 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Symbolic Reasoning for Visual Narratives via Hierarchical and Semantically Normalized Knowledge Graphs
Aug 20, 2025Understanding visual narratives such as comics requires structured representations that capture events, characters, and their relations across multiple levels of story organization. However, symbolic narrative graphs often suffer from inconsistency and redundancy, where similar actions or events are labeled differently across annotations or contexts. Such variance limits the effectiveness of reasoning and generalization. This paper introduces a semantic normalization framework for hierarchical narrative knowledge graphs. Building on cognitively grounded models of narrative comprehension, we propose methods that consolidate semantically related actions and events using lexical similarity and embedding-based clustering. The normalization process reduces annotation noise, aligns symbolic categories across narrative levels, and preserves interpretability. We demonstrate the framework on annotated manga stories from the Manga109 dataset, applying normalization to panel-, event-, and story-level graphs. Preliminary evaluations across narrative reasoning tasks, such as action retrieval, character grounding, and event summarization, show that semantic normalization improves coherence and robustness, while maintaining symbolic transparency. These findings suggest that normalization is a key step toward scalable, cognitively inspired graph models for multimodal narrative understanding.
Collaborative Comic Generation: Integrating Visual Narrative Theories with AI Models for Enhanced Creativity
Sep 25, 2024



This study presents a theory-inspired visual narrative generative system that integrates conceptual principles-comic authoring idioms-with generative and language models to enhance the comic creation process. Our system combines human creativity with AI models to support parts of the generative process, providing a collaborative platform for creating comic content. These comic-authoring idioms, derived from prior human-created image sequences, serve as guidelines for crafting and refining storytelling. The system translates these principles into system layers that facilitate comic creation through sequential decision-making, addressing narrative elements such as panel composition, story tension changes, and panel transitions. Key contributions include integrating machine learning models into the human-AI cooperative comic generation process, deploying abstract narrative theories into AI-driven comic creation, and a customizable tool for narrative-driven image sequences. This approach improves narrative elements in generated image sequences and engages human creativity in an AI-generative process of comics. We open-source the code at https://github.com/RimiChen/Collaborative_Comic_Generation.
Intra-operative tumour margin evaluation in breast-conserving surgery with deep learning
Apr 16, 2024A positive margin may result in an increased risk of local recurrences after breast retention surgery for any malignant tumour. In order to reduce the number of positive margins would offer surgeon real-time intra-operative information on the presence of positive resection margins. This study aims to design an intra-operative tumour margin evaluation scheme by using specimen mammography in breast-conserving surgery. Total of 30 cases were evaluated and compared with the manually determined contours by experienced physicians and pathology report. The proposed method utilizes image thresholding to extract regions of interest and then performs a deep learning model, i.e. SegNet, to segment tumour tissue. The margin width of normal tissues surrounding it is evaluated as the result. The desired size of margin around the tumor was set for 10 mm. The smallest average difference to manual sketched margin (6.53 mm +- 5.84). In the all case, the SegNet architecture was utilized to obtain tissue specimen boundary and tumor contour, respectively. The simulation results indicated that this technology is helpful in discriminating positive from negative margins in the intra-operative setting. The aim of proposed scheme was a potential procedure in the intra-operative measurement system. The experimental results reveal that deep learning techniques can draw results that are consistent with pathology reports.
CPST: Comprehension-Preserving Style Transfer for Multi-Modal Narratives
Dec 14, 2023



We investigate the challenges of style transfer in multi-modal visual narratives. Among static visual narratives such as comics and manga, there are distinct visual styles in terms of presentation. They include style features across multiple dimensions, such as panel layout, size, shape, and color. They include both visual and text media elements. The layout of both text and media elements is also significant in terms of narrative communication. The sequential transitions between panels are where readers make inferences about the narrative world. These feature differences provide an interesting challenge for style transfer in which there are distinctions between the processing of features for each modality. We introduce the notion of comprehension-preserving style transfer (CPST) in such multi-modal domains. CPST requires not only traditional metrics of style transfer but also metrics of narrative comprehension. To spur further research in this area, we present an annotated dataset of comics and manga and an initial set of algorithms that utilize separate style transfer modules for the visual, textual, and layout parameters. To test whether the style transfer preserves narrative semantics, we evaluate this algorithm through visual story cloze tests inspired by work in computational cognition of narrative systems. Understanding the connection between style and narrative semantics provides insight for applications ranging from informational brochure designs to data storytelling.
Panel Transitions for Genre Analysis in Visual Narratives
Dec 14, 2023



Understanding how humans communicate and perceive narratives is important for media technology research and development. This is particularly important in current times when there are tools and algorithms that are easily available for amateur users to create high-quality content. Narrative media develops over time a set of recognizable patterns of features across similar artifacts. Genre is one such grouping of artifacts for narrative media with similar patterns, tropes, and story structures. While much work has been done on genre-based classifications in text and video, we present a novel approach to do a multi-modal analysis of genre based on comics and manga-style visual narratives. We present a systematic feature analysis of an annotated dataset that includes a variety of western and eastern visual books with annotations for high-level narrative patterns. We then present a detailed analysis of the contributions of high-level features to genre classification for this medium. We highlight some of the limitations and challenges of our existing computational approaches in modeling subjective labels. Our contributions to the community are: a dataset of annotated manga books, a multi-modal analysis of visual panels and text in a constrained and popular medium through high-level features, and a systematic process for incorporating subjective narrative patterns in computational models.
TrustMAE: A Noise-Resilient Defect Classification Framework using Memory-Augmented Auto-Encoders with Trust Regions
Dec 29, 2020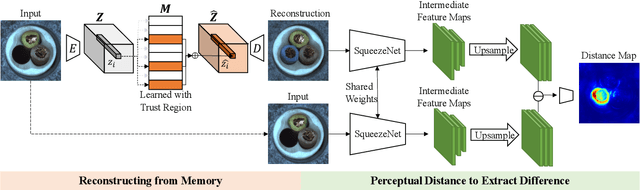
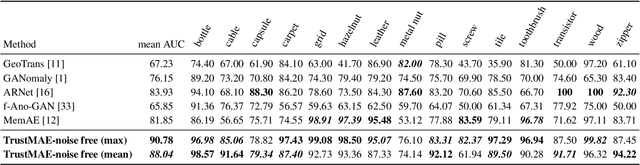
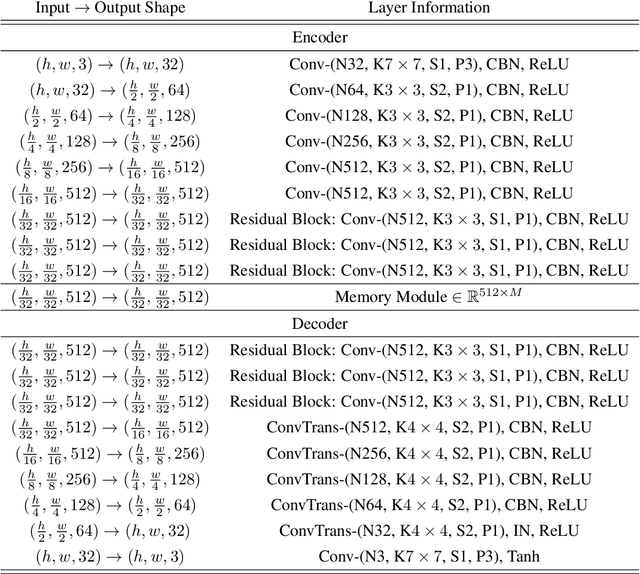
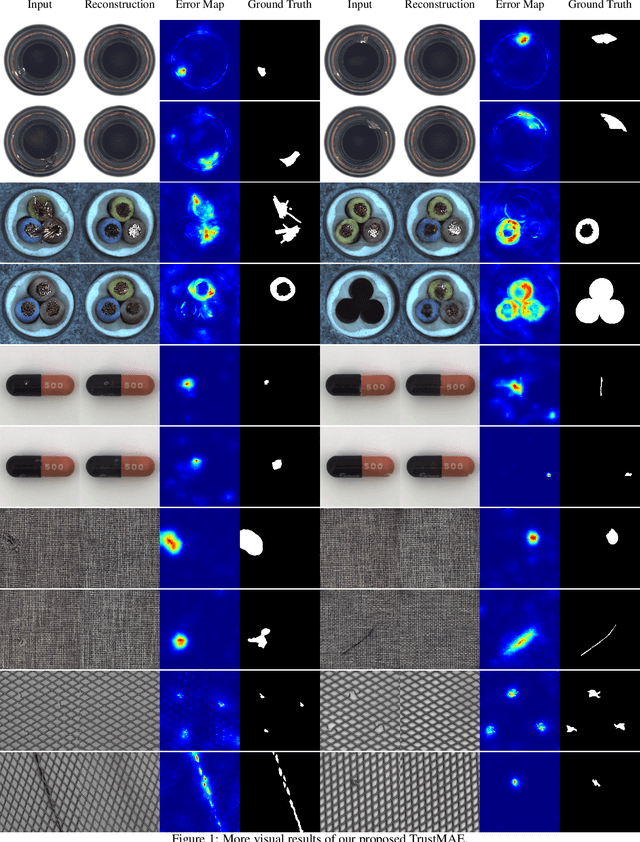
In this paper, we propose a framework called TrustMAE to address the problem of product defect classification. Instead of relying on defective images that are difficult to collect and laborious to label, our framework can accept datasets with unlabeled images. Moreover, unlike most anomaly detection methods, our approach is robust against noises, or defective images, in the training dataset. Our framework uses a memory-augmented auto-encoder with a sparse memory addressing scheme to avoid over-generalizing the auto-encoder, and a novel trust-region memory updating scheme to keep the noises away from the memory slots. The result is a framework that can reconstruct defect-free images and identify the defective regions using a perceptual distance network. When compared against various state-of-the-art baselines, our approach performs competitively under noise-free MVTec datasets. More importantly, it remains effective at a noise level up to 40% while significantly outperforming other baselines.
Investigating the Ground-level Ozone Formation and Future Trend in Taiwan
Dec 18, 2020
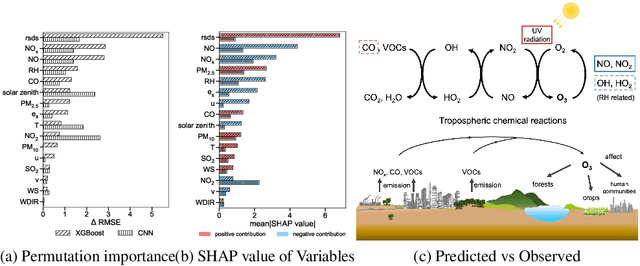
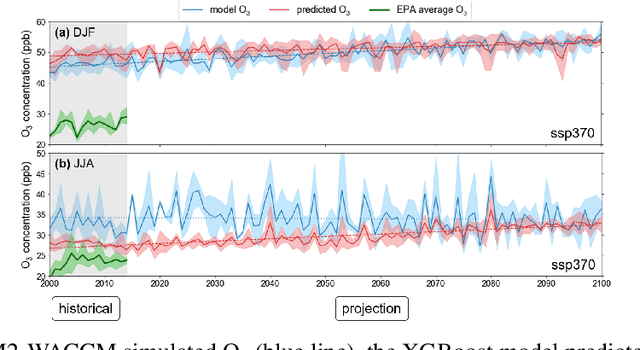
Tropospheric ozone (O3) is an influential ground-level air pollutant which can severely damage the environment. Thus evaluating the importance of various factors related to the O3 formation process is essential. However, O3 simulated by the available climate models exhibits large variance in different places, indicating the insufficiency of models in explaining the O3 formation process correctly. In this paper, we aim to understand the impact of various factors on O3 formation and predict the O3 concentrations. Six well-known supervised learning methods are evaluated to estimate the observed O3 using sixteen meteorological and chemical variables. We find that the XGBoost and the convolution neural network (CNN) models achieve most accurate predictions. We also demonstrate the importance of several variables empirically. The results suggest that while Nitrogen Oxides negatively contributes to predicting O3, the amount of solar radiation makes significantly positive contribution. Furthermore, we apply the XGBoost model on climate O3 prediction and show its competence in calibrating the O3 simulated by a global climate model.
Decision Forest: A Nonparametric Approach to Modeling Irrational Choice
Apr 25, 2019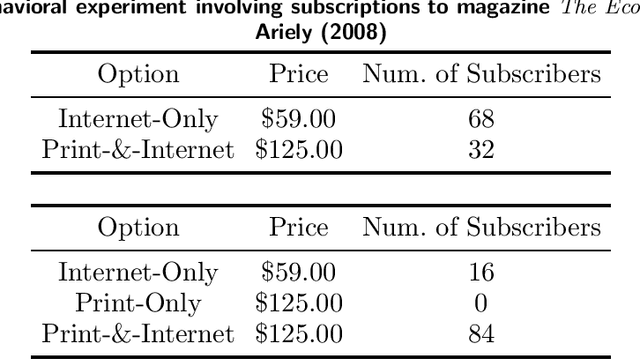
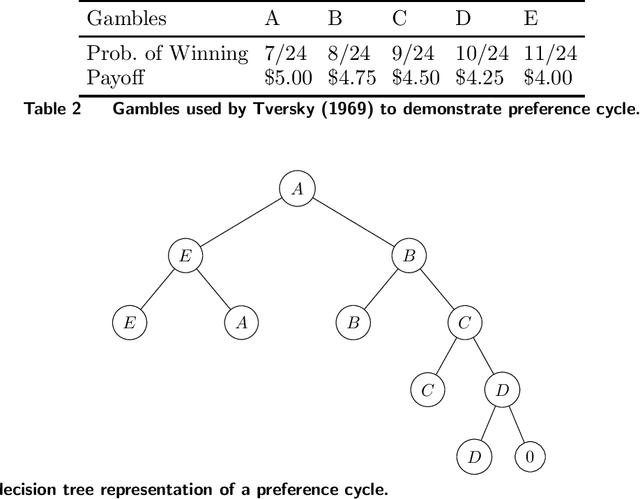
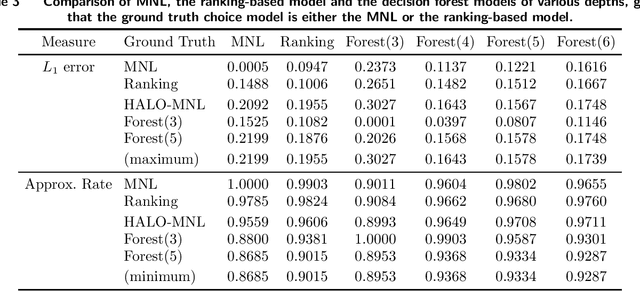
Customer behavior is often assumed to follow weak rationality, which implies that adding a product to an assortment will not increase the choice probability of another product in that assortment. However, an increasing amount of research has revealed that customers are not necessarily rational when making decisions. In this paper, we study a new nonparametric choice model that relaxes this assumption and can model a wider range of customer behavior, such as decoy effects between products. In this model, each customer type is associated with a binary decision tree, which represents a decision process for making a purchase based on checking for the existence of specific products in the assortment. Together with a probability distribution over customer types, we show that the resulting model -- a decision forest -- is able to represent any customer choice model, including models that are inconsistent with weak rationality. We theoretically characterize the depth of the forest needed to fit a data set of historical assortments and prove that asymptotically, a forest whose depth scales logarithmically in the number of assortments is sufficient to fit most data sets. We also propose an efficient algorithm for estimating such models from data, based on combining randomization and optimization. Using synthetic data and real transaction data exhibiting non-rational behavior, we show that the model outperforms the multinomial logit and ranking-based models in out-of-sample predictive ability.
Learning Discrete Bayesian Networks from Continuous Data
Sep 18, 2018
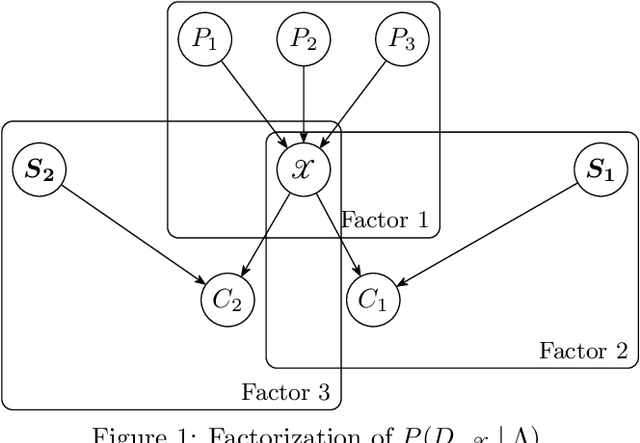
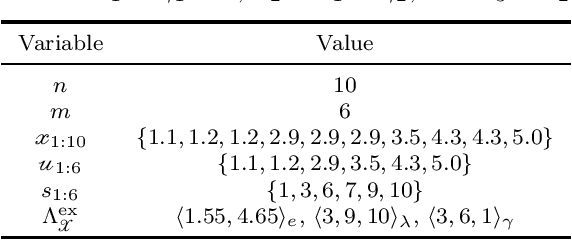

Learning Bayesian networks from raw data can help provide insights into the relationships between variables. While real data often contains a mixture of discrete and continuous-valued variables, many Bayesian network structure learning algorithms assume all random variables are discrete. Thus, continuous variables are often discretized when learning a Bayesian network. However, the choice of discretization policy has significant impact on the accuracy, speed, and interpretability of the resulting models. This paper introduces a principled Bayesian discretization method for continuous variables in Bayesian networks with quadratic complexity instead of the cubic complexity of other standard techniques. Empirical demonstrations show that the proposed method is superior to the established minimum description length algorithm. In addition, this paper shows how to incorporate existing methods into the structure learning process to discretize all continuous variables and simultaneously learn Bayesian network structures.
Self-view Grounding Given a Narrated 360° Video
Nov 23, 2017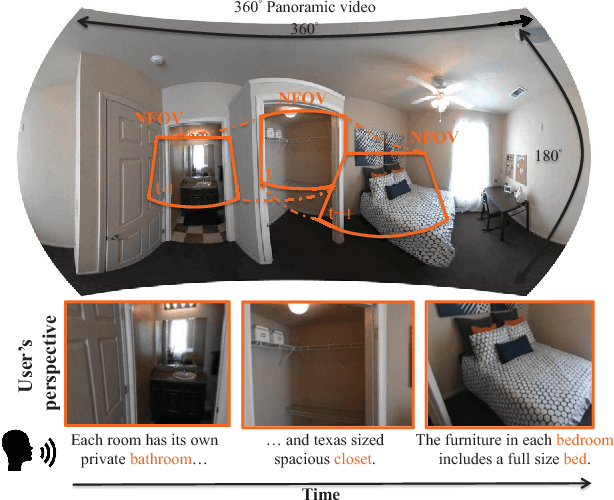
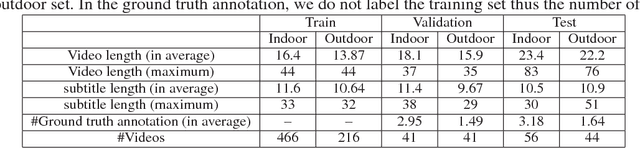
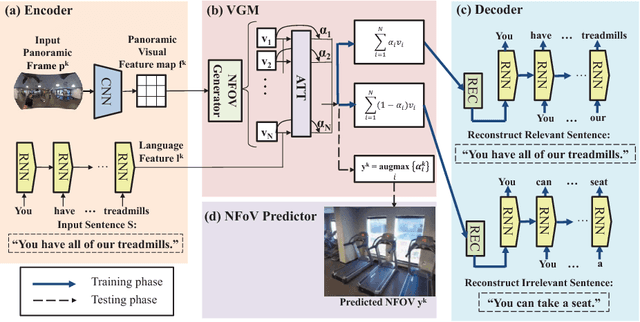
Narrated 360{\deg} videos are typically provided in many touring scenarios to mimic real-world experience. However, previous work has shown that smart assistance (i.e., providing visual guidance) can significantly help users to follow the Normal Field of View (NFoV) corresponding to the narrative. In this project, we aim at automatically grounding the NFoVs of a 360{\deg} video given subtitles of the narrative (referred to as "NFoV-grounding"). We propose a novel Visual Grounding Model (VGM) to implicitly and efficiently predict the NFoVs given the video content and subtitles. Specifically, at each frame, we efficiently encode the panorama into feature map of candidate NFoVs using a Convolutional Neural Network (CNN) and the subtitles to the same hidden space using an RNN with Gated Recurrent Units (GRU). Then, we apply soft-attention on candidate NFoVs to trigger sentence decoder aiming to minimize the reconstruct loss between the generated and given sentence. Finally, we obtain the NFoV as the candidate NFoV with the maximum attention without any human supervision. To train VGM more robustly, we also generate a reverse sentence conditioning on one minus the soft-attention such that the attention focuses on candidate NFoVs less relevant to the given sentence. The negative log reconstruction loss of the reverse sentence (referred to as "irrelevant loss") is jointly minimized to encourage the reverse sentence to be different from the given sentence. To evaluate our method, we collect the first narrated 360{\deg} videos dataset and achieve state-of-the-art NFoV-grounding performance.