 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelliCardiac: An Intelligent Platform for Cardiac Image Segmentation and Classification
May 08, 2025Precise and effective processing of cardiac imaging data is critical for the identification and management of the cardiovascular diseases. We introduce IntelliCardiac, a comprehensive, web-based medical image processing platform for the automatic segmentation of 4D cardiac images and disease classification, utilizing an AI model trained on the publicly accessible ACDC dataset. The system, intended for patients, cardiologists, and healthcare professionals, offers an intuitive interface and uses deep learning models to identify essential heart structures and categorize cardiac diseases. The system supports analysis of both the right and left ventricles as well as myocardium, and then classifies patient's cardiac images into five diagnostic categories: dilated cardiomyopathy, myocardial infarction, hypertrophic cardiomyopathy, right ventricular abnormality, and no disease. IntelliCardiac combines a deep learning-based segmentation model with a two-step classification pipeline. The segmentation module gains an overall accuracy of 92.6%. The classification module, trained on characteristics taken from segmented heart structures, achieves 98% accuracy in five categories. These results exceed the performance of the existing state-of-the-art methods that integrate both segmentation and classification models. IntelliCardiac, which supports real-time visualization, workflow integration, and AI-assisted diagnostics, has great potential as a scalable, accurate tool for clinical decision assistance in cardiac imaging and diagnosis.
RobotFingerPrint: Unified Gripper Coordinate Space for Multi-Gripper Grasp Synthesis
Sep 22, 2024



We introduce a novel representation named as the unified gripper coordinate space for grasp synthesis of multiple grippers. The space is a 2D surface of a sphere in 3D using longitude and latitude as its coordinates, and it is shared for all robotic grippers. We propose a new algorithm to map the palm surface of a gripper into the unified gripper coordinate space, and design a conditional variational autoencoder to predict the unified gripper coordinates given an input object. The predicted unified gripper coordinates establish correspondences between the gripper and the object, which can be used in an optimization problem to solve the grasp pose and the finger joints for grasp synthesis. We demonstrate that using the unified gripper coordinate space improves the success rate and diversity in the grasp synthesis of multiple grippers.
MultiGripperGrasp: A Dataset for Robotic Grasping from Parallel Jaw Grippers to Dexterous Hands
Mar 14, 2024



We introduce a large-scale dataset named MultiGripperGrasp for robotic grasping. Our dataset contains 30.4M grasps from 11 grippers for 345 objects. These grippers range from two-finger grippers to five-finger grippers, including a human hand. All grasps in the dataset are verified in Isaac Sim to classify them as successful and unsuccessful grasps. Additionally, the object fall-off time for each grasp is recorded as a grasp quality measurement. Furthermore, the grippers in our dataset are aligned according to the orientation and position of their palms, allowing us to transfer grasps from one gripper to another. The grasp transfer significantly increases the number of successful grasps for each gripper in the dataset. Our dataset is useful to study generalized grasp planning and grasp transfer across different grippers.
SCENEREPLICA: Benchmarking Real-World Robot Manipulation by Creating Reproducible Scenes
Jun 27, 2023
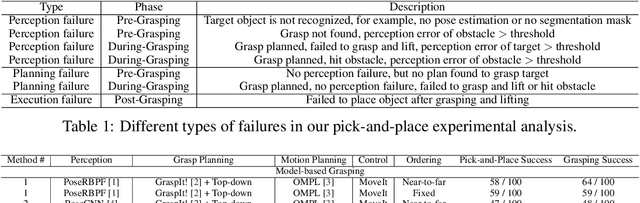
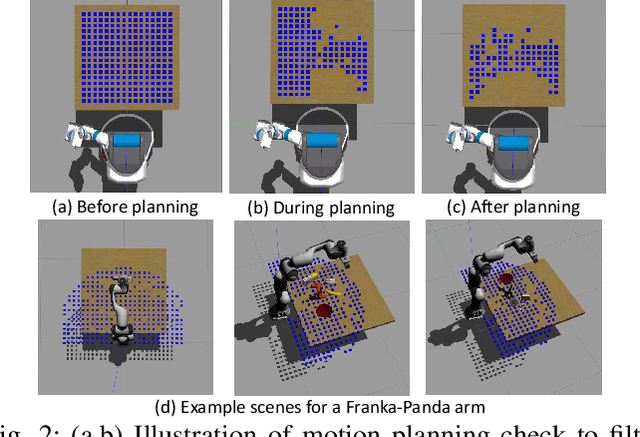
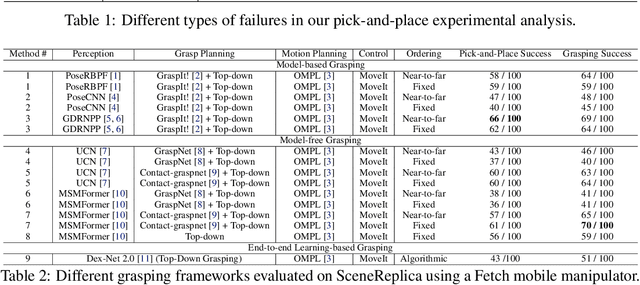
We present a new reproducible benchmark for evaluating robot manipulation in the real world, specifically focusing on pick-and-place. Our benchmark uses the YCB objects, a commonly used dataset in the robotics community, to ensure that our results are comparable to other studies. Additionally, the benchmark is designed to be easily reproducible in the real world, making it accessible to researchers and practitioners. We also provide our experimental results and analyzes for model-based and model-free 6D robotic grasping on the benchmark, where representative algorithms are evaluated for object perception, grasping planning, and motion planning. We believe that our benchmark will be a valuable tool for advancing the field of robot manipulation. By providing a standardized evaluation framework, researchers can more easily compare different techniques and algorithms, leading to faster progress in developing robot manipulation methods.
NeuralGrasps: Learning Implicit Representations for Grasps of Multiple Robotic Hands
Jul 06, 2022
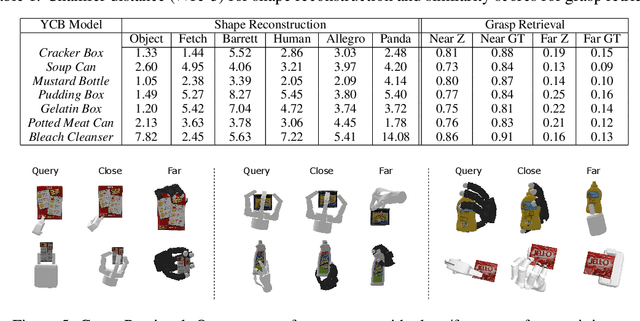
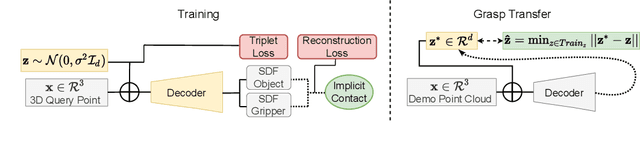
We introduce a neural implicit representation for grasps of objects from multiple robotic hands. Different grasps across multiple robotic hands are encoded into a shared latent space. Each latent vector is learned to decode to the 3D shape of an object and the 3D shape of a robotic hand in a grasping pose in terms of the signed distance functions of the two 3D shapes. In addition, the distance metric in the latent space is learned to preserve the similarity between grasps across different robotic hands, where the similarity of grasps is defined according to contact regions of the robotic hands. This property enables our method to transfer grasps between different grippers including a human hand, and grasp transfer has the potential to share grasping skills between robots and enable robots to learn grasping skills from humans. Furthermore, the encoded signed distance functions of objects and grasps in our implicit representation can be used for 6D object pose estimation with grasping contact optimization from partial point clouds, which enables robotic grasping in the real world.
Core-set Selection Using Metrics-based Explanations (CSUME) for multiclass ECG
May 28, 2022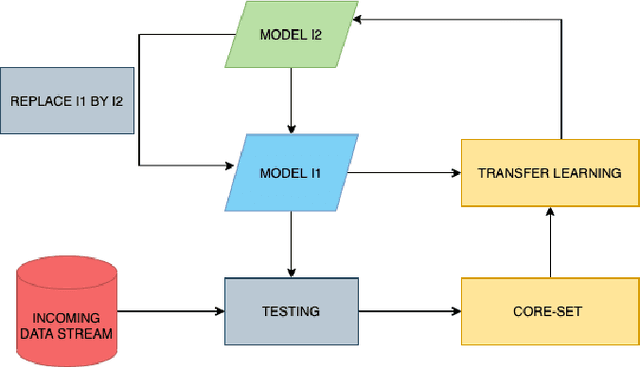
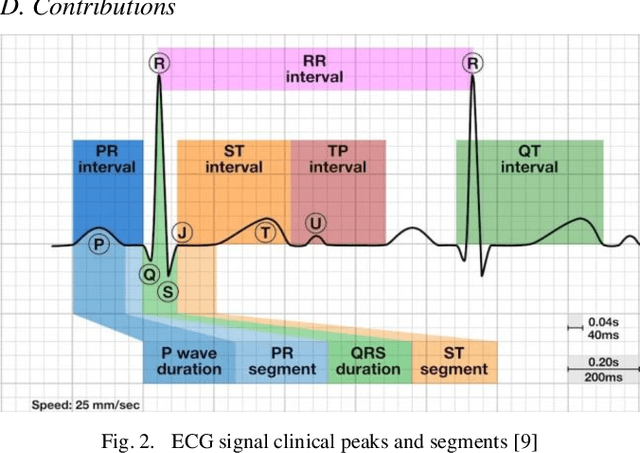
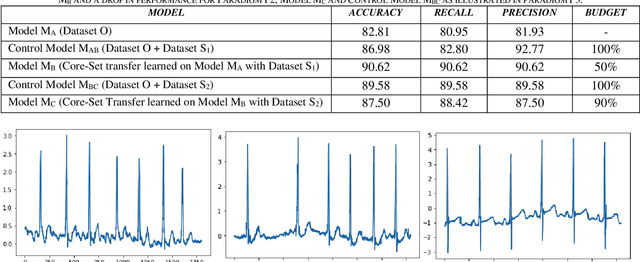
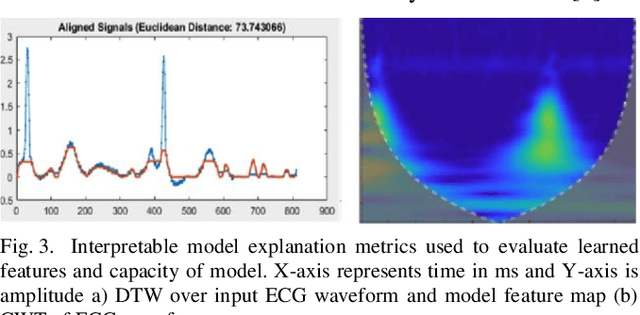
The adoption of deep learning-based healthcare decision support systems such as the detection of irregular cardiac rhythm is hindered by challenges such as lack of access to quality data and the high costs associated with the collection and annotation of data. The collection and processing of large volumes of healthcare data is a continuous process. The performance of data-hungry Deep Learning models (DL) is highly dependent on the quantity and quality of the data. While the need for data quantity has been established through research adequately, we show how a selection of good quality data improves deep learning model performance. In this work, we take Electrocardiogram (ECG) data as a case study and propose a model performance improvement methodology for algorithm developers, that selects the most informative data samples from incoming streams of multi-class ECG data. Our Core-Set selection methodology uses metrics-based explanations to select the most informative ECG data samples. This also provides an understanding (for algorithm developers) as to why a sample was selected as more informative over others for the improvement of deep learning model performance. Our experimental results show a 9.67% and 8.69% precision and recall improvement with a significant training data volume reduction of 50%. Additionally, our proposed methodology asserts the quality and annotation of ECG samples from incoming data streams. It allows automatic detection of individual data samples that do not contribute to model learning thus minimizing possible negative effects on model performance. We further discuss the potential generalizability of our approach by experimenting with a different dataset and deep learning architecture.
A wearable sensor vest for social humanoid robots with GPGPU, IoT, and modular software architecture
Jan 06, 2022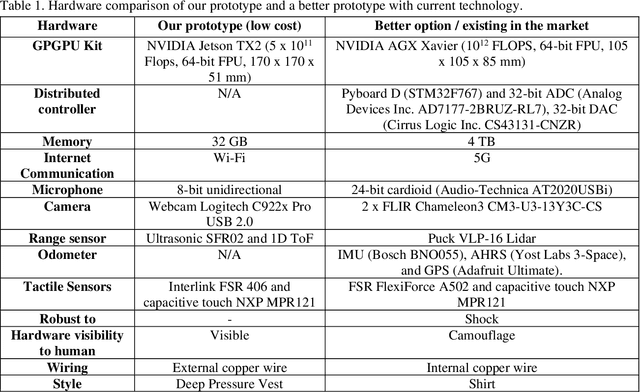
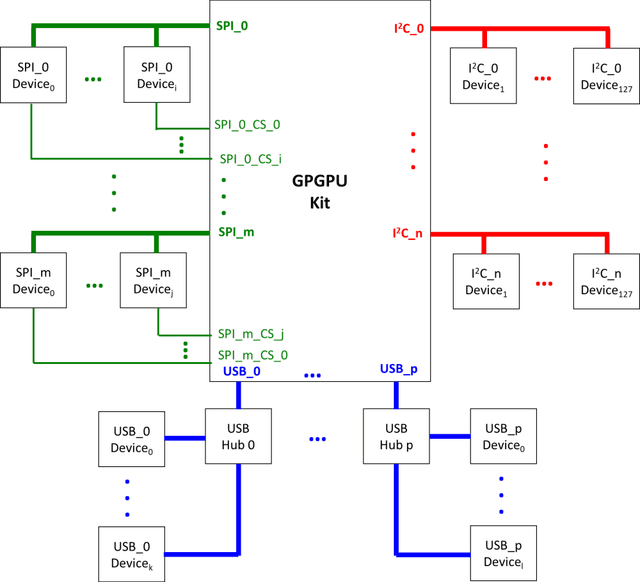
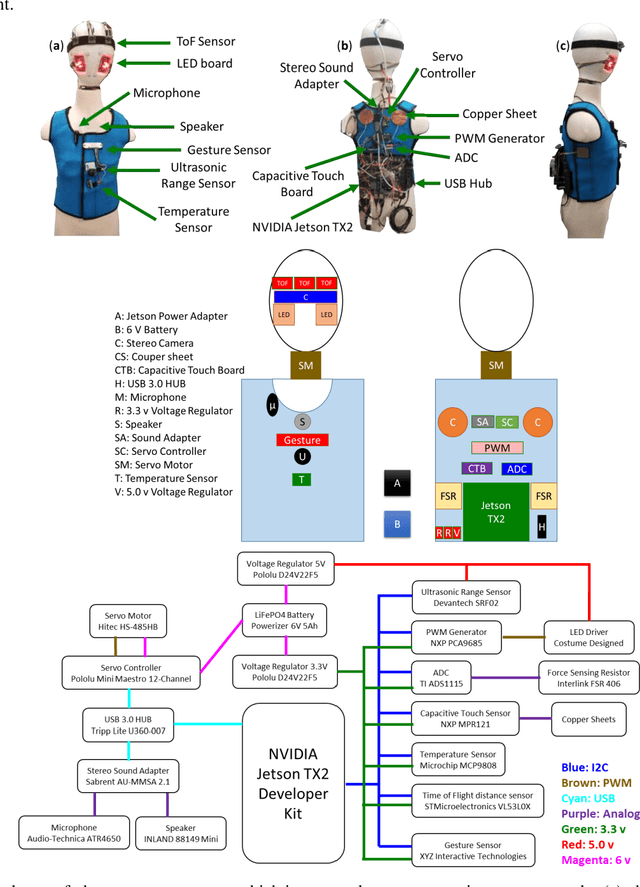
Currently, most social robots interact with their surroundings and humans through sensors that are integral parts of the robots, which limits the usability of the sensors, human-robot interaction, and interchangeability. A wearable sensor garment that fits many robots is needed in many applications. This article presents an affordable wearable sensor vest, and an open-source software architecture with the Internet of Things (IoT) for social humanoid robots. The vest consists of touch, temperature, gesture, distance, vision sensors, and a wireless communication module. The IoT feature allows the robot to interact with humans locally and over the Internet. The designed architecture works for any social robot that has a general-purpose graphics processing unit (GPGPU), I2C/SPI buses, Internet connection, and the Robotics Operating System (ROS). The modular design of this architecture enables developers to easily add/remove/update complex behaviors. The proposed software architecture provides IoT technology, GPGPU nodes, I2C and SPI bus mangers, audio-visual interaction nodes (speech to text, text to speech, and image understanding), and isolation between behavior nodes and other nodes. The proposed IoT solution consists of related nodes in the robot, a RESTful web service, and user interfaces. We used the HTTP protocol as a means of two-way communication with the social robot over the Internet. Developers can easily edit or add nodes in C, C++, and Python programming languages. Our architecture can be used for designing more sophisticated behaviors for social humanoid robots.
* This is the preprint version. The final version is published in Robotics and Autonomous Systems, Volume 139, 2021, Page 103536, ISSN 0921-8890, https://doi.org/10.1016/j.robot.2020.103536
Haptic-enabled Mixed Reality System for Mixed-initiative Remote Robot Control
Feb 06, 2021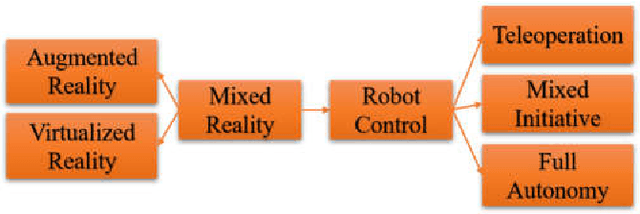

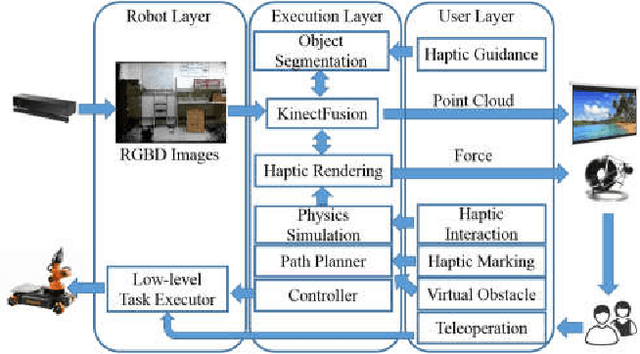

Robots assist in many areas that are considered unsafe for humans to operate. For instance, in handling pandemic diseases such as the recent Covid-19 outbreak and other outbreaks like Ebola, robots can assist in reaching areas dangerous for humans and do simple tasks such as pick up the correct medicine (among a set of bottles prescribed) and deliver to patients. In such cases, it might not be good to rely on the fully autonomous operation of robots. Since many mobile robots are fully functional with low-level tasks such as grabbing and moving, we consider the mixed-initiative control where the user can guide the robot remotely to finish such tasks. For this mixed-initiative control, the user controlling the robot needs to visualize a 3D scene as seen by the robot and guide it. Mixed reality can virtualize reality and immerse users in the 3D scene that is reconstructed from the real-world environment. This technique provides the user more freedom such as choosing viewpoints at view time. In recent years, benefiting from the high-quality data from Light Detection and Ranging (LIDAR) and RGBD cameras, mixed reality is widely used to build networked platforms to improve the performance of robot teleoperations and robot-human collaboration, and enhanced feedback for mixed-initiative control. In this paper, we proposed a novel haptic-enabled mixed reality system, that provides haptic interfaces to interact with the virtualized environments and give remote guidance for mobile robots towards high-level tasks. The experimental results show the effectiveness and flexibility of the proposed haptic enabled mixed reality system.
Region Graph Based Method for Multi-Object Detection and Tracking using Depth Cameras
Mar 11, 2016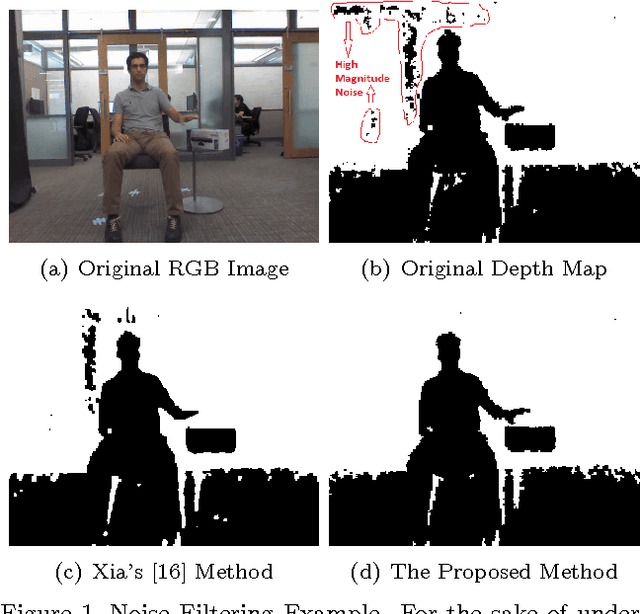
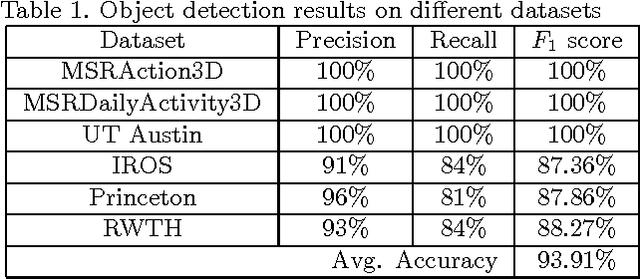

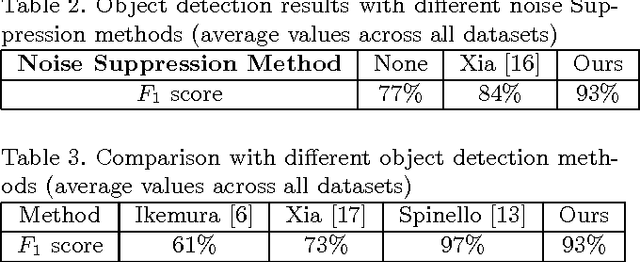
In this paper, we propose a multi-object detection and tracking method using depth cameras. Depth maps are very noisy and obscure in object detection. We first propose a region-based method to suppress high magnitude noise which cannot be filtered using spatial filters. Second, the proposed method detect Region of Interests by temporal learning which are then tracked using weighted graph-based approach. We demonstrate the performance of the proposed method on standard depth camera datasets with and without object occlusions. Experimental results show that the proposed method is able to suppress high magnitude noise in depth maps and detect/track the objects (with and without occlusion).