 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI in Live Operations: Evidence of Productivity Gains in Cybersecurity and Endpoint Management
Apr 09, 2025



We measure the association between generative AI (GAI) tool adoption and four metrics spanning security operations, information protection, and endpoint management: 1) number of security alerts per incident, 2) probability of security incident reopenings, 3) time to classify a data loss prevention alert, and 4) time to resolve device policy conflicts. We find that GAI is associated with robust and statistically and practically significant improvements in the four metrics. Although unobserved confounders inhibit causal identification, these results are among the first to use observational data from live operations to investigate the relationship between GAI adoption and security operations, data loss prevention, and device policy management.
Local Model Explanations and Uncertainty Without Model Access
Jan 24, 2023We present a model-agnostic algorithm for generating post-hoc explanations and uncertainty intervals for a machine learning model when only a sample of inputs and outputs from the model is available, rather than direct access to the model itself. This situation may arise when model evaluations are expensive; when privacy, security and bandwidth constraints are imposed; or when there is a need for real-time, on-device explanations. Our algorithm constructs explanations using local polynomial regression and quantifies the uncertainty of the explanations using a bootstrapping approach. Through a simulation study, we show that the uncertainty intervals generated by our algorithm exhibit a favorable trade-off between interval width and coverage probability compared to the naive confidence intervals from classical regression analysis. We further demonstrate the capabilities of our method by applying it to black-box models trained on two real datasets.
Policy-focused Agent-based Modeling using RL Behavioral Models
Jun 09, 2020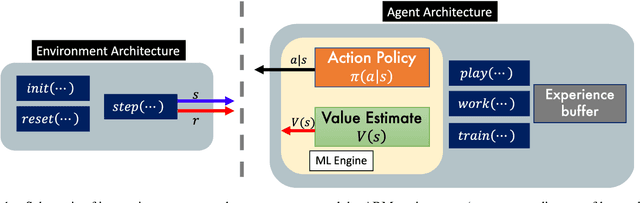
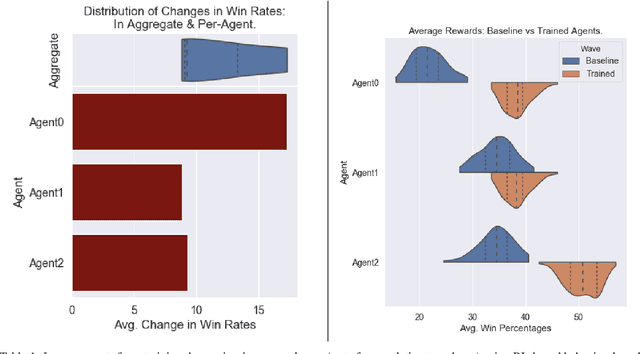
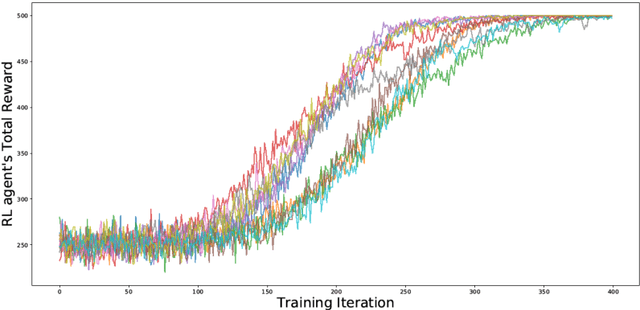
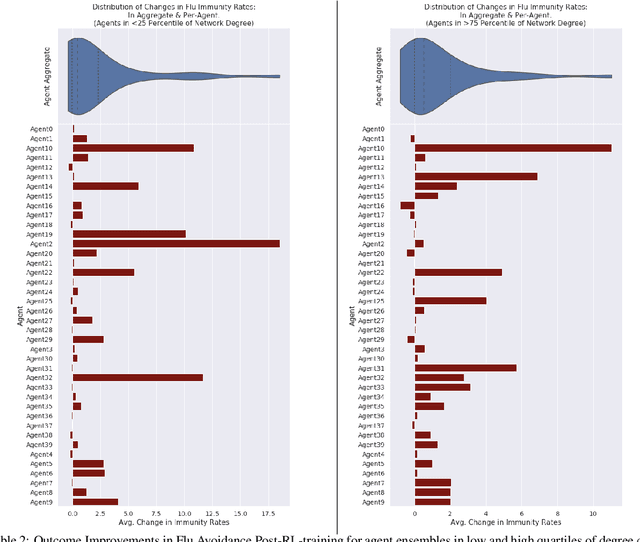
Agent-based Models (ABMs) are valuable tools for policy analysis. ABMs help analysts explore the emergent consequences of policy interventions in multi-agent decision-making settings. But the validity of inferences drawn from ABM explorations depends on the quality of the ABM agents' behavioral models. Standard specifications of agent behavioral models rely either on heuristic decision-making rules or on regressions trained on past data. Both prior specification modes have limitations. This paper examines the value of reinforcement learning (RL) models as adaptive, high-performing, and behaviorally-valid models of agent decision-making in ABMs. We test the hypothesis that RL agents are effective as utility-maximizing agents in policy ABMs. We also address the problem of adapting RL algorithms to handle multi-agency in games by adapting and extending methods from recent literature. We evaluate the performance of such RL-based ABM agents via experiments on two policy-relevant ABMs: a minority game ABM, and an ABM of Influenza Transmission. We run some analytic experiments on our AI-equipped ABMs e.g. explorations of the effects of behavioral heterogeneity in a population and the emergence of synchronization in a population. The experiments show that RL behavioral models are effective at producing reward-seeking or reward-maximizing behaviors in ABM agents. Furthermore, RL behavioral models can learn to outperform the default adaptive behavioral models in the two ABMs examined.
Perturbing Inputs to Prevent Model Stealing
May 12, 2020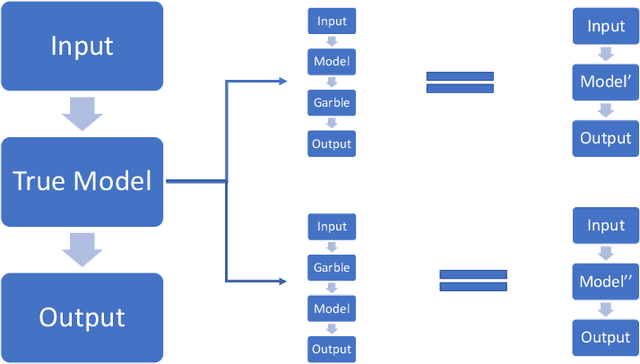
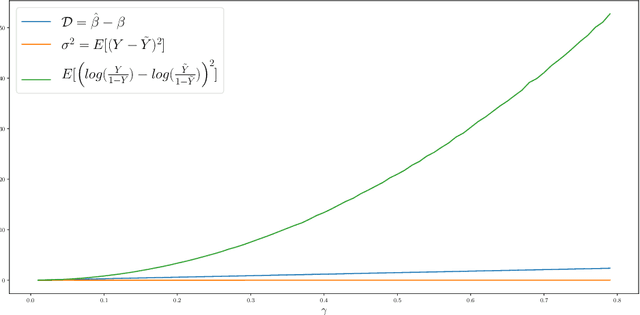
We show how perturbing inputs to machine learning services (ML-service) deployed in the cloud can protect against model stealing attacks. In our formulation, there is an ML-service that receives inputs from users and returns the output of the model. There is an attacker that is interested in learning the parameters of the ML-service. We use the linear and logistic regression models to illustrate how strategically adding noise to the inputs fundamentally alters the attacker's estimation problem. We show that even with infinite samples, the attacker would not be able to recover the true model parameters. We focus on characterizing the trade-off between the error in the attacker's estimate of the parameters with the error in the ML-service's output.
Deep Reinforcement Learning for Event-Driven Multi-Agent Decision Processes
Sep 19, 2017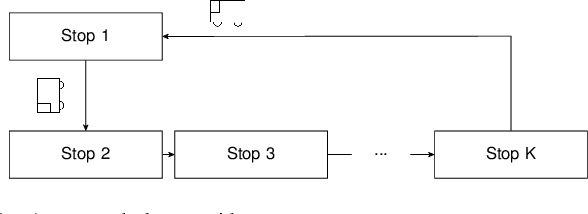
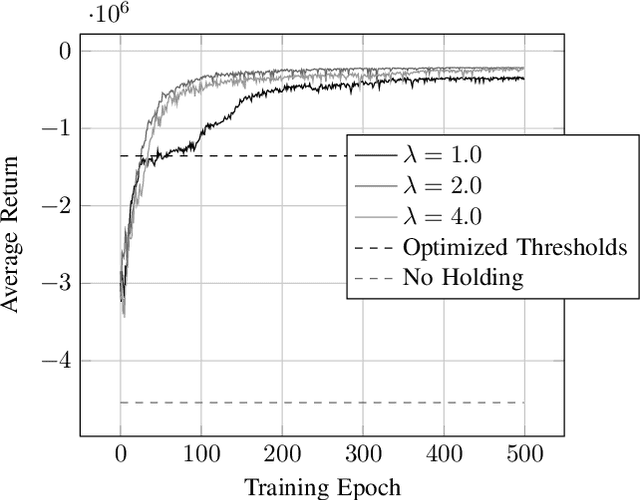
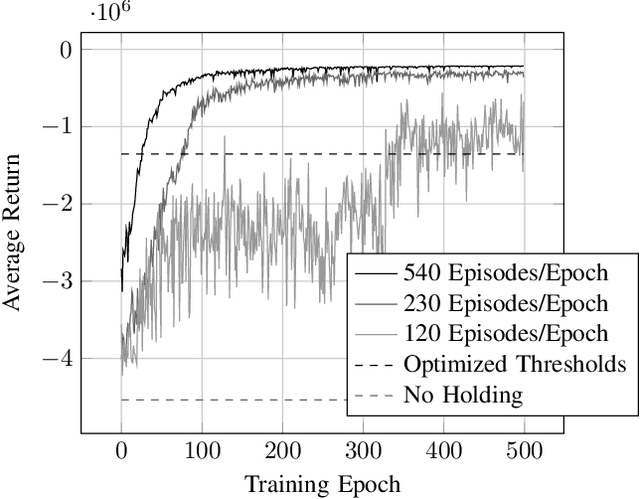
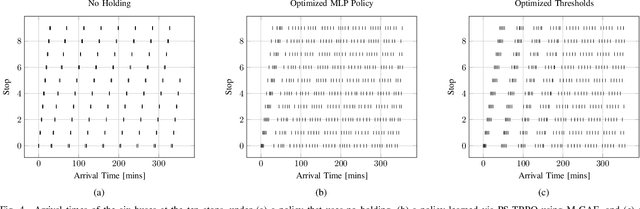
The incorporation of macro-actions (temporally extended actions) into multi-agent decision problems has the potential to address the curse of dimensionality associated with such decision problems. Since macro-actions last for stochastic durations, multiple agents executing decentralized policies in cooperative environments must act asynchronously. We present an algorithm that modifies Generalized Advantage Estimation for temporally extended actions, allowing a state-of-the-art policy optimization algorithm to optimize policies in Dec-POMDPs in which agents act asynchronously. We show that our algorithm is capable of learning optimal policies in two cooperative domains, one involving real-time bus holding control and one involving wildfire fighting with unmanned aircraft. Our algorithm works by framing problems as "event-driven decision processes," which are scenarios where the sequence and timing of actions and events are random and governed by an underlying stochastic process. In addition to optimizing policies with continuous state and action spaces, our algorithm also facilitates the use of event-driven simulators, which do not require time to be discretized into time-steps. We demonstrate the benefit of using event-driven simulation in the context of multiple agents taking asynchronous actions. We show that fixed time-step simulation risks obfuscating the sequence in which closely-separated events occur, adversely affecting the policies learned. Additionally, we show that arbitrarily shrinking the time-step scales poorly with the number of agents.