 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Instance-Dependent Noisy Labels by Anchor Hallucination and Hard Sample Label Correction
Jul 10, 2024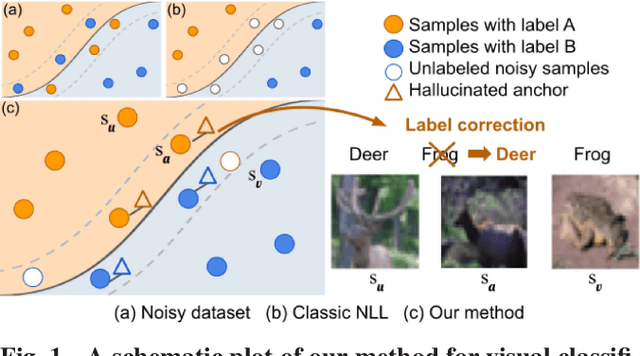



Learning from noisy-labeled data is crucial for real-world applications. Traditional Noisy-Label Learning (NLL) methods categorize training data into clean and noisy sets based on the loss distribution of training samples. However, they often neglect that clean samples, especially those with intricate visual patterns, may also yield substantial losses. This oversight is particularly significant in datasets with Instance-Dependent Noise (IDN), where mislabeling probabilities correlate with visual appearance. Our approach explicitly distinguishes between clean vs.noisy and easy vs. hard samples. We identify training samples with small losses, assuming they have simple patterns and correct labels. Utilizing these easy samples, we hallucinate multiple anchors to select hard samples for label correction. Corrected hard samples, along with the easy samples, are used as labeled data in subsequent semi-supervised training. Experiments on synthetic and real-world IDN datasets demonstrate the superior performance of our method over other state-of-the-art NLL methods.
A Comprehensive Review of Machine Learning Advances on Data Change: A Cross-Field Perspective
Feb 20, 2024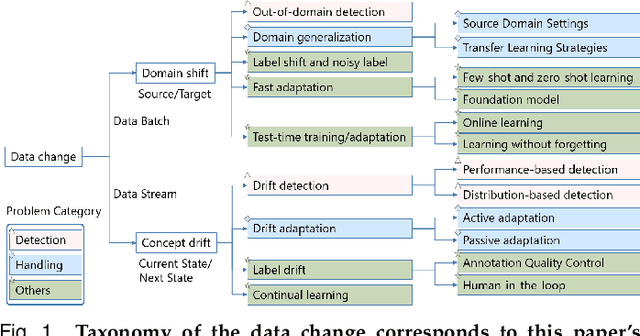
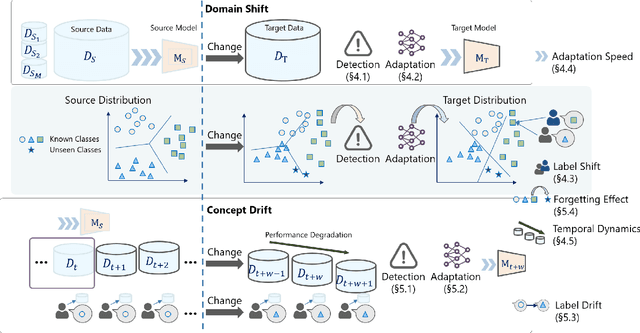
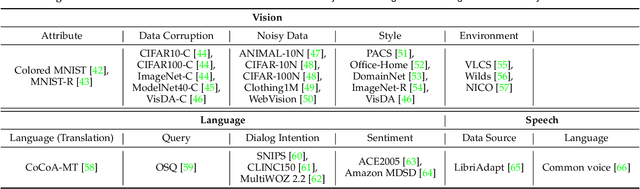
Recent artificial intelligence (AI) technologies show remarkable evolution in various academic fields and industries. However, in the real world, dynamic data lead to principal challenges for deploying AI models. An unexpected data change brings about severe performance degradation in AI models. We identify two major related research fields, domain shift and concept drift according to the setting of the data change. Although these two popular research fields aim to solve distribution shift and non-stationary data stream problems, the underlying properties remain similar which also encourages similar technical approaches. In this review, we regroup domain shift and concept drift into a single research problem, namely the data change problem, with a systematic overview of state-of-the-art methods in the two research fields. We propose a three-phase problem categorization scheme to link the key ideas in the two technical fields. We thus provide a novel scope for researchers to explore contemporary technical strategies, learn industrial applications, and identify future directions for addressing data change challenges.
FedDig: Robust Federated Learning Using Data Digest to Represent Absent Clients
Oct 05, 2022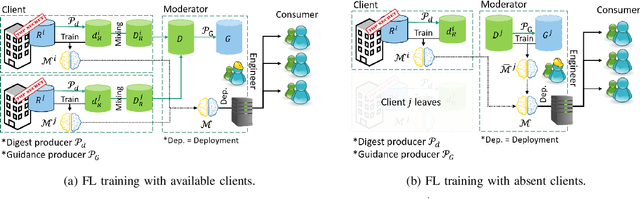
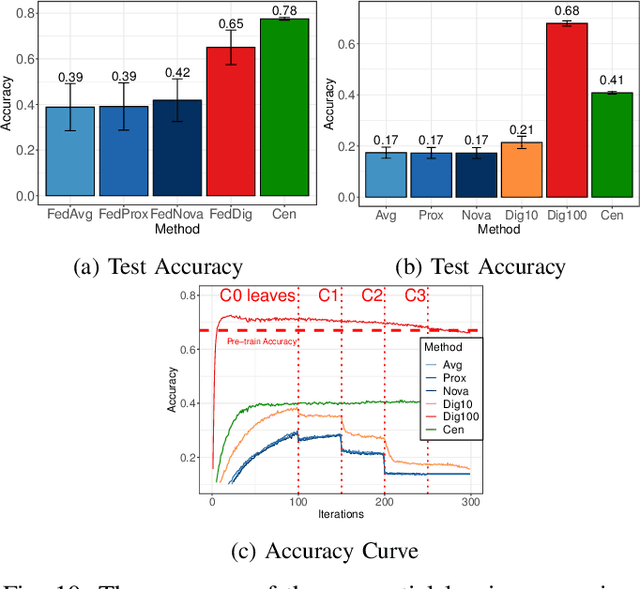
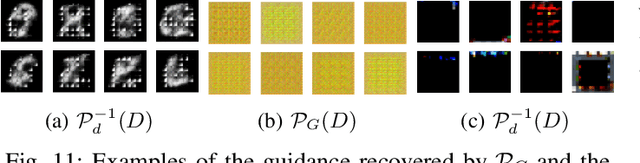
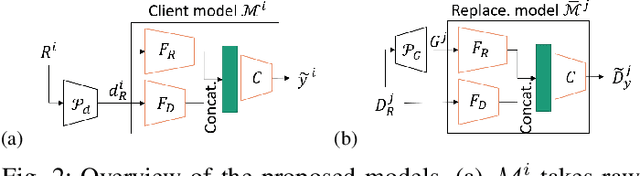
Federated Learning (FL) effectively protects client data privacy. However, client absence or leaving during training can seriously degrade model performances, particularly for unbalanced and non-IID client data. We address this issue by generating data digests from the raw data and using them to guide training at the FL moderator. The proposed FL framework, called FedDig, can tolerate unexpected client absence in cross-silo scenarios while preserving client data privacy because the digests de-identify the raw data by mixing encoded features in the features space. We evaluate FedDig using EMNIST, CIFAR-10, and CIFAR-100; the results consistently outperform against three baseline algorithms (FedAvg, FedProx, and FedNova) by large margins in various client absence scenarios.
A Detailed Look At CNN-based Approaches In Facial Landmark Detection
May 08, 2020

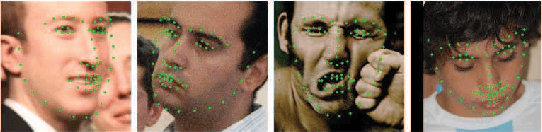
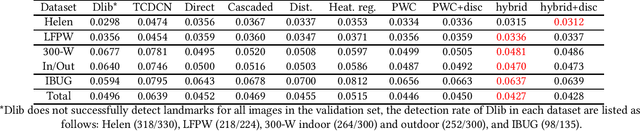
Facial landmark detection has been studied over decades. Numerous neural network (NN)-based approaches have been proposed for detecting landmarks, especially the convolutional neural network (CNN)-based approaches. In general, CNN-based approaches can be divided into regression and heatmap approaches. However, no research systematically studies the characteristics of different approaches. In this paper, we investigate both CNN-based approaches, generalize their advantages and disadvantages, and introduce a variation of the heatmap approach, a pixel-wise classification (PWC) model. To the best of our knowledge, using the PWC model to detect facial landmarks have not been comprehensively studied. We further design a hybrid loss function and a discrimination network for strengthening the landmarks' interrelationship implied in the PWC model to improve the detection accuracy without modifying the original model architecture. Six common facial landmark datasets, AFW, Helen, LFPW, 300-W, IBUG, and COFW are adopted to train or evaluate our model. A comprehensive evaluation is conducted and the result shows that the proposed model outperforms other models in all tested datasets.