 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Generative Modeling in Network Science with Applications to Public Policy Research
Oct 16, 2020

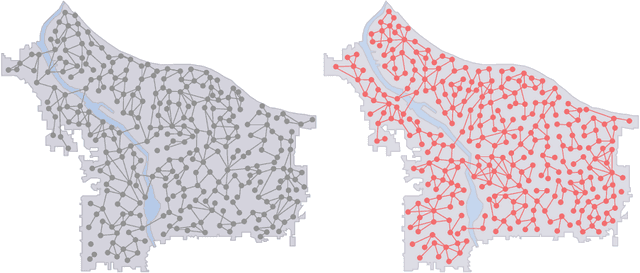
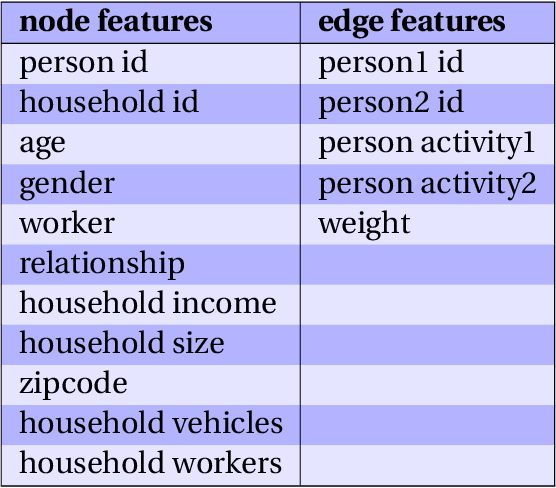
Network data is increasingly being used in quantitative, data-driven public policy research. These are typically very rich datasets that contain complex correlations and inter-dependencies. This richness both promises to be quite useful for policy research, while at the same time posing a challenge for the useful extraction of information from these datasets - a challenge which calls for new data analysis methods. In this report, we formulate a research agenda of key methodological problems whose solutions would enable new advances across many areas of policy research. We then review recent advances in applying deep learning to network data, and show how these methods may be used to address many of the methodological problems we identified. We particularly emphasize deep generative methods, which can be used to generate realistic synthetic networks useful for microsimulation and agent-based models capable of informing key public policy questions. We extend these recent advances by developing a new generative framework which applies to large social contact networks commonly used in epidemiological modeling. For context, we also compare and contrast these recent neural network-based approaches with the more traditional Exponential Random Graph Models. Lastly, we discuss some open problems where more progress is needed.
A Generative Machine Learning Approach to Policy Optimization in Pursuit-Evasion Games
Oct 13, 2020
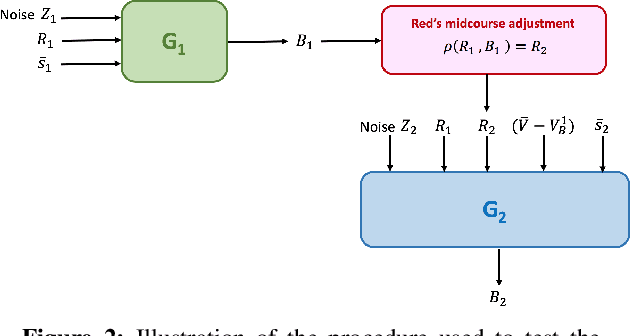
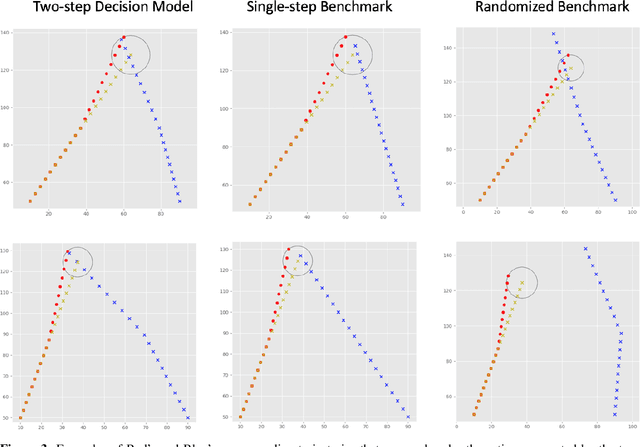

We consider a pursuit-evasion game [11] played between two agents, 'Blue' (the pursuer) and 'Red' (the evader), over $T$ time steps. Red aims to attack Blue's territory. Blue's objective is to intercept Red by time $T$ and thereby limit the success of Red's attack. Blue must plan its pursuit trajectory by choosing parameters that determine its course of movement (speed and angle in our setup) such that it intercepts Red by time $T$. We show that Blue's path-planning problem in pursuing Red, can be posed as a sequential decision making problem under uncertainty. Blue's unawareness of Red's action policy renders the analytic dynamic programming approach intractable for finding the optimal action policy for Blue. In this work, we are interested in exploring data-driven approaches to the policy optimization problem that Blue faces. We apply generative machine learning (ML) approaches to learn optimal action policies for Blue. This highlights the ability of generative ML model to learn the relevant implicit representations for the dynamics of simulated pursuit-evasion games. We demonstrate the effectiveness of our modeling approach via extensive statistical assessments. This work can be viewed as a preliminary step towards further adoption of generative modeling approaches for addressing policy optimization problems that arise in the context of multi-agent learning and planning [1].
Policy-focused Agent-based Modeling using RL Behavioral Models
Jun 09, 2020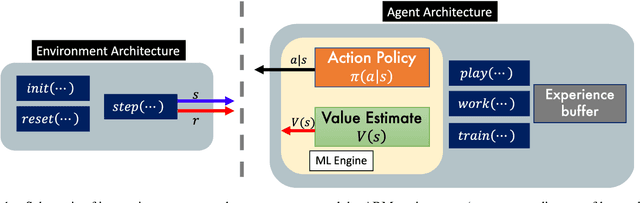
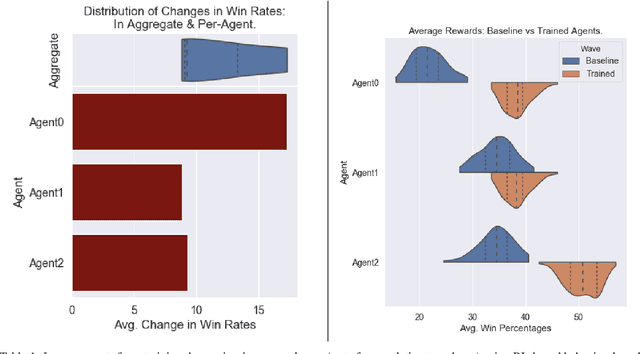
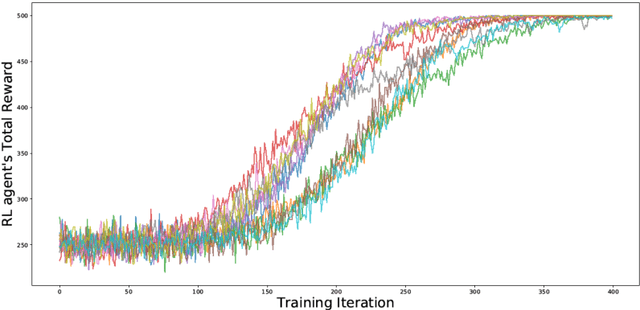
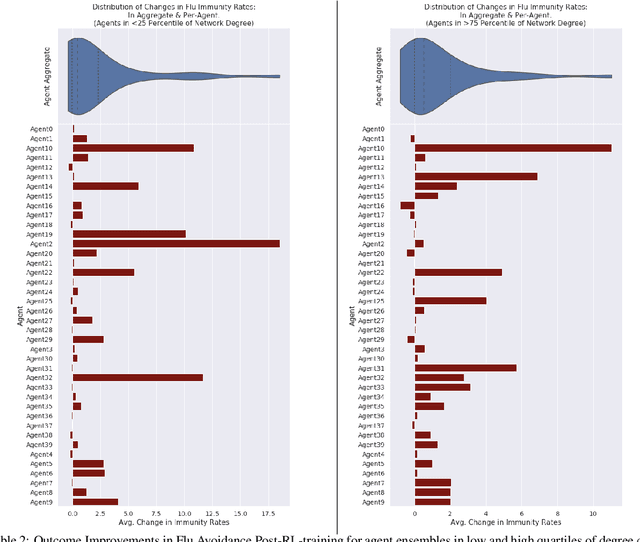
Agent-based Models (ABMs) are valuable tools for policy analysis. ABMs help analysts explore the emergent consequences of policy interventions in multi-agent decision-making settings. But the validity of inferences drawn from ABM explorations depends on the quality of the ABM agents' behavioral models. Standard specifications of agent behavioral models rely either on heuristic decision-making rules or on regressions trained on past data. Both prior specification modes have limitations. This paper examines the value of reinforcement learning (RL) models as adaptive, high-performing, and behaviorally-valid models of agent decision-making in ABMs. We test the hypothesis that RL agents are effective as utility-maximizing agents in policy ABMs. We also address the problem of adapting RL algorithms to handle multi-agency in games by adapting and extending methods from recent literature. We evaluate the performance of such RL-based ABM agents via experiments on two policy-relevant ABMs: a minority game ABM, and an ABM of Influenza Transmission. We run some analytic experiments on our AI-equipped ABMs e.g. explorations of the effects of behavioral heterogeneity in a population and the emergence of synchronization in a population. The experiments show that RL behavioral models are effective at producing reward-seeking or reward-maximizing behaviors in ABM agents. Furthermore, RL behavioral models can learn to outperform the default adaptive behavioral models in the two ABMs examined.