 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized Controlled Trials for Phishing Triage Agent
Nov 17, 2025Security operations centers (SOCs) face a persistent challenge: efficiently triaging a high volume of user-reported phishing emails while maintaining robust protection against threats. This paper presents the first randomized controlled trial (RCT) evaluating the impact of a domain-specific AI agent - the Microsoft Security Copilot Phishing Triage Agent - on analyst productivity and accuracy. Our results demonstrate that agent-augmented analysts achieved up to 6.5 times as many true positives per analyst minute and a 77% improvement in verdict accuracy compared to a control group. The agent's queue prioritization and verdict explanations were both significant drivers of efficiency. Behavioral analysis revealed that agent-augmented analysts reallocated their attention, spending 53% more time on malicious emails, and were not prone to rubber-stamping the agent's malicious verdicts. These findings offer actionable insights for SOC leaders considering AI adoption, including the potential for agents to fundamentally change the optimal allocation of SOC resources.
Randomized Controlled Trials for Conditional Access Optimization Agent
Nov 17, 2025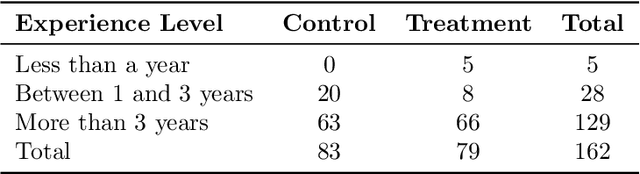



AI agents are increasingly deployed to automate complex enterprise workflows, yet evidence of their effectiveness in identity governance is limited. We report results from the first randomized controlled trial (RCT) evaluating an AI agent for Conditional Access (CA) policy management in Microsoft Entra. The agent assists with four high-value tasks: policy merging, Zero-Trust baseline gap detection, phased rollout planning, and user-policy alignment. In a production-grade environment, 162 identity administrators were randomly assigned to a control group (no agent) or treatment group (agent-assisted) and asked to perform these tasks. Agent access produced substantial gains: accuracy improved by 48% and task completion time decreased by 43% while holding accuracy constant. The largest benefits emerged on cognitively demanding tasks such as baseline gap detection. These findings demonstrate that purpose-built AI agents can significantly enhance both speed and accuracy in identity administration.
Generative AI in Live Operations: Evidence of Productivity Gains in Cybersecurity and Endpoint Management
Apr 09, 2025



We measure the association between generative AI (GAI) tool adoption and four metrics spanning security operations, information protection, and endpoint management: 1) number of security alerts per incident, 2) probability of security incident reopenings, 3) time to classify a data loss prevention alert, and 4) time to resolve device policy conflicts. We find that GAI is associated with robust and statistically and practically significant improvements in the four metrics. Although unobserved confounders inhibit causal identification, these results are among the first to use observational data from live operations to investigate the relationship between GAI adoption and security operations, data loss prevention, and device policy management.
Examining the robustness of LLM evaluation to the distributional assumptions of benchmarks
Apr 25, 2024

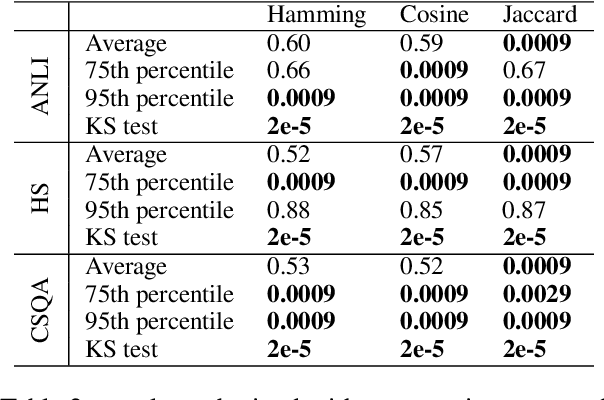

Benchmarks have emerged as the central approach for evaluating Large Language Models (LLMs). The research community often relies on a model's average performance across the test prompts of a benchmark to evaluate the model's performance. This is consistent with the assumption that the test prompts within a benchmark represent a random sample from a real-world distribution of interest. We note that this is generally not the case; instead, we hold that the distribution of interest varies according to the specific use case. We find that (1) the correlation in model performance across test prompts is non-random, (2) accounting for correlations across test prompts can change model rankings on major benchmarks, (3) explanatory factors for these correlations include semantic similarity and common LLM failure points.