 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCore-set Selection Using Metrics-based Explanations (CSUME) for multiclass ECG
May 28, 2022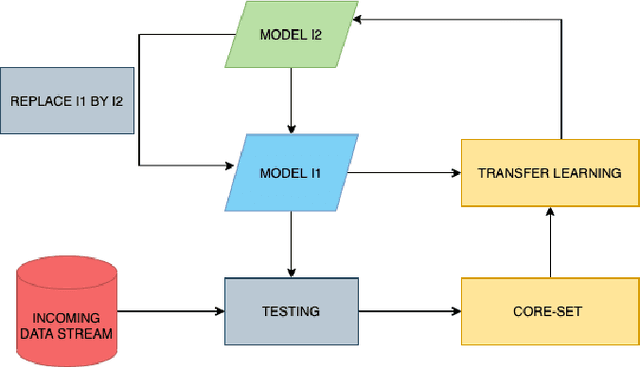
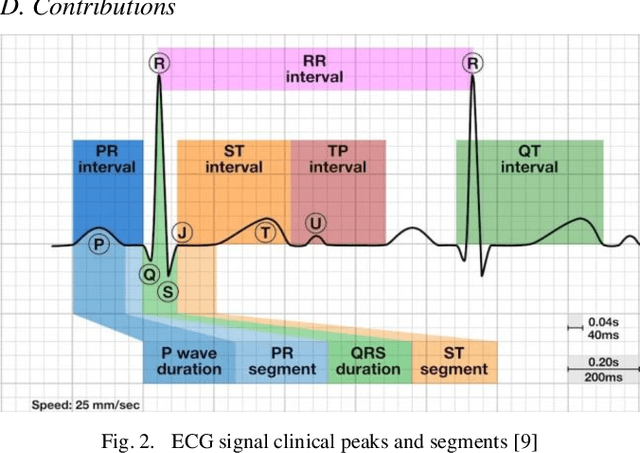
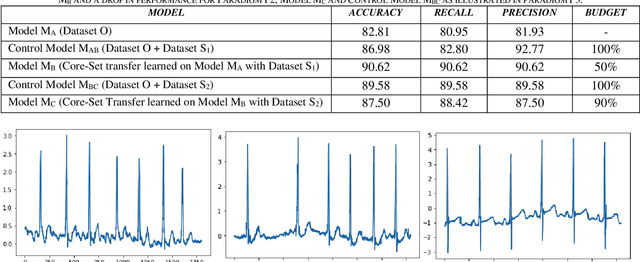
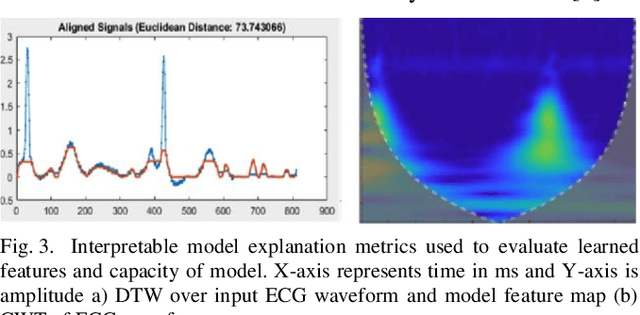
The adoption of deep learning-based healthcare decision support systems such as the detection of irregular cardiac rhythm is hindered by challenges such as lack of access to quality data and the high costs associated with the collection and annotation of data. The collection and processing of large volumes of healthcare data is a continuous process. The performance of data-hungry Deep Learning models (DL) is highly dependent on the quantity and quality of the data. While the need for data quantity has been established through research adequately, we show how a selection of good quality data improves deep learning model performance. In this work, we take Electrocardiogram (ECG) data as a case study and propose a model performance improvement methodology for algorithm developers, that selects the most informative data samples from incoming streams of multi-class ECG data. Our Core-Set selection methodology uses metrics-based explanations to select the most informative ECG data samples. This also provides an understanding (for algorithm developers) as to why a sample was selected as more informative over others for the improvement of deep learning model performance. Our experimental results show a 9.67% and 8.69% precision and recall improvement with a significant training data volume reduction of 50%. Additionally, our proposed methodology asserts the quality and annotation of ECG samples from incoming data streams. It allows automatic detection of individual data samples that do not contribute to model learning thus minimizing possible negative effects on model performance. We further discuss the potential generalizability of our approach by experimenting with a different dataset and deep learning architecture.