 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLiVR: Conversational Learning System in Virtual Reality with AI-Powered Patients
Oct 21, 2025Simulations constitute a fundamental component of medical and nursing education and traditionally employ standardized patients (SP) and high-fidelity manikins to develop clinical reasoning and communication skills. However, these methods require substantial resources, limiting accessibility and scalability. In this study, we introduce CLiVR, a Conversational Learning system in Virtual Reality that integrates large language models (LLMs), speech processing, and 3D avatars to simulate realistic doctor-patient interactions. Developed in Unity and deployed on the Meta Quest 3 platform, CLiVR enables trainees to engage in natural dialogue with virtual patients. Each simulation is dynamically generated from a syndrome-symptom database and enhanced with sentiment analysis to provide feedback on communication tone. Through an expert user study involving medical school faculty (n=13), we assessed usability, realism, and perceived educational impact. Results demonstrated strong user acceptance, high confidence in educational potential, and valuable feedback for improvement. CLiVR offers a scalable, immersive supplement to SP-based training.
Cross-Modality Investigation on WESAD Stress Classification
Feb 26, 2025Deep learning's growing prevalence has driven its widespread use in healthcare, where AI and sensor advancements enhance diagnosis, treatment, and monitoring. In mobile health, AI-powered tools enable early diagnosis and continuous monitoring of conditions like stress. Wearable technologies and multimodal physiological data have made stress detection increasingly viable, but model efficacy depends on data quality, quantity, and modality. This study develops transformer models for stress detection using the WESAD dataset, training on electrocardiograms (ECG), electrodermal activity (EDA), electromyography (EMG), respiration rate (RESP), temperature (TEMP), and 3-axis accelerometer (ACC) signals. The results demonstrate the effectiveness of single-modality transformers in analyzing physiological signals, achieving state-of-the-art performance with accuracy, precision and recall values in the range of $99.73\%$ to $99.95\%$ for stress detection. Furthermore, this study explores cross-modal performance and also explains the same using 2D visualization of the learned embedding space and quantitative analysis based on data variance. Despite the large body of work on stress detection and monitoring, the robustness and generalization of these models across different modalities has not been explored. This research represents one of the initial efforts to interpret embedding spaces for stress detection, providing valuable information on cross-modal performance.
Faculty Perspectives on the Potential of RAG in Computer Science Higher Education
Jul 28, 2024The emergence of Large Language Models (LLMs) has significantly impacted the field of Natural Language Processing and has transformed conversational tasks across various domains because of their widespread integration in applications and public access. The discussion surrounding the application of LLMs in education has raised ethical concerns, particularly concerning plagiarism and policy compliance. Despite the prowess of LLMs in conversational tasks, the limitations of reliability and hallucinations exacerbate the need to guardrail conversations, motivating our investigation of RAG in computer science higher education. We developed Retrieval Augmented Generation (RAG) applications for the two tasks of virtual teaching assistants and teaching aids. In our study, we collected the ratings and opinions of faculty members in undergraduate and graduate computer science university courses at various levels, using our personalized RAG systems for each course. This study is the first to gather faculty feedback on the application of LLM-based RAG in education. The investigation revealed that while faculty members acknowledge the potential of RAG systems as virtual teaching assistants and teaching aids, certain barriers and features are suggested for their full-scale deployment. These findings contribute to the ongoing discussion on the integration of advanced language models in educational settings, highlighting the need for careful consideration of ethical implications and the development of appropriate safeguards to ensure responsible and effective implementation.
Can Public LLMs be used for Self-Diagnosis of Medical Conditions ?
May 18, 2024The advancements in the development of Large Language Models have evolved as a transformative paradigm in conversational tasks which has led to its integration in the critical domain of healthcare. With LLMs becoming widely popular and their public access through open-source models, there is a need to investigate their potential and limitations. One such critical task where LLMs are applied but require a deeper understanding is that of self-diagnosis of medical conditions in the interest of public health. The widespread integration of Gemini with Google search, GPT-4.0 with Bing search, has led to shift in trend of self-diagnosis from search engine LLMs. In this paper, we prepare a prompt engineered dataset of 10000 samples and test the performance on the general task of self-diagnosis. We compare the performance of GPT-4.0 and Gemini model on the task of self-diagnosis and record accuracies of 63.07% and 6.01% respectively. We also discuss the challenges, limitations, and potential of both Gemini and GPT-4.0 for the task of self-diagnosis to facilitate future research and towards the broader impact of general public knowledge. Furthermore, we demonstrate the potential and improvement in performance for the task of self-diagnosis using Retrieval Augmented Generation.
Core-set Selection Using Metrics-based Explanations (CSUME) for multiclass ECG
May 28, 2022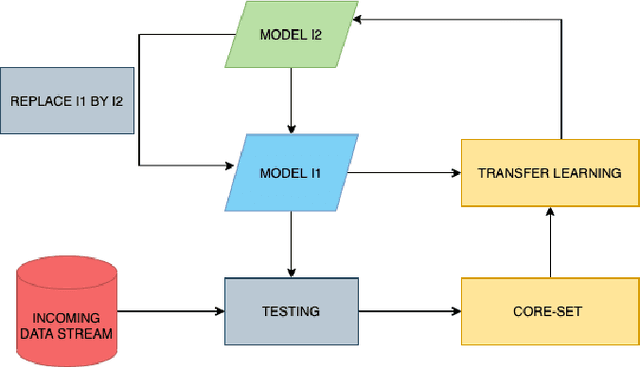
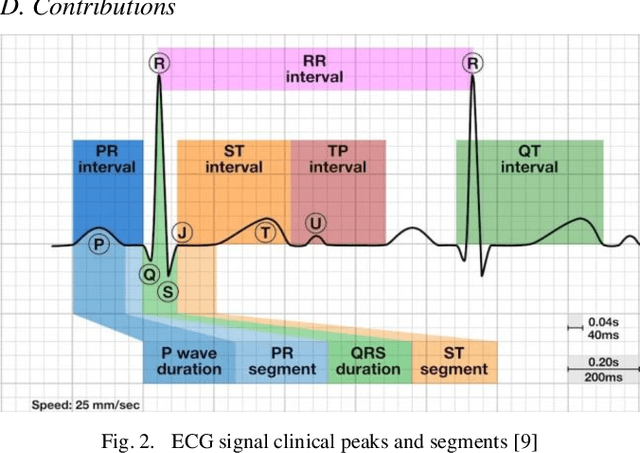
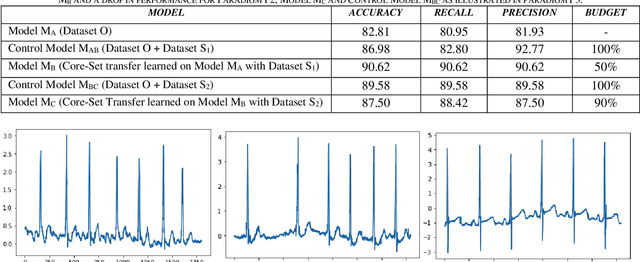
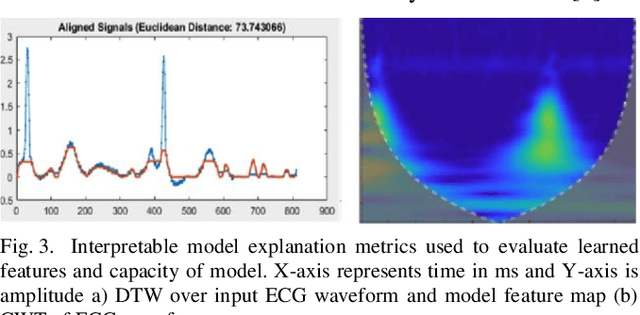
The adoption of deep learning-based healthcare decision support systems such as the detection of irregular cardiac rhythm is hindered by challenges such as lack of access to quality data and the high costs associated with the collection and annotation of data. The collection and processing of large volumes of healthcare data is a continuous process. The performance of data-hungry Deep Learning models (DL) is highly dependent on the quantity and quality of the data. While the need for data quantity has been established through research adequately, we show how a selection of good quality data improves deep learning model performance. In this work, we take Electrocardiogram (ECG) data as a case study and propose a model performance improvement methodology for algorithm developers, that selects the most informative data samples from incoming streams of multi-class ECG data. Our Core-Set selection methodology uses metrics-based explanations to select the most informative ECG data samples. This also provides an understanding (for algorithm developers) as to why a sample was selected as more informative over others for the improvement of deep learning model performance. Our experimental results show a 9.67% and 8.69% precision and recall improvement with a significant training data volume reduction of 50%. Additionally, our proposed methodology asserts the quality and annotation of ECG samples from incoming data streams. It allows automatic detection of individual data samples that do not contribute to model learning thus minimizing possible negative effects on model performance. We further discuss the potential generalizability of our approach by experimenting with a different dataset and deep learning architecture.