 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Instance-Dependent Noisy Labels by Anchor Hallucination and Hard Sample Label Correction
Jul 10, 2024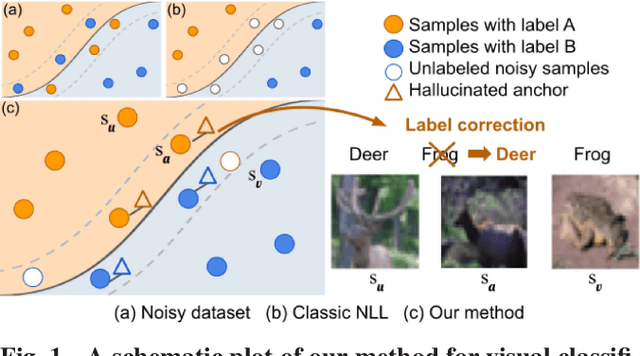



Learning from noisy-labeled data is crucial for real-world applications. Traditional Noisy-Label Learning (NLL) methods categorize training data into clean and noisy sets based on the loss distribution of training samples. However, they often neglect that clean samples, especially those with intricate visual patterns, may also yield substantial losses. This oversight is particularly significant in datasets with Instance-Dependent Noise (IDN), where mislabeling probabilities correlate with visual appearance. Our approach explicitly distinguishes between clean vs.noisy and easy vs. hard samples. We identify training samples with small losses, assuming they have simple patterns and correct labels. Utilizing these easy samples, we hallucinate multiple anchors to select hard samples for label correction. Corrected hard samples, along with the easy samples, are used as labeled data in subsequent semi-supervised training. Experiments on synthetic and real-world IDN datasets demonstrate the superior performance of our method over other state-of-the-art NLL methods.
Improving Limited Supervised Foot Ulcer Segmentation Using Cross-Domain Augmentation
Jan 16, 2024Diabetic foot ulcers pose health risks, including higher morbidity, mortality, and amputation rates. Monitoring wound areas is crucial for proper care, but manual segmentation is subjective due to complex wound features and background variation. Expert annotations are costly and time-intensive, thus hampering large dataset creation. Existing segmentation models relying on extensive annotations are impractical in real-world scenarios with limited annotated data. In this paper, we propose a cross-domain augmentation method named TransMix that combines Augmented Global Pre-training AGP and Localized CutMix Fine-tuning LCF to enrich wound segmentation data for model learning. TransMix can effectively improve the foot ulcer segmentation model training by leveraging other dermatology datasets not on ulcer skins or wounds. AGP effectively increases the overall image variability, while LCF increases the diversity of wound regions. Experimental results show that TransMix increases the variability of wound regions and substantially improves the Dice score for models trained with only 40 annotated images under various proportions.
Domain-Generalized Textured Surface Anomaly Detection
Mar 23, 2022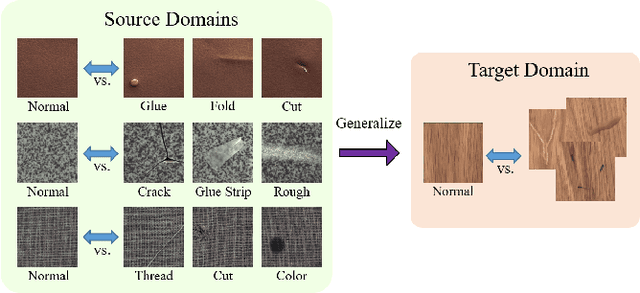
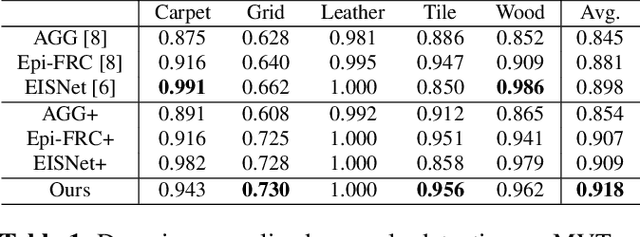
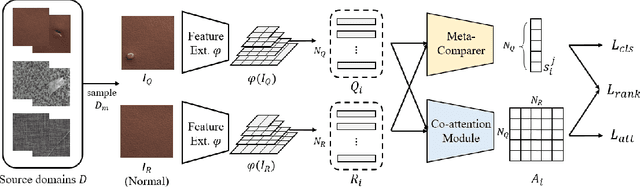
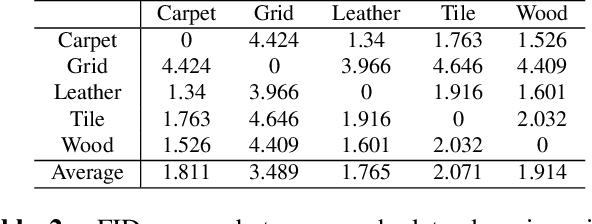
Anomaly detection aims to identify abnormal data that deviates from the normal ones, while typically requiring a sufficient amount of normal data to train the model for performing this task. Despite the success of recent anomaly detection methods, performing anomaly detection in an unseen domain remain a challenging task. In this paper, we address the task of domain-generalized textured surface anomaly detection. By observing normal and abnormal surface data across multiple source domains, our model is expected to be generalized to an unseen textured surface of interest, in which only a small number of normal data can be observed during testing. Although with only image-level labels observed in the training data, our patch-based meta-learning model exhibits promising generalization ability: not only can it generalize to unseen image domains, but it can also localize abnormal regions in the query image. Our experiments verify that our model performs favorably against state-of-the-art anomaly detection and domain generalization approaches in various settings.
A Detailed Look At CNN-based Approaches In Facial Landmark Detection
May 08, 2020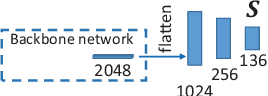

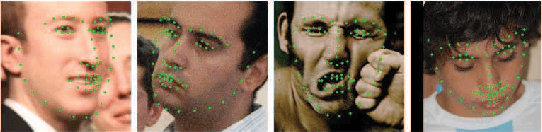
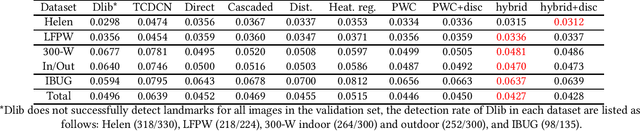
Facial landmark detection has been studied over decades. Numerous neural network (NN)-based approaches have been proposed for detecting landmarks, especially the convolutional neural network (CNN)-based approaches. In general, CNN-based approaches can be divided into regression and heatmap approaches. However, no research systematically studies the characteristics of different approaches. In this paper, we investigate both CNN-based approaches, generalize their advantages and disadvantages, and introduce a variation of the heatmap approach, a pixel-wise classification (PWC) model. To the best of our knowledge, using the PWC model to detect facial landmarks have not been comprehensively studied. We further design a hybrid loss function and a discrimination network for strengthening the landmarks' interrelationship implied in the PWC model to improve the detection accuracy without modifying the original model architecture. Six common facial landmark datasets, AFW, Helen, LFPW, 300-W, IBUG, and COFW are adopted to train or evaluate our model. A comprehensive evaluation is conducted and the result shows that the proposed model outperforms other models in all tested datasets.