and lightweight at the same time. To this end, we design a UAV system with a Panoramic Annular Lens (PAL), which has the characteristics of small size, low weight, and a 360-degree annular FoV. A lightweight panoramic annular semantic segmentation neural network model is designed to achieve high-accuracy and real-time scene parsing. In addition, we present the first drone-perspective panoramic scene segmentation dataset Aerial-PASS, with annotated labels of track, field, and others. A comprehensive variety of experiments shows that the designed system performs satisfactorily in aerial panoramic scene parsing. In particular, our proposed model strikes an excellent trade-off between segmentation performance and inference speed suitable, validated on both public street-scene and our established aerial-scene datasets.