 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere to Touch, How to Contact: Hierarchical RL-MPC Framework for Geometry-Aware Long-Horizon Dexterous Manipulation
Jan 16, 2026A key challenge in contact-rich dexterous manipulation is the need to jointly reason over geometry, kinematic constraints, and intricate, nonsmooth contact dynamics. End-to-end visuomotor policies bypass this structure, but often require large amounts of data, transfer poorly from simulation to reality, and generalize weakly across tasks/embodiments. We address those limitations by leveraging a simple insight: dexterous manipulation is inherently hierarchical - at a high level, a robot decides where to touch (geometry) and move the object (kinematics); at a low level it determines how to realize that plan through contact dynamics. Building on this insight, we propose a hierarchical RL--MPC framework in which a high-level reinforcement learning (RL) policy predicts a contact intention, a novel object-centric interface that specifies (i) an object-surface contact location and (ii) a post-contact object-level subgoal pose. Conditioned on this contact intention, a low-level contact-implicit model predictive control (MPC) optimizes local contact modes and replans with contact dynamics to generate robot actions that robustly drive the object toward each subgoal. We evaluate the framework on non-prehensile tasks, including geometry-generalized pushing and object 3D reorientation. It achieves near-100% success with substantially reduced data (10x less than end-to-end baselines), highly robust performance, and zero-shot sim-to-real transfer.
Disentangling Granularity: An Implicit Inductive Bias in Factorized VAEs
May 30, 2025Despite the success in learning semantically meaningful, unsupervised disentangled representations, variational autoencoders (VAEs) and their variants face a fundamental theoretical challenge: substantial evidence indicates that unsupervised disentanglement is unattainable without implicit inductive bias, yet such bias remains elusive. In this work, we focus on exploring the implicit inductive bias that drive disentanglement in VAEs with factorization priors. By analyzing the total correlation in \b{eta}-TCVAE, we uncover a crucial implicit inductive bias called disentangling granularity, which leads to the discovery of an interesting "V"-shaped optimal Evidence Lower Bound (ELBO) trajectory within the parameter space. This finding is validated through over 100K experiments using factorized VAEs and our newly proposed model, \b{eta}-STCVAE. Notably, experimental results reveal that conventional factorized VAEs, constrained by fixed disentangling granularity, inherently tend to disentangle low-complexity feature. Whereas, appropriately tuning disentangling granularity, as enabled by \b{eta}-STCVAE, broadens the range of disentangled representations, allowing for the disentanglement of high-complexity features. Our findings unveil that disentangling granularity as an implicit inductive bias in factorized VAEs influence both disentanglement performance and the inference of the ELBO, offering fresh insights into the interpretability and inherent biases of VAEs.
IIKL: Isometric Immersion Kernel Learning with Riemannian Manifold for Geometric Preservation
May 07, 2025Geometric representation learning in preserving the intrinsic geometric and topological properties for discrete non-Euclidean data is crucial in scientific applications. Previous research generally mapped non-Euclidean discrete data into Euclidean space during representation learning, which may lead to the loss of some critical geometric information. In this paper, we propose a novel Isometric Immersion Kernel Learning (IIKL) method to build Riemannian manifold and isometrically induce Riemannian metric from discrete non-Euclidean data. We prove that Isometric immersion is equivalent to the kernel function in the tangent bundle on the manifold, which explicitly guarantees the invariance of the inner product between vectors in the arbitrary tangent space throughout the learning process, thus maintaining the geometric structure of the original data. Moreover, a novel parameterized learning model based on IIKL is introduced, and an alternating training method for this model is derived using Maximum Likelihood Estimation (MLE), ensuring efficient convergence. Experimental results proved that using the learned Riemannian manifold and its metric, our model preserved the intrinsic geometric representation of data in both 3D and high-dimensional datasets successfully, and significantly improved the accuracy of downstream tasks, such as data reconstruction and classification. It is showed that our method could reduce the inner product invariant loss by more than 90% compared to state-of-the-art (SOTA) methods, also achieved an average 40% improvement in downstream reconstruction accuracy and a 90% reduction in error for geometric metrics involving isometric and conformal.
Data driven approach towards more efficient Newton-Raphson power flow calculation for distribution grids
Apr 15, 2025Power flow (PF) calculations are fundamental to power system analysis to ensure stable and reliable grid operation. The Newton-Raphson (NR) method is commonly used for PF analysis due to its rapid convergence when initialized properly. However, as power grids operate closer to their capacity limits, ill-conditioned cases and convergence issues pose significant challenges. This work, therefore, addresses these challenges by proposing strategies to improve NR initialization, hence minimizing iterations and avoiding divergence. We explore three approaches: (i) an analytical method that estimates the basin of attraction using mathematical bounds on voltages, (ii) Two data-driven models leveraging supervised learning or physics-informed neural networks (PINNs) to predict optimal initial guesses, and (iii) a reinforcement learning (RL) approach that incrementally adjusts voltages to accelerate convergence. These methods are tested on benchmark systems. This research is particularly relevant for modern power systems, where high penetration of renewables and decentralized generation require robust and scalable PF solutions. In experiments, all three proposed methods demonstrate a strong ability to provide an initial guess for Newton-Raphson method to converge with fewer steps. The findings provide a pathway for more efficient real-time grid operations, which, in turn, support the transition toward smarter and more resilient electricity networks.
Probabilistic QoS Metric Forecasting in Delay-Tolerant Networks Using Conditional Diffusion Models on Latent Dynamics
Apr 09, 2025



Active QoS metric prediction, commonly employed in the maintenance and operation of DTN, could enhance network performance regarding latency, throughput, energy consumption, and dependability. Naturally formulated as a multivariate time series forecasting problem, it attracts substantial research efforts. Traditional mean regression methods for time series forecasting cannot capture the data complexity adequately, resulting in deteriorated performance in operational tasks in DTNs such as routing. This paper formulates the prediction of QoS metrics in DTN as a probabilistic forecasting problem on multivariate time series, where one could quantify the uncertainty of forecasts by characterizing the distribution of these samples. The proposed approach hires diffusion models and incorporates the latent temporal dynamics of non-stationary and multi-mode data into them. Extensive experiments demonstrate the efficacy of the proposed approach by showing that it outperforms the popular probabilistic time series forecasting methods.
V-HOP: Visuo-Haptic 6D Object Pose Tracking
Feb 24, 2025Humans naturally integrate vision and haptics for robust object perception during manipulation. The loss of either modality significantly degrades performance. Inspired by this multisensory integration, prior object pose estimation research has attempted to combine visual and haptic/tactile feedback. Although these works demonstrate improvements in controlled environments or synthetic datasets, they often underperform vision-only approaches in real-world settings due to poor generalization across diverse grippers, sensor layouts, or sim-to-real environments. Furthermore, they typically estimate the object pose for each frame independently, resulting in less coherent tracking over sequences in real-world deployments. To address these limitations, we introduce a novel unified haptic representation that effectively handles multiple gripper embodiments. Building on this representation, we introduce a new visuo-haptic transformer-based object pose tracker that seamlessly integrates visual and haptic input. We validate our framework in our dataset and the Feelsight dataset, demonstrating significant performance improvement on challenging sequences. Notably, our method achieves superior generalization and robustness across novel embodiments, objects, and sensor types (both taxel-based and vision-based tactile sensors). In real-world experiments, we demonstrate that our approach outperforms state-of-the-art visual trackers by a large margin. We further show that we can achieve precise manipulation tasks by incorporating our real-time object tracking result into motion plans, underscoring the advantages of visuo-haptic perception. Our model and dataset will be made open source upon acceptance of the paper. Project website: https://lhy.xyz/projects/v-hop/
RobotFingerPrint: Unified Gripper Coordinate Space for Multi-Gripper Grasp Synthesis
Sep 22, 2024



We introduce a novel representation named as the unified gripper coordinate space for grasp synthesis of multiple grippers. The space is a 2D surface of a sphere in 3D using longitude and latitude as its coordinates, and it is shared for all robotic grippers. We propose a new algorithm to map the palm surface of a gripper into the unified gripper coordinate space, and design a conditional variational autoencoder to predict the unified gripper coordinates given an input object. The predicted unified gripper coordinates establish correspondences between the gripper and the object, which can be used in an optimization problem to solve the grasp pose and the finger joints for grasp synthesis. We demonstrate that using the unified gripper coordinate space improves the success rate and diversity in the grasp synthesis of multiple grippers.
Continual Distillation Learning
Jul 18, 2024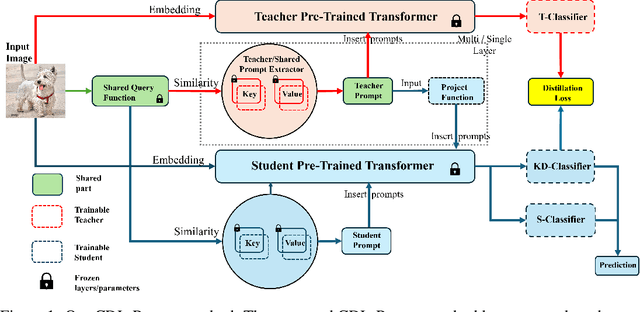



We study the problem of Continual Distillation Learning (CDL) that considers Knowledge Distillation (KD) in the Continual Learning (CL) setup. A teacher model and a student model need to learn a sequence of tasks, and the knowledge of the teacher model will be distilled to the student to improve the student model. We introduce a novel method named CDL-Prompt that utilizes prompt-based continual learning models to build the teacher-student model. We investigate how to utilize the prompts of the teacher model in the student model for knowledge distillation, and propose an attention-based prompt mapping scheme to use the teacher prompts for the student. We demonstrate that our method can be applied to different prompt-based continual learning models such as L2P, DualPrompt and CODA-Prompt to improve their performance using powerful teacher models. Although recent CL methods focus on prompt learning, we show that our method can be utilized to build efficient CL models using prompt-based knowledge distillation.
HO-Cap: A Capture System and Dataset for 3D Reconstruction and Pose Tracking of Hand-Object Interaction
Jun 10, 2024



We introduce a data capture system and a new dataset named HO-Cap that can be used to study 3D reconstruction and pose tracking of hands and objects in videos. The capture system uses multiple RGB-D cameras and a HoloLens headset for data collection, avoiding the use of expensive 3D scanners or mocap systems. We propose a semi-automatic method to obtain annotations of shape and pose of hands and objects in the collected videos, which significantly reduces the required annotation time compared to manual labeling. With this system, we captured a video dataset of humans using objects to perform different tasks, as well as simple pick-and-place and handover of an object from one hand to the other, which can be used as human demonstrations for embodied AI and robot manipulation research. Our data capture setup and annotation framework can be used by the community to reconstruct 3D shapes of objects and human hands and track their poses in videos.
Adapting Pre-Trained Vision Models for Novel Instance Detection and Segmentation
May 28, 2024



Novel Instance Detection and Segmentation (NIDS) aims at detecting and segmenting novel object instances given a few examples of each instance. We propose a unified framework (NIDS-Net) comprising object proposal generation, embedding creation for both instance templates and proposal regions, and embedding matching for instance label assignment. Leveraging recent advancements in large vision methods, we utilize the Grounding DINO and Segment Anything Model (SAM) to obtain object proposals with accurate bounding boxes and masks. Central to our approach is the generation of high-quality instance embeddings. We utilize foreground feature averages of patch embeddings from the DINOv2 ViT backbone, followed by refinement through a weight adapter mechanism that we introduce. We show experimentally that our weight adapter can adjust the embeddings locally within their feature space and effectively limit overfitting. This methodology enables a straightforward matching strategy, resulting in significant performance gains. Our framework surpasses current state-of-the-art methods, demonstrating notable improvements of 22.3, 46.2, 10.3, and 24.0 in average precision (AP) across four detection datasets. In instance segmentation tasks on seven core datasets of the BOP challenge, our method outperforms the top RGB methods by 3.6 AP and remains competitive with the best RGB-D method. Code is available at: https://github.com/YoungSean/NIDS-Net