 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Ring Scan: Revisiting Scan Order in Vision State Space Models
Feb 04, 2026State Space Models (SSMs) have emerged as efficient alternatives to attention for vision tasks, offering lineartime sequence processing with competitive accuracy. Vision SSMs, however, require serializing 2D images into 1D token sequences along a predefined scan order, a factor often overlooked. We show that scan order critically affects performance by altering spatial adjacency, fracturing object continuity, and amplifying degradation under geometric transformations such as rotation. We present Partial RIng Scan Mamba (PRISMamba), a rotation-robust traversal that partitions an image into concentric rings, performs order-agnostic aggregation within each ring, and propagates context across rings through a set of short radial SSMs. Efficiency is further improved via partial channel filtering, which routes only the most informative channels through the recurrent ring pathway while keeping the rest on a lightweight residual branch. On ImageNet-1K, PRISMamba achieves 84.5% Top-1 with 3.9G FLOPs and 3,054 img/s on A100, outperforming VMamba in both accuracy and throughput while requiring fewer FLOPs. It also maintains performance under rotation, whereas fixed-path scans drop by 1~2%. These results highlight scan-order design, together with channel filtering, as a crucial, underexplored factor for accuracy, efficiency, and rotation robustness in Vision SSMs. Code will be released upon acceptance.
FlashSinkhorn: IO-Aware Entropic Optimal Transport
Feb 03, 2026Entropic optimal transport (EOT) via Sinkhorn iterations is widely used in modern machine learning, yet GPU solvers remain inefficient at scale. Tensorized implementations suffer quadratic HBM traffic from dense $n\times m$ interactions, while existing online backends avoid storing dense matrices but still rely on generic tiled map-reduce reduction kernels with limited fusion. We present \textbf{FlashSinkhorn}, an IO-aware EOT solver for squared Euclidean cost that rewrites stabilized log-domain Sinkhorn updates as row-wise LogSumExp reductions of biased dot-product scores, the same normalization as transformer attention. This enables FlashAttention-style fusion and tiling: fused Triton kernels stream tiles through on-chip SRAM and update dual potentials in a single pass, substantially reducing HBM IO per iteration while retaining linear-memory operations. We further provide streaming kernels for transport application, enabling scalable first- and second-order optimization. On A100 GPUs, FlashSinkhorn achieves up to $32\times$ forward-pass and $161\times$ end-to-end speedups over state-of-the-art online baselines on point-cloud OT, improves scalability on OT-based downstream tasks. For reproducibility, we release an open-source implementation at https://github.com/ot-triton-lab/ot_triton.
SMART: Shot-Aware Multimodal Video Moment Retrieval with Audio-Enhanced MLLM
Nov 18, 2025Video Moment Retrieval is a task in video understanding that aims to localize a specific temporal segment in an untrimmed video based on a natural language query. Despite recent progress in moment retrieval from videos using both traditional techniques and Multimodal Large Language Models (MLLM), most existing methods still rely on coarse temporal understanding and a single visual modality, limiting performance on complex videos. To address this, we introduce \textit{S}hot-aware \textit{M}ultimodal \textit{A}udio-enhanced \textit{R}etrieval of \textit{T}emporal \textit{S}egments (SMART), an MLLM-based framework that integrates audio cues and leverages shot-level temporal structure. SMART enriches multimodal representations by combining audio and visual features while applying \textbf{Shot-aware Token Compression}, which selectively retains high-information tokens within each shot to reduce redundancy and preserve fine-grained temporal details. We also refine prompt design to better utilize audio-visual cues. Evaluations on Charades-STA and QVHighlights show that SMART achieves significant improvements over state-of-the-art methods, including a 1.61\% increase in R1@0.5 and 2.59\% gain in R1@0.7 on Charades-STA.
Dual-Process Scaffold Reasoning for Enhancing LLM Code Debugging
Nov 11, 2025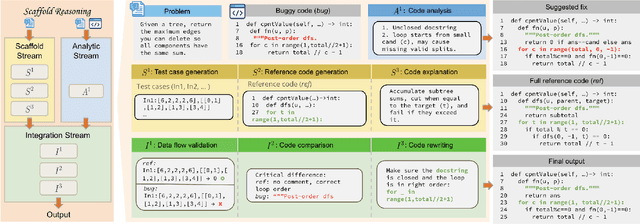
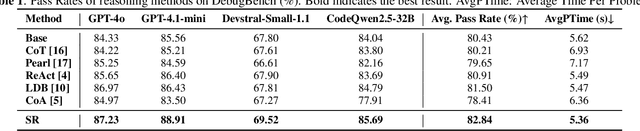
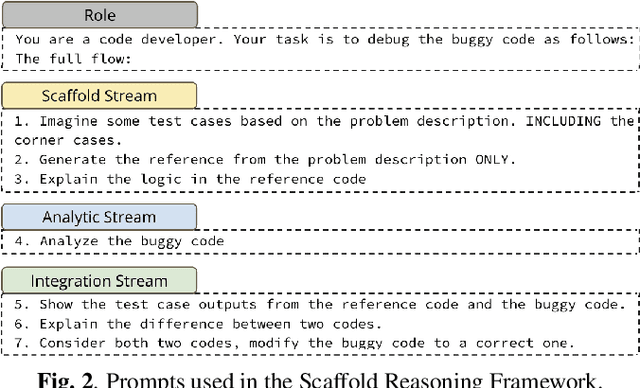

Recent LLMs have demonstrated sophisticated problem-solving capabilities on various benchmarks through advanced reasoning algorithms. However, the key research question of identifying reasoning steps that balance complexity and computational efficiency remains unsolved. Recent research has increasingly drawn upon psychological theories to explore strategies for optimizing cognitive pathways. The LLM's final outputs and intermediate steps are regarded as System 1 and System 2, respectively. However, an in-depth exploration of the System 2 reasoning is still lacking. Therefore, we propose a novel psychologically backed Scaffold Reasoning framework for code debugging, which encompasses the Scaffold Stream, Analytic Stream, and Integration Stream. The construction of reference code within the Scaffold Stream is integrated with the buggy code analysis results produced by the Analytic Stream through the Integration Stream. Our framework achieves an 88.91% pass rate and an average inference time of 5.36 seconds per-problem on DebugBench, outperforming other reasoning approaches across various LLMs in both reasoning accuracy and efficiency. Further analyses elucidate the advantages and limitations of various cognitive pathways across varying problem difficulties and bug types. Our findings also corroborate the alignment of the proposed Scaffold Reasoning framework with human cognitive processes.
How Bias Binds: Measuring Hidden Associations for Bias Control in Text-to-Image Compositions
Nov 10, 2025Text-to-image generative models often exhibit bias related to sensitive attributes. However, current research tends to focus narrowly on single-object prompts with limited contextual diversity. In reality, each object or attribute within a prompt can contribute to bias. For example, the prompt "an assistant wearing a pink hat" may reflect female-inclined biases associated with a pink hat. The neglected joint effects of the semantic binding in the prompts cause significant failures in current debiasing approaches. This work initiates a preliminary investigation on how bias manifests under semantic binding, where contextual associations between objects and attributes influence generative outcomes. We demonstrate that the underlying bias distribution can be amplified based on these associations. Therefore, we introduce a bias adherence score that quantifies how specific object-attribute bindings activate bias. To delve deeper, we develop a training-free context-bias control framework to explore how token decoupling can facilitate the debiasing of semantic bindings. This framework achieves over 10% debiasing improvement in compositional generation tasks. Our analysis of bias scores across various attribute-object bindings and token decorrelation highlights a fundamental challenge: reducing bias without disrupting essential semantic relationships. These findings expose critical limitations in current debiasing approaches when applied to semantically bound contexts, underscoring the need to reassess prevailing bias mitigation strategies.
Sharpness-Aware Geometric Defense for Robust Out-Of-Distribution Detection
Aug 24, 2025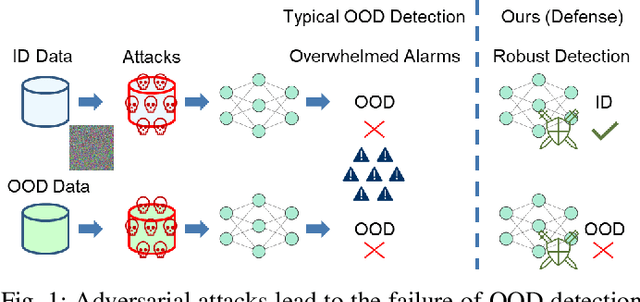
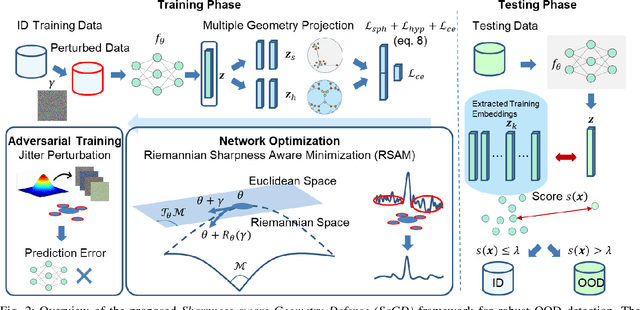
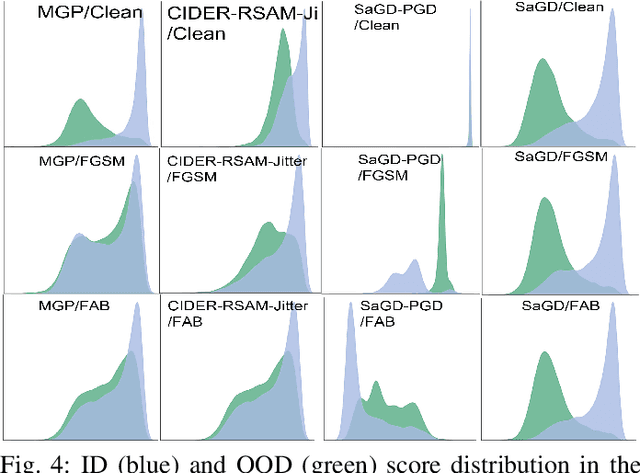
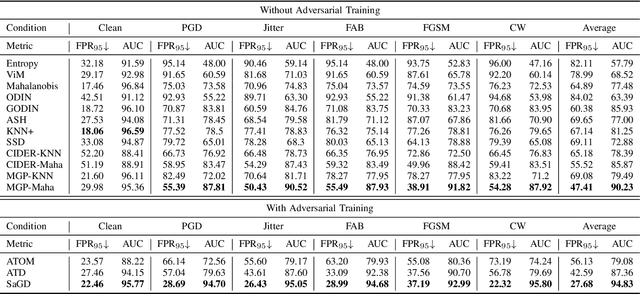
Out-of-distribution (OOD) detection ensures safe and reliable model deployment. Contemporary OOD algorithms using geometry projection can detect OOD or adversarial samples from clean in-distribution (ID) samples. However, this setting regards adversarial ID samples as OOD, leading to incorrect OOD predictions. Existing efforts on OOD detection with ID and OOD data under attacks are minimal. In this paper, we develop a robust OOD detection method that distinguishes adversarial ID samples from OOD ones. The sharp loss landscape created by adversarial training hinders model convergence, impacting the latent embedding quality for OOD score calculation. Therefore, we introduce a {\bf Sharpness-aware Geometric Defense (SaGD)} framework to smooth out the rugged adversarial loss landscape in the projected latent geometry. Enhanced geometric embedding convergence enables accurate ID data characterization, benefiting OOD detection against adversarial attacks. We use Jitter-based perturbation in adversarial training to extend the defense ability against unseen attacks. Our SaGD framework significantly improves FPR and AUC over the state-of-the-art defense approaches in differentiating CIFAR-100 from six other OOD datasets under various attacks. We further examine the effects of perturbations at various adversarial training levels, revealing the relationship between the sharp loss landscape and adversarial OOD detection.
IntelliCardiac: An Intelligent Platform for Cardiac Image Segmentation and Classification
May 08, 2025Precise and effective processing of cardiac imaging data is critical for the identification and management of the cardiovascular diseases. We introduce IntelliCardiac, a comprehensive, web-based medical image processing platform for the automatic segmentation of 4D cardiac images and disease classification, utilizing an AI model trained on the publicly accessible ACDC dataset. The system, intended for patients, cardiologists, and healthcare professionals, offers an intuitive interface and uses deep learning models to identify essential heart structures and categorize cardiac diseases. The system supports analysis of both the right and left ventricles as well as myocardium, and then classifies patient's cardiac images into five diagnostic categories: dilated cardiomyopathy, myocardial infarction, hypertrophic cardiomyopathy, right ventricular abnormality, and no disease. IntelliCardiac combines a deep learning-based segmentation model with a two-step classification pipeline. The segmentation module gains an overall accuracy of 92.6%. The classification module, trained on characteristics taken from segmented heart structures, achieves 98% accuracy in five categories. These results exceed the performance of the existing state-of-the-art methods that integrate both segmentation and classification models. IntelliCardiac, which supports real-time visualization, workflow integration, and AI-assisted diagnostics, has great potential as a scalable, accurate tool for clinical decision assistance in cardiac imaging and diagnosis.
RLMiniStyler: Light-weight RL Style Agent for Arbitrary Sequential Neural Style Generation
May 07, 2025Arbitrary style transfer aims to apply the style of any given artistic image to another content image. Still, existing deep learning-based methods often require significant computational costs to generate diverse stylized results. Motivated by this, we propose a novel reinforcement learning-based framework for arbitrary style transfer RLMiniStyler. This framework leverages a unified reinforcement learning policy to iteratively guide the style transfer process by exploring and exploiting stylization feedback, generating smooth sequences of stylized results while achieving model lightweight. Furthermore, we introduce an uncertainty-aware multi-task learning strategy that automatically adjusts loss weights to adapt to the content and style balance requirements at different training stages, thereby accelerating model convergence. Through a series of experiments across image various resolutions, we have validated the advantages of RLMiniStyler over other state-of-the-art methods in generating high-quality, diverse artistic image sequences at a lower cost. Codes are available at https://github.com/fengxiaoming520/RLMiniStyler.
E4: Energy-Efficient DNN Inference for Edge Video Analytics Via Early-Exit and DVFS
Mar 06, 2025



Deep neural network (DNN) models are increasingly popular in edge video analytic applications. However, the compute-intensive nature of DNN models pose challenges for energy-efficient inference on resource-constrained edge devices. Most existing solutions focus on optimizing DNN inference latency and accuracy, often overlooking energy efficiency. They also fail to account for the varying complexity of video frames, leading to sub-optimal performance in edge video analytics. In this paper, we propose an Energy-Efficient Early-Exit (E4) framework that enhances DNN inference efficiency for edge video analytics by integrating a novel early-exit mechanism with dynamic voltage and frequency scaling (DVFS) governors. It employs an attention-based cascade module to analyze video frame diversity and automatically determine optimal DNN exit points. Additionally, E4 features a just-in-time (JIT) profiler that uses coordinate descent search to co-optimize CPU and GPU clock frequencies for each layer before the DNN exit points. Extensive evaluations demonstrate that E4 outperforms current state-of-the-art methods, achieving up to 2.8x speedup and 26% average energy saving while maintaining high accuracy.
Who Brings the Frisbee: Probing Hidden Hallucination Factors in Large Vision-Language Model via Causality Analysis
Dec 04, 2024
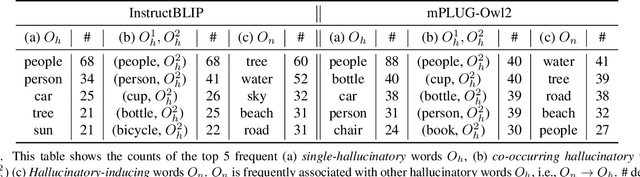

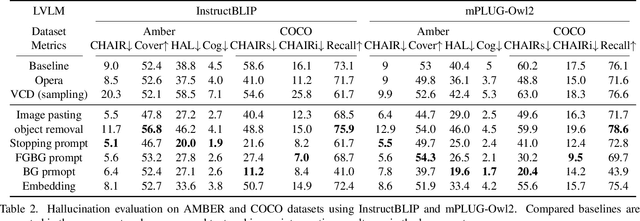
Recent advancements in large vision-language models (LVLM) have significantly enhanced their ability to comprehend visual inputs alongside natural language. However, a major challenge in their real-world application is hallucination, where LVLMs generate non-existent visual elements, eroding user trust. The underlying mechanism driving this multimodal hallucination is poorly understood. Minimal research has illuminated whether contexts such as sky, tree, or grass field involve the LVLM in hallucinating a frisbee. We hypothesize that hidden factors, such as objects, contexts, and semantic foreground-background structures, induce hallucination. This study proposes a novel causal approach: a hallucination probing system to identify these hidden factors. By analyzing the causality between images, text prompts, and network saliency, we systematically explore interventions to block these factors. Our experimental findings show that a straightforward technique based on our analysis can significantly reduce hallucinations. Additionally, our analyses indicate the potential to edit network internals to minimize hallucinated outputs.