 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining the robustness of LLM evaluation to the distributional assumptions of benchmarks
Apr 25, 2024

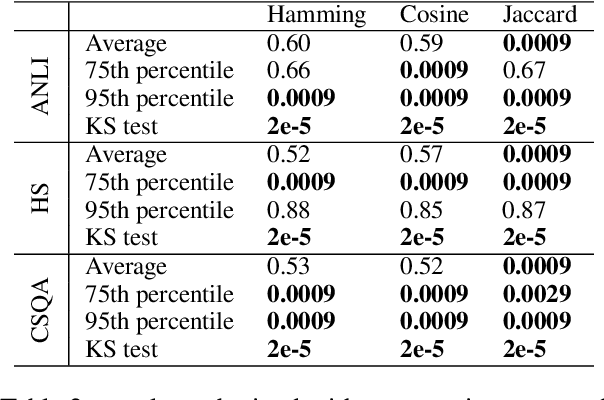

Benchmarks have emerged as the central approach for evaluating Large Language Models (LLMs). The research community often relies on a model's average performance across the test prompts of a benchmark to evaluate the model's performance. This is consistent with the assumption that the test prompts within a benchmark represent a random sample from a real-world distribution of interest. We note that this is generally not the case; instead, we hold that the distribution of interest varies according to the specific use case. We find that (1) the correlation in model performance across test prompts is non-random, (2) accounting for correlations across test prompts can change model rankings on major benchmarks, (3) explanatory factors for these correlations include semantic similarity and common LLM failure points.
Lingua Custodia's participation at the WMT 2021 Machine Translation using Terminologies shared task
Nov 03, 2021
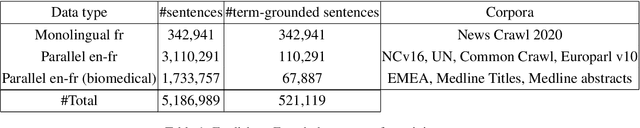


This paper describes Lingua Custodia's submission to the WMT21 shared task on machine translation using terminologies. We consider three directions, namely English to French, Russian, and Chinese. We rely on a Transformer-based architecture as a building block, and we explore a method which introduces two main changes to the standard procedure to handle terminologies. The first one consists in augmenting the training data in such a way as to encourage the model to learn a copy behavior when it encounters terminology constraint terms. The second change is constraint token masking, whose purpose is to ease copy behavior learning and to improve model generalization. Empirical results show that our method satisfies most terminology constraints while maintaining high translation quality.
Encouraging Neural Machine Translation to Satisfy Terminology Constraints
Jun 07, 2021
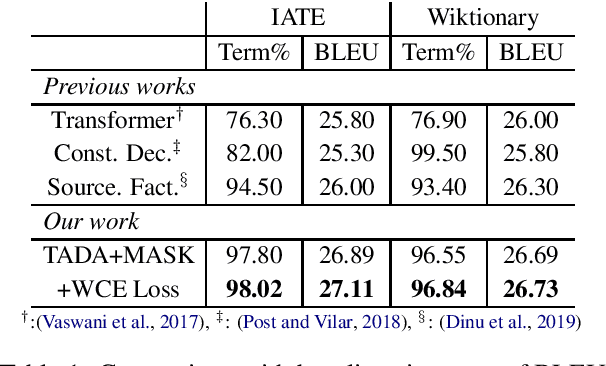


We present a new approach to encourage neural machine translation to satisfy lexical constraints. Our method acts at the training step and thereby avoiding the introduction of any extra computational overhead at inference step. The proposed method combines three main ingredients. The first one consists in augmenting the training data to specify the constraints. Intuitively, this encourages the model to learn a copy behavior when it encounters constraint terms. Compared to previous work, we use a simplified augmentation strategy without source factors. The second ingredient is constraint token masking, which makes it even easier for the model to learn the copy behavior and generalize better. The third one, is a modification of the standard cross entropy loss to bias the model towards assigning high probabilities to constraint words. Empirical results show that our method improves upon related baselines in terms of both BLEU score and the percentage of generated constraint terms.
Topic Augmented Generator for Abstractive Summarization
Aug 19, 2019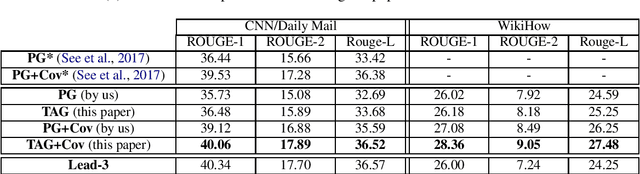


Steady progress has been made in abstractive summarization with attention-based sequence-to-sequence learning models. In this paper, we propose a new decoder where the output summary is generated by conditioning on both the input text and the latent topics of the document. The latent topics, identified by a topic model such as LDA, reveals more global semantic information that can be used to bias the decoder to generate words. In particular, they enable the decoder to have access to additional word co-occurrence statistics captured at document corpus level. We empirically validate the advantage of the proposed approach on both the CNN/Daily Mail and the WikiHow datasets. Concretely, we attain strongly improved ROUGE scores when compared to state-of-the-art models.
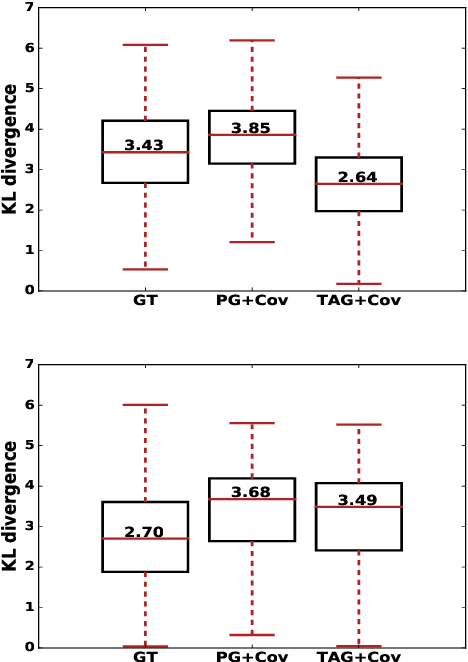
Amortized Inference of Variational Bounds for Learning Noisy-OR
Jun 06, 2019

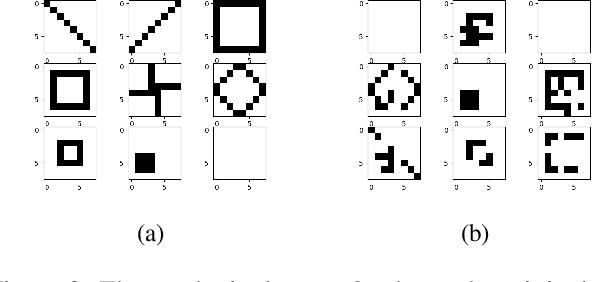
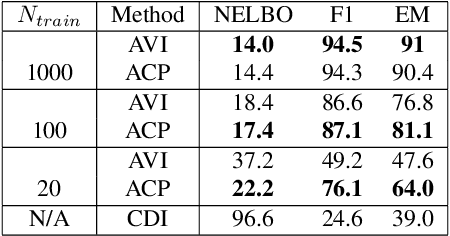
Classical approaches for approximate inference depend on cleverly designed variational distributions and bounds. Modern approaches employ amortized variational inference, which uses a neural network to approximate any posterior without leveraging the structures of the generative models. In this paper, we propose Amortized Conjugate Posterior (ACP), a hybrid approach taking advantages of both types of approaches. Specifically, we use the classical methods to derive specific forms of posterior distributions and then learn the variational parameters using amortized inference. We study the effectiveness of the proposed approach on the Noisy-OR model and compare to both the classical and the modern approaches for approximate inference and parameter learning. Our results show that ACP outperforms other methods when there is a limited amount of training data.