 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generative Machine Learning Approach to Policy Optimization in Pursuit-Evasion Games
Oct 13, 2020
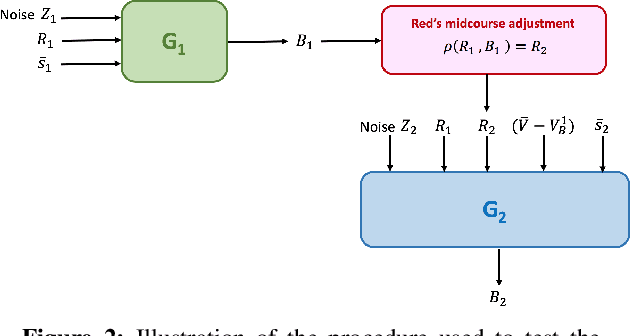
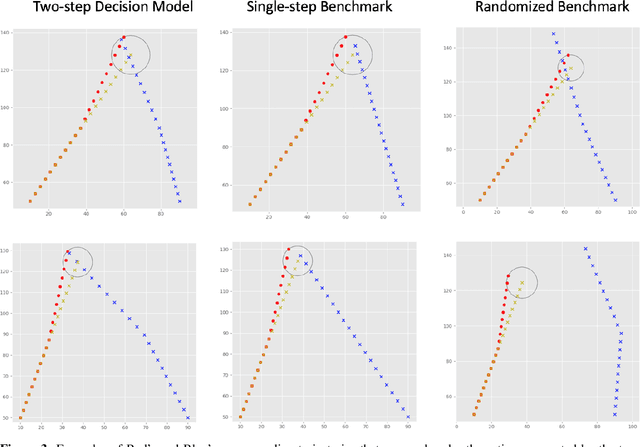

We consider a pursuit-evasion game [11] played between two agents, 'Blue' (the pursuer) and 'Red' (the evader), over $T$ time steps. Red aims to attack Blue's territory. Blue's objective is to intercept Red by time $T$ and thereby limit the success of Red's attack. Blue must plan its pursuit trajectory by choosing parameters that determine its course of movement (speed and angle in our setup) such that it intercepts Red by time $T$. We show that Blue's path-planning problem in pursuing Red, can be posed as a sequential decision making problem under uncertainty. Blue's unawareness of Red's action policy renders the analytic dynamic programming approach intractable for finding the optimal action policy for Blue. In this work, we are interested in exploring data-driven approaches to the policy optimization problem that Blue faces. We apply generative machine learning (ML) approaches to learn optimal action policies for Blue. This highlights the ability of generative ML model to learn the relevant implicit representations for the dynamics of simulated pursuit-evasion games. We demonstrate the effectiveness of our modeling approach via extensive statistical assessments. This work can be viewed as a preliminary step towards further adoption of generative modeling approaches for addressing policy optimization problems that arise in the context of multi-agent learning and planning [1].