 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLGTformer: An Attention-Based Approach to Sign Language Recognition
Dec 23, 2022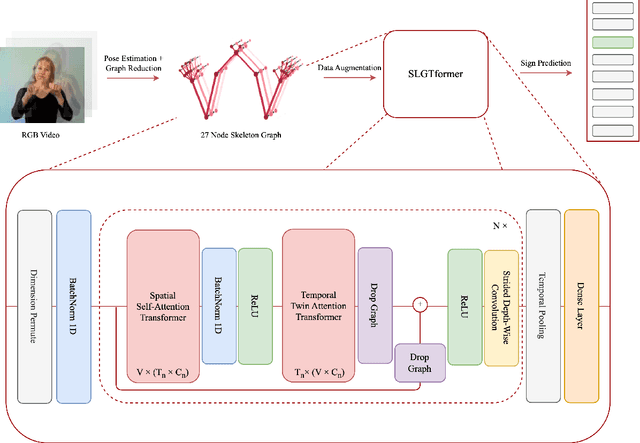



Sign language is the preferred method of communication of deaf or mute people, but similar to any language, it is difficult to learn and represents a significant barrier for those who are hard of hearing or unable to speak. A person's entire frontal appearance dictates and conveys specific meaning. However, this frontal appearance can be quantified as a temporal sequence of human body pose, leading to Sign Language Recognition through the learning of spatiotemporal dynamics of skeleton keypoints. We propose a novel, attention-based approach to Sign Language Recognition exclusively built upon decoupled graph and temporal self-attention: the Sign Language Graph Time Transformer (SLGTformer). SLGTformer first deconstructs spatiotemporal pose sequences separately into spatial graphs and temporal windows. SLGTformer then leverages novel Learnable Graph Relative Positional Encodings (LGRPE) to guide spatial self-attention with the graph neighborhood context of the human skeleton. By modeling the temporal dimension as intra- and inter-window dynamics, we introduce Temporal Twin Self-Attention (TTSA) as the combination of locally-grouped temporal attention (LTA) and global sub-sampled temporal attention (GSTA). We demonstrate the effectiveness of SLGTformer on the World-Level American Sign Language (WLASL) dataset, achieving state-of-the-art performance with an ensemble-free approach on the keypoint modality. The code is available at https://github.com/neilsong/slt
NeuralGrasps: Learning Implicit Representations for Grasps of Multiple Robotic Hands
Jul 06, 2022
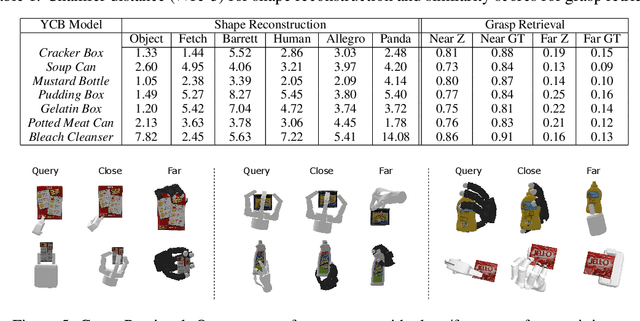
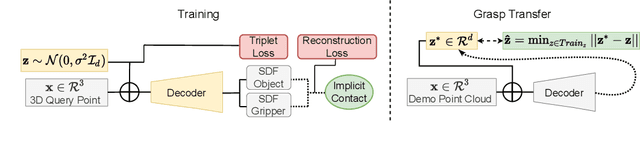
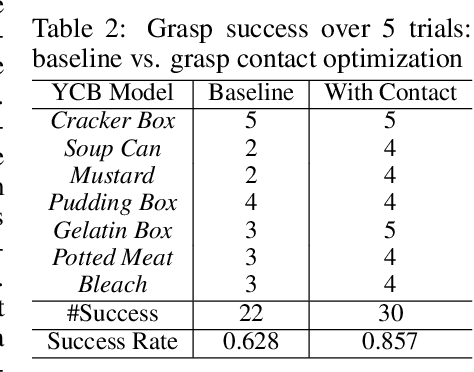
We introduce a neural implicit representation for grasps of objects from multiple robotic hands. Different grasps across multiple robotic hands are encoded into a shared latent space. Each latent vector is learned to decode to the 3D shape of an object and the 3D shape of a robotic hand in a grasping pose in terms of the signed distance functions of the two 3D shapes. In addition, the distance metric in the latent space is learned to preserve the similarity between grasps across different robotic hands, where the similarity of grasps is defined according to contact regions of the robotic hands. This property enables our method to transfer grasps between different grippers including a human hand, and grasp transfer has the potential to share grasping skills between robots and enable robots to learn grasping skills from humans. Furthermore, the encoded signed distance functions of objects and grasps in our implicit representation can be used for 6D object pose estimation with grasping contact optimization from partial point clouds, which enables robotic grasping in the real world.