 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Bias Binds: Measuring Hidden Associations for Bias Control in Text-to-Image Compositions
Nov 10, 2025Text-to-image generative models often exhibit bias related to sensitive attributes. However, current research tends to focus narrowly on single-object prompts with limited contextual diversity. In reality, each object or attribute within a prompt can contribute to bias. For example, the prompt "an assistant wearing a pink hat" may reflect female-inclined biases associated with a pink hat. The neglected joint effects of the semantic binding in the prompts cause significant failures in current debiasing approaches. This work initiates a preliminary investigation on how bias manifests under semantic binding, where contextual associations between objects and attributes influence generative outcomes. We demonstrate that the underlying bias distribution can be amplified based on these associations. Therefore, we introduce a bias adherence score that quantifies how specific object-attribute bindings activate bias. To delve deeper, we develop a training-free context-bias control framework to explore how token decoupling can facilitate the debiasing of semantic bindings. This framework achieves over 10% debiasing improvement in compositional generation tasks. Our analysis of bias scores across various attribute-object bindings and token decorrelation highlights a fundamental challenge: reducing bias without disrupting essential semantic relationships. These findings expose critical limitations in current debiasing approaches when applied to semantically bound contexts, underscoring the need to reassess prevailing bias mitigation strategies.
Sharpness-Aware Geometric Defense for Robust Out-Of-Distribution Detection
Aug 24, 2025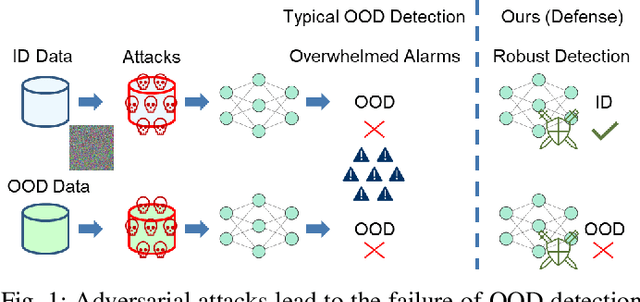
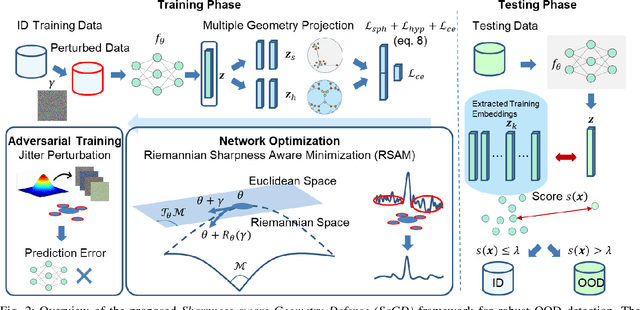
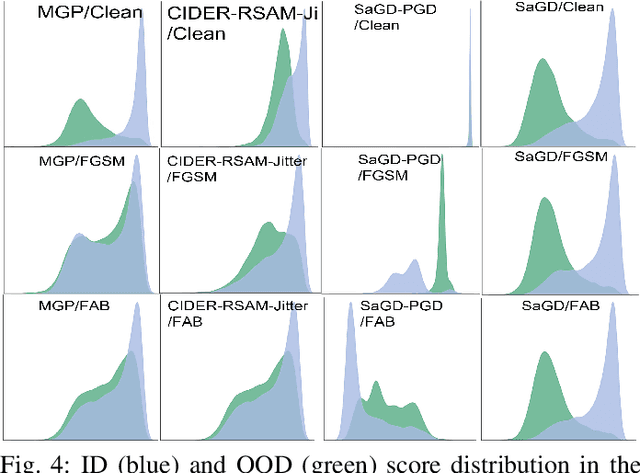
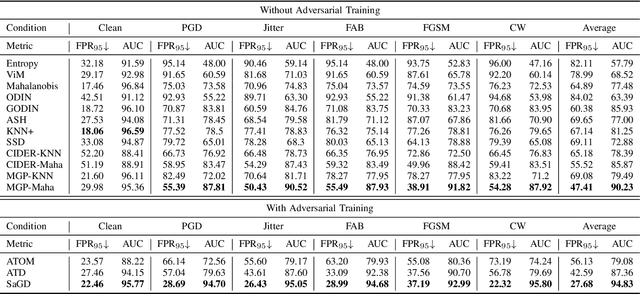
Out-of-distribution (OOD) detection ensures safe and reliable model deployment. Contemporary OOD algorithms using geometry projection can detect OOD or adversarial samples from clean in-distribution (ID) samples. However, this setting regards adversarial ID samples as OOD, leading to incorrect OOD predictions. Existing efforts on OOD detection with ID and OOD data under attacks are minimal. In this paper, we develop a robust OOD detection method that distinguishes adversarial ID samples from OOD ones. The sharp loss landscape created by adversarial training hinders model convergence, impacting the latent embedding quality for OOD score calculation. Therefore, we introduce a {\bf Sharpness-aware Geometric Defense (SaGD)} framework to smooth out the rugged adversarial loss landscape in the projected latent geometry. Enhanced geometric embedding convergence enables accurate ID data characterization, benefiting OOD detection against adversarial attacks. We use Jitter-based perturbation in adversarial training to extend the defense ability against unseen attacks. Our SaGD framework significantly improves FPR and AUC over the state-of-the-art defense approaches in differentiating CIFAR-100 from six other OOD datasets under various attacks. We further examine the effects of perturbations at various adversarial training levels, revealing the relationship between the sharp loss landscape and adversarial OOD detection.
Who Brings the Frisbee: Probing Hidden Hallucination Factors in Large Vision-Language Model via Causality Analysis
Dec 04, 2024
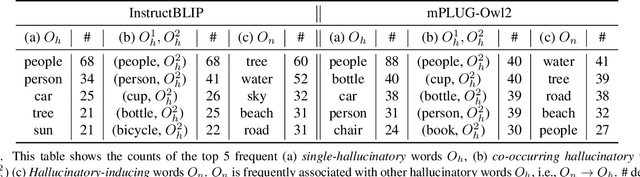

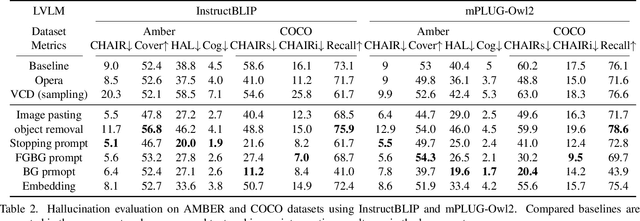
Recent advancements in large vision-language models (LVLM) have significantly enhanced their ability to comprehend visual inputs alongside natural language. However, a major challenge in their real-world application is hallucination, where LVLMs generate non-existent visual elements, eroding user trust. The underlying mechanism driving this multimodal hallucination is poorly understood. Minimal research has illuminated whether contexts such as sky, tree, or grass field involve the LVLM in hallucinating a frisbee. We hypothesize that hidden factors, such as objects, contexts, and semantic foreground-background structures, induce hallucination. This study proposes a novel causal approach: a hallucination probing system to identify these hidden factors. By analyzing the causality between images, text prompts, and network saliency, we systematically explore interventions to block these factors. Our experimental findings show that a straightforward technique based on our analysis can significantly reduce hallucinations. Additionally, our analyses indicate the potential to edit network internals to minimize hallucinated outputs.
Benchmarking Smoothness and Reducing High-Frequency Oscillations in Continuous Control Policies
Oct 22, 2024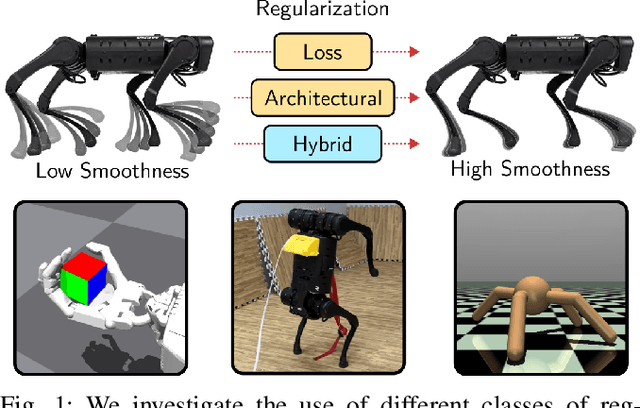
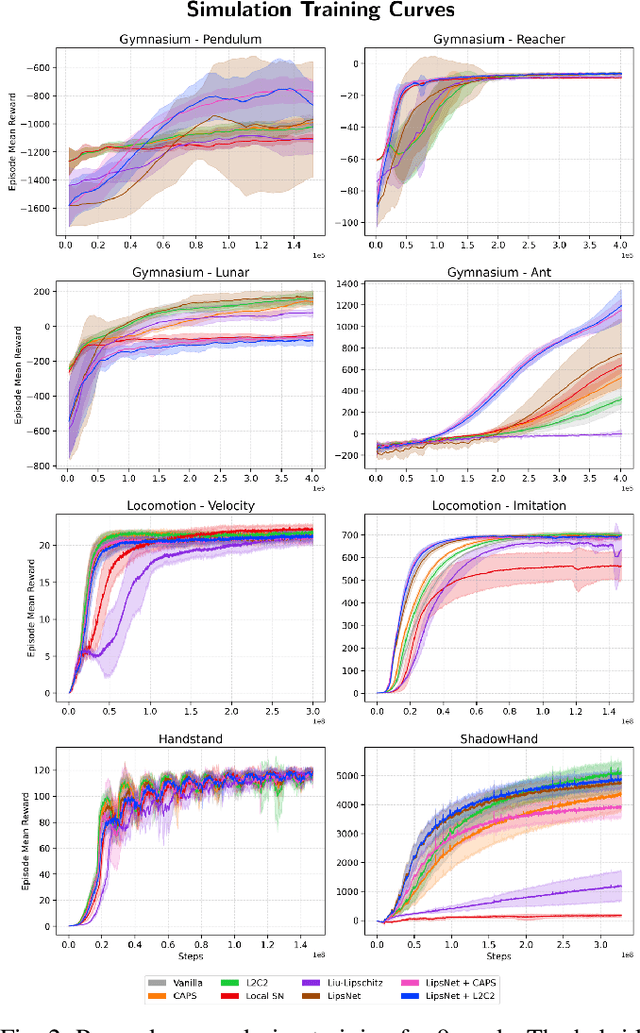
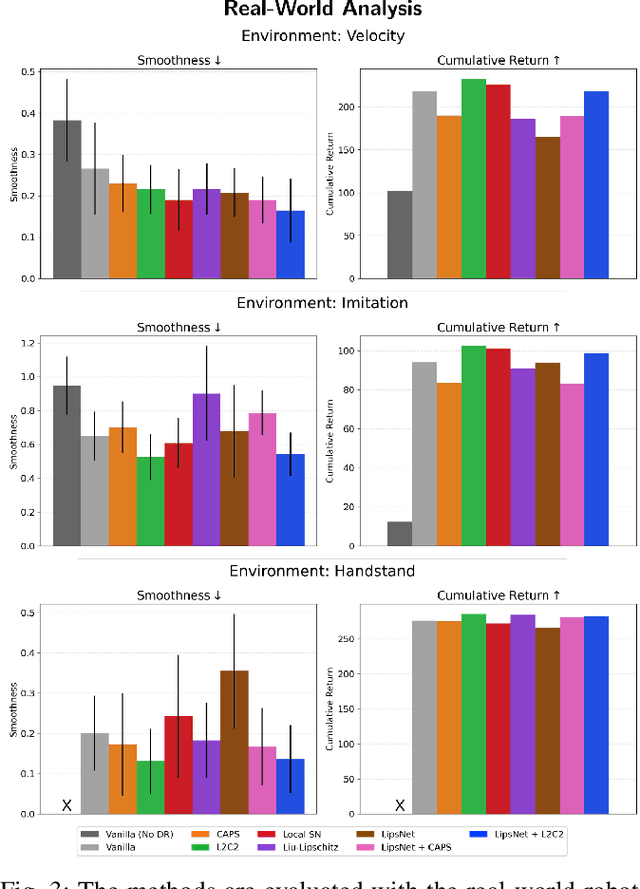
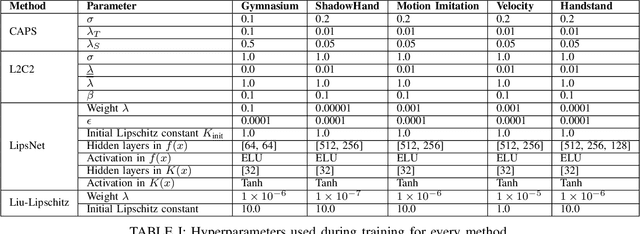
Reinforcement learning (RL) policies are prone to high-frequency oscillations, especially undesirable when deploying to hardware in the real-world. In this paper, we identify, categorize, and compare methods from the literature that aim to mitigate high-frequency oscillations in deep RL. We define two broad classes: loss regularization and architectural methods. At their core, these methods incentivize learning a smooth mapping, such that nearby states in the input space produce nearby actions in the output space. We present benchmarks in terms of policy performance and control smoothness on traditional RL environments from the Gymnasium and a complex manipulation task, as well as three robotics locomotion tasks that include deployment and evaluation with real-world hardware. Finally, we also propose hybrid methods that combine elements from both loss regularization and architectural methods. We find that the best-performing hybrid outperforms other methods, and improves control smoothness by 26.8% over the baseline, with a worst-case performance degradation of just 2.8%.
Learning with Instance-Dependent Noisy Labels by Anchor Hallucination and Hard Sample Label Correction
Jul 10, 2024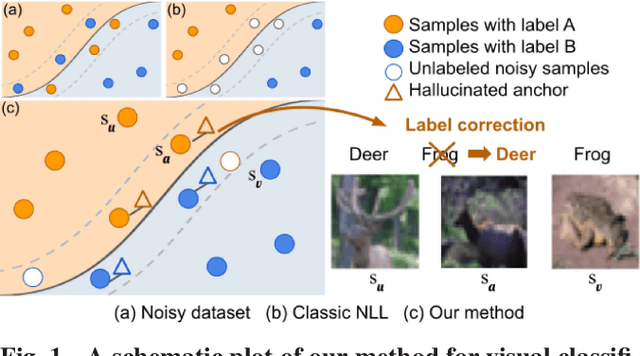



Learning from noisy-labeled data is crucial for real-world applications. Traditional Noisy-Label Learning (NLL) methods categorize training data into clean and noisy sets based on the loss distribution of training samples. However, they often neglect that clean samples, especially those with intricate visual patterns, may also yield substantial losses. This oversight is particularly significant in datasets with Instance-Dependent Noise (IDN), where mislabeling probabilities correlate with visual appearance. Our approach explicitly distinguishes between clean vs.noisy and easy vs. hard samples. We identify training samples with small losses, assuming they have simple patterns and correct labels. Utilizing these easy samples, we hallucinate multiple anchors to select hard samples for label correction. Corrected hard samples, along with the easy samples, are used as labeled data in subsequent semi-supervised training. Experiments on synthetic and real-world IDN datasets demonstrate the superior performance of our method over other state-of-the-art NLL methods.
Expert Composer Policy: Scalable Skill Repertoire for Quadruped Robots
Mar 18, 2024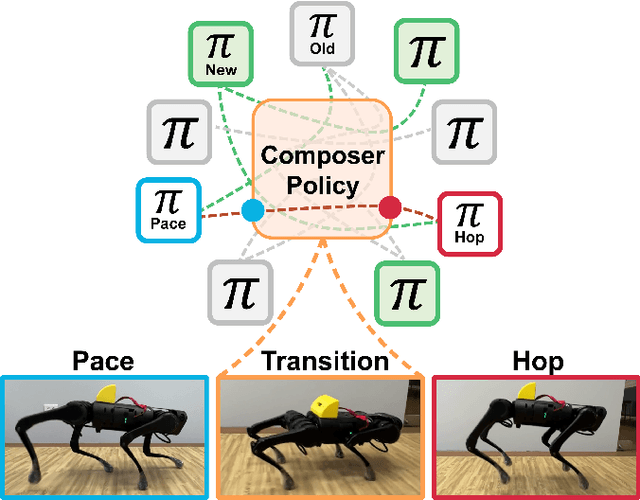
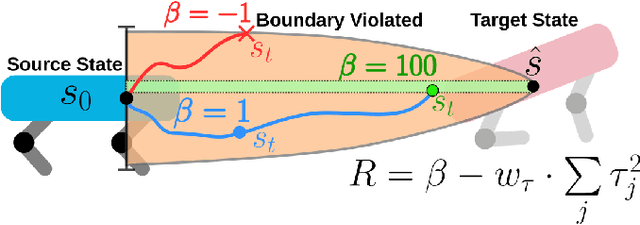

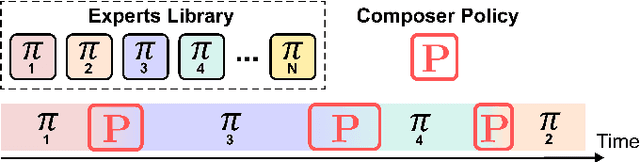
We propose the expert composer policy, a framework to reliably expand the skill repertoire of quadruped agents. The composer policy links pair of experts via transitions to a sampled target state, allowing experts to be composed sequentially. Each expert specializes in a single skill, such as a locomotion gait or a jumping motion. Instead of a hierarchical or mixture-of-experts architecture, we train a single composer policy in an independent process that is not conditioned on the other expert policies. By reusing the same composer policy, our approach enables adding new experts without affecting existing ones, enabling incremental repertoire expansion and preserving original motion quality. We measured the transition success rate of 72 transition pairs and achieved an average success rate of 99.99\%, which is over 10\% higher than the baseline random approach, and outperforms other state-of-the-art methods. Using domain randomization during training we ensure a successful transfer to the real world, where we achieve an average transition success rate of 97.22\% (N=360) in our experiments.
A Comprehensive Review of Machine Learning Advances on Data Change: A Cross-Field Perspective
Feb 20, 2024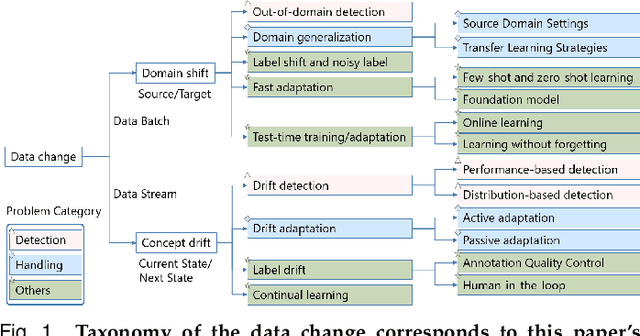
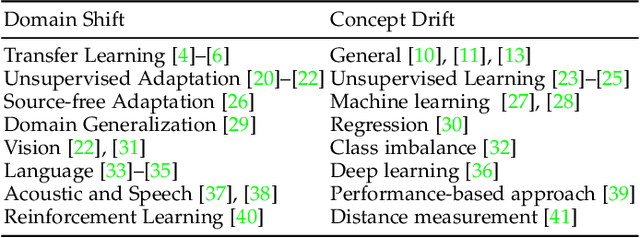
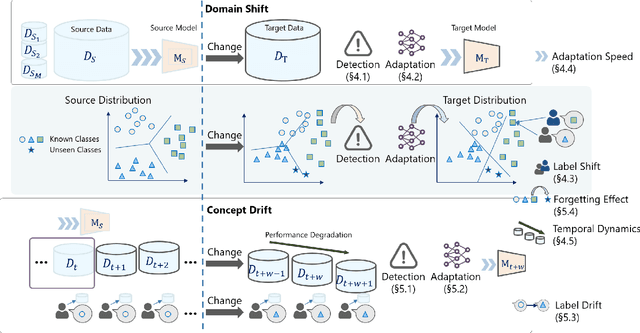
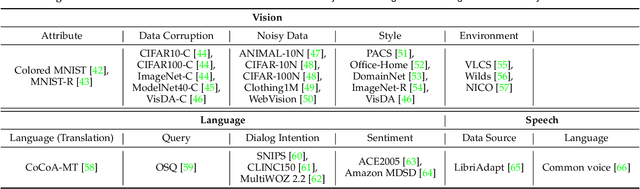
Recent artificial intelligence (AI) technologies show remarkable evolution in various academic fields and industries. However, in the real world, dynamic data lead to principal challenges for deploying AI models. An unexpected data change brings about severe performance degradation in AI models. We identify two major related research fields, domain shift and concept drift according to the setting of the data change. Although these two popular research fields aim to solve distribution shift and non-stationary data stream problems, the underlying properties remain similar which also encourages similar technical approaches. In this review, we regroup domain shift and concept drift into a single research problem, namely the data change problem, with a systematic overview of state-of-the-art methods in the two research fields. We propose a three-phase problem categorization scheme to link the key ideas in the two technical fields. We thus provide a novel scope for researchers to explore contemporary technical strategies, learn industrial applications, and identify future directions for addressing data change challenges.
Expanding Versatility of Agile Locomotion through Policy Transitions Using Latent State Representation
Jun 14, 2023
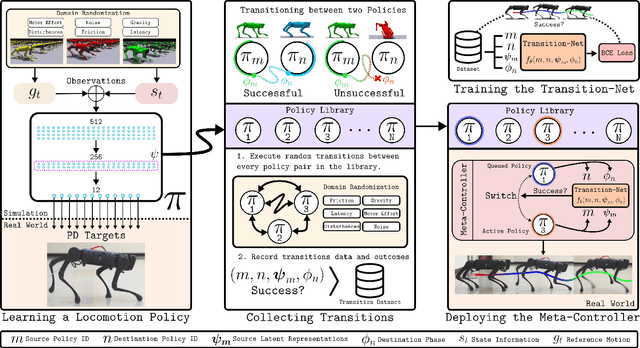
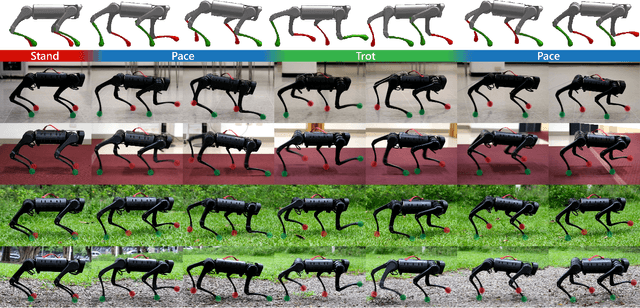
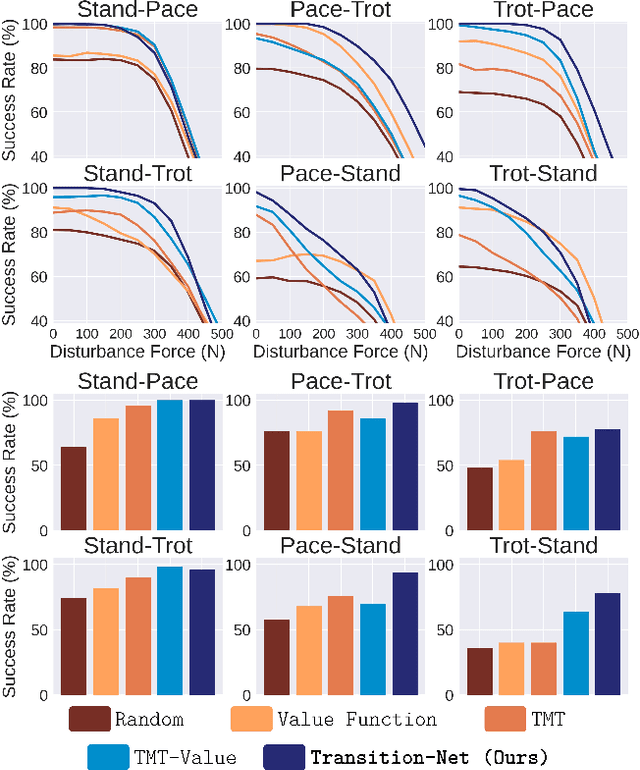
This paper proposes the transition-net, a robust transition strategy that expands the versatility of robot locomotion in the real-world setting. To this end, we start by distributing the complexity of different gaits into dedicated locomotion policies applicable to real-world robots. Next, we expand the versatility of the robot by unifying the policies with robust transitions into a single coherent meta-controller by examining the latent state representations. Our approach enables the robot to iteratively expand its skill repertoire and robustly transition between any policy pair in a library. In our framework, adding new skills does not introduce any process that alters the previously learned skills. Moreover, training of a locomotion policy takes less than an hour with a single consumer GPU. Our approach is effective in the real-world and achieves a 19% higher average success rate for the most challenging transition pairs in our experiments compared to existing approaches.
FedDig: Robust Federated Learning Using Data Digest to Represent Absent Clients
Oct 05, 2022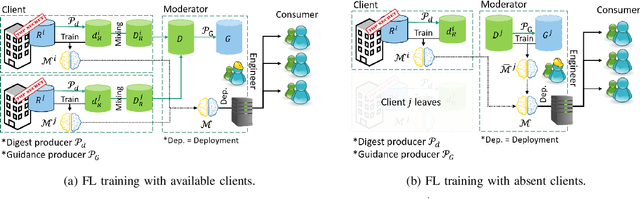
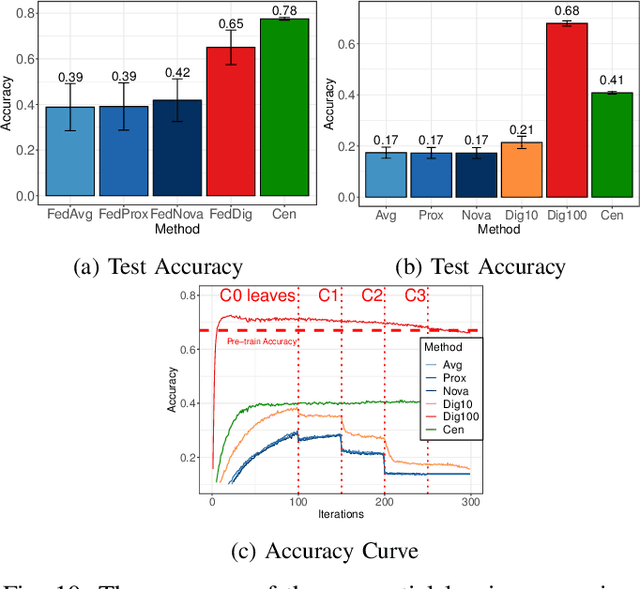
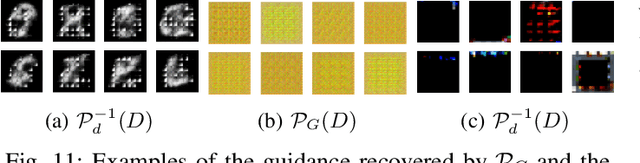
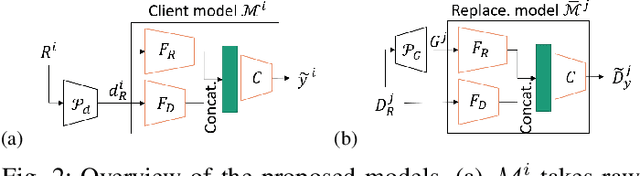
Federated Learning (FL) effectively protects client data privacy. However, client absence or leaving during training can seriously degrade model performances, particularly for unbalanced and non-IID client data. We address this issue by generating data digests from the raw data and using them to guide training at the FL moderator. The proposed FL framework, called FedDig, can tolerate unexpected client absence in cross-silo scenarios while preserving client data privacy because the digests de-identify the raw data by mixing encoded features in the features space. We evaluate FedDig using EMNIST, CIFAR-10, and CIFAR-100; the results consistently outperform against three baseline algorithms (FedAvg, FedProx, and FedNova) by large margins in various client absence scenarios.
Transition Motion Tensor: A Data-Driven Approach for Versatile and Controllable Agents in Physically Simulated Environments
Nov 30, 2021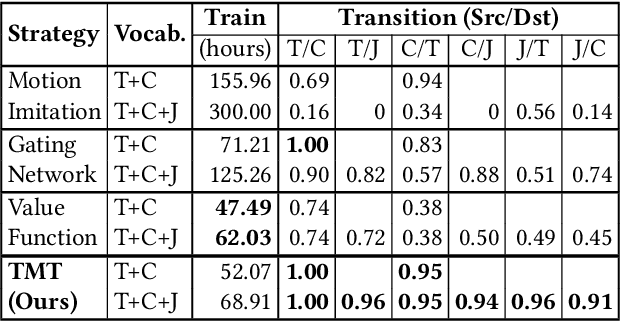
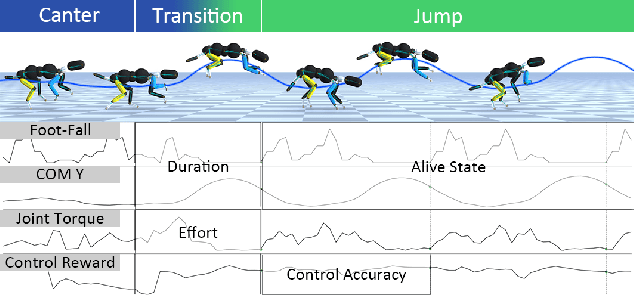
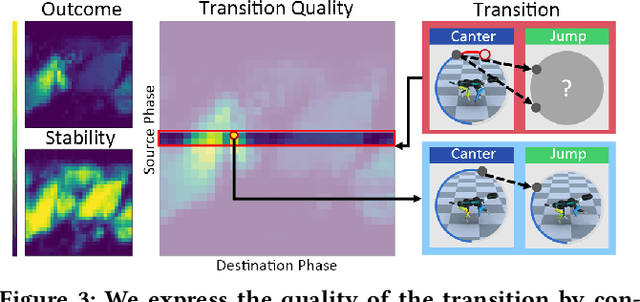
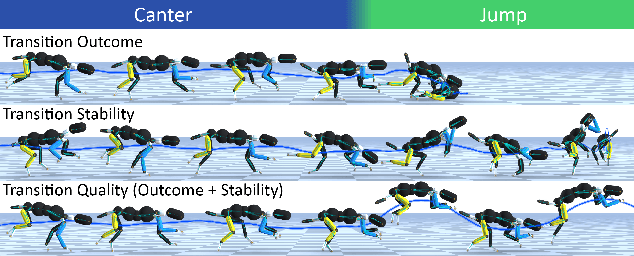
This paper proposes the Transition Motion Tensor, a data-driven framework that creates novel and physically accurate transitions outside of the motion dataset. It enables simulated characters to adopt new motion skills efficiently and robustly without modifying existing ones. Given several physically simulated controllers specializing in different motions, the tensor serves as a temporal guideline to transition between them. Through querying the tensor for transitions that best fit user-defined preferences, we can create a unified controller capable of producing novel transitions and solving complex tasks that may require multiple motions to work coherently. We apply our framework on both quadrupeds and bipeds, perform quantitative and qualitative evaluations on transition quality, and demonstrate its capability of tackling complex motion planning problems while following user control directives.