 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe LLM Pro Finance Suite: Multilingual Large Language Models for Financial Applications
Nov 07, 2025The financial industry's growing demand for advanced natural language processing (NLP) capabilities has highlighted the limitations of generalist large language models (LLMs) in handling domain-specific financial tasks. To address this gap, we introduce the LLM Pro Finance Suite, a collection of five instruction-tuned LLMs (ranging from 8B to 70B parameters) specifically designed for financial applications. Our approach focuses on enhancing generalist instruction-tuned models, leveraging their existing strengths in instruction following, reasoning, and toxicity control, while fine-tuning them on a curated, high-quality financial corpus comprising over 50% finance-related data in English, French, and German. We evaluate the LLM Pro Finance Suite on a comprehensive financial benchmark suite, demonstrating consistent improvement over state-of-the-art baselines in finance-oriented tasks and financial translation. Notably, our models maintain the strong general-domain capabilities of their base models, ensuring reliable performance across non-specialized tasks. This dual proficiency, enhanced financial expertise without compromise on general abilities, makes the LLM Pro Finance Suite an ideal drop-in replacement for existing LLMs in financial workflows, offering improved domain-specific performance while preserving overall versatility. We publicly release two 8B-parameters models to foster future research and development in financial NLP applications: https://huggingface.co/collections/DragonLLM/llm-open-finance.
DOLFIN -- Document-Level Financial test set for Machine Translation
Feb 05, 2025Despite the strong research interest in document-level Machine Translation (MT), the test sets dedicated to this task are still scarce. The existing test sets mainly cover topics from the general domain and fall short on specialised domains, such as legal and financial. Also, in spite of their document-level aspect, they still follow a sentence-level logic that does not allow for including certain linguistic phenomena such as information reorganisation. In this work, we aim to fill this gap by proposing a novel test set: DOLFIN. The dataset is built from specialised financial documents, and it makes a step towards true document-level MT by abandoning the paradigm of perfectly aligned sentences, presenting data in units of sections rather than sentences. The test set consists of an average of 1950 aligned sections for five language pairs. We present a detailed data collection pipeline that can serve as inspiration for aligning new document-level datasets. We demonstrate the usefulness and quality of this test set by evaluating a number of models. Our results show that the test set is able to discriminate between context-sensitive and context-agnostic models and shows the weaknesses when models fail to accurately translate financial texts. The test set is made public for the community.
Large Language Model Adaptation for Financial Sentiment Analysis
Jan 26, 2024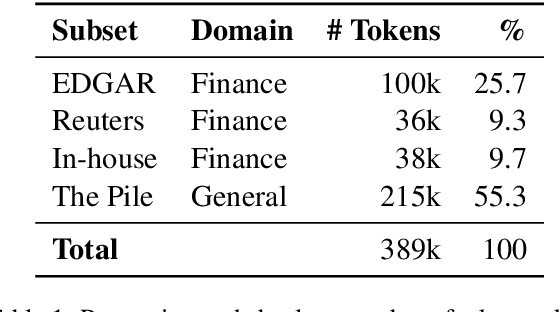

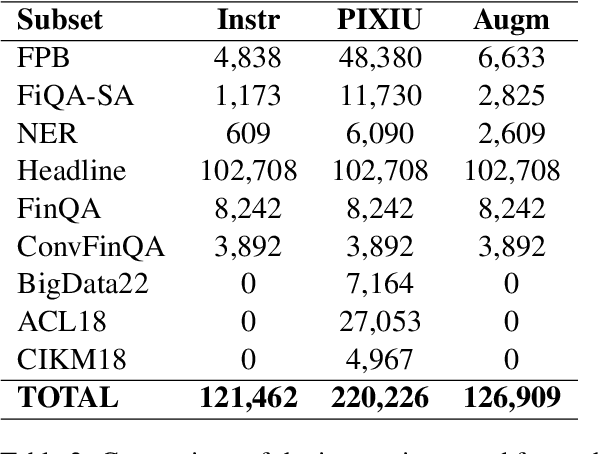
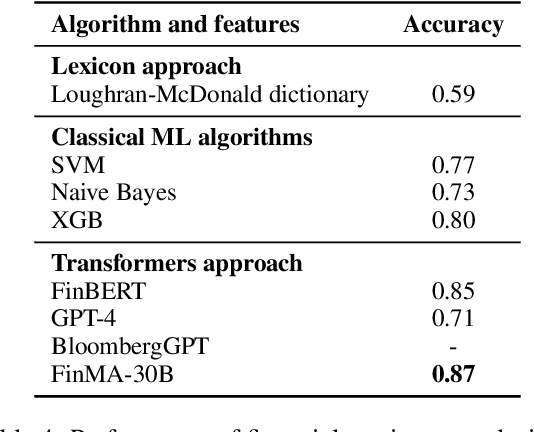
Natural language processing (NLP) has recently gained relevance within financial institutions by providing highly valuable insights into companies and markets' financial documents. However, the landscape of the financial domain presents extra challenges for NLP, due to the complexity of the texts and the use of specific terminology. Generalist language models tend to fall short in tasks specifically tailored for finance, even when using large language models (LLMs) with great natural language understanding and generative capabilities. This paper presents a study on LLM adaptation methods targeted at the financial domain and with high emphasis on financial sentiment analysis. To this purpose, two foundation models with less than 1.5B parameters have been adapted using a wide range of strategies. We show that through careful fine-tuning on both financial documents and instructions, these foundation models can be adapted to the target domain. Moreover, we observe that small LLMs have comparable performance to larger scale models, while being more efficient in terms of parameters and data. In addition to the models, we show how to generate artificial instructions through LLMs to augment the number of samples of the instruction dataset.
Lingua Custodia's participation at the WMT 2021 Machine Translation using Terminologies shared task
Nov 03, 2021
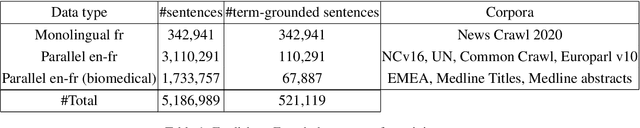


This paper describes Lingua Custodia's submission to the WMT21 shared task on machine translation using terminologies. We consider three directions, namely English to French, Russian, and Chinese. We rely on a Transformer-based architecture as a building block, and we explore a method which introduces two main changes to the standard procedure to handle terminologies. The first one consists in augmenting the training data in such a way as to encourage the model to learn a copy behavior when it encounters terminology constraint terms. The second change is constraint token masking, whose purpose is to ease copy behavior learning and to improve model generalization. Empirical results show that our method satisfies most terminology constraints while maintaining high translation quality.
Neural Medication Extraction: A Comparison of Recent Models in Supervised and Semi-supervised Learning Settings
Oct 19, 2021

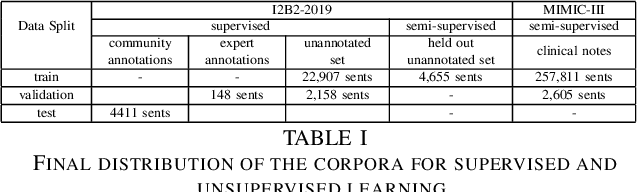
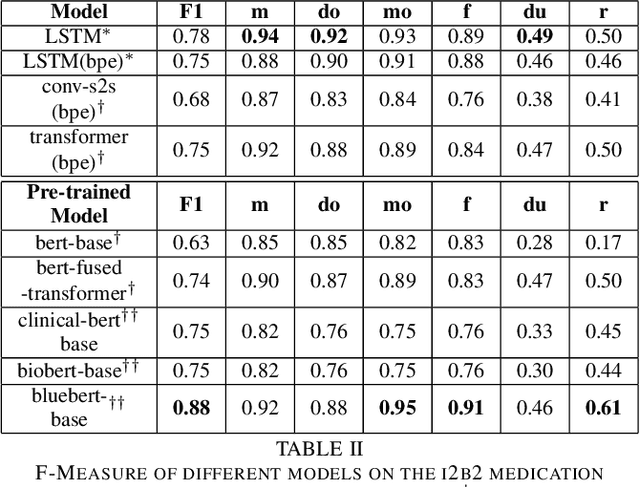
Drug prescriptions are essential information that must be encoded in electronic medical records. However, much of this information is hidden within free-text reports. This is why the medication extraction task has emerged. To date, most of the research effort has focused on small amount of data and has only recently considered deep learning methods. In this paper, we present an independent and comprehensive evaluation of state-of-the-art neural architectures on the I2B2 medical prescription extraction task both in the supervised and semi-supervised settings. The study shows the very competitive performance of simple DNN models on the task as well as the high interest of pre-trained models. Adapting the latter models on the I2B2 dataset enables to push medication extraction performances above the state-of-the-art. Finally, the study also confirms that semi-supervised techniques are promising to leverage large amounts of unlabeled data in particular in low resource setting when labeled data is too costly to acquire.
Encouraging Neural Machine Translation to Satisfy Terminology Constraints
Jun 07, 2021
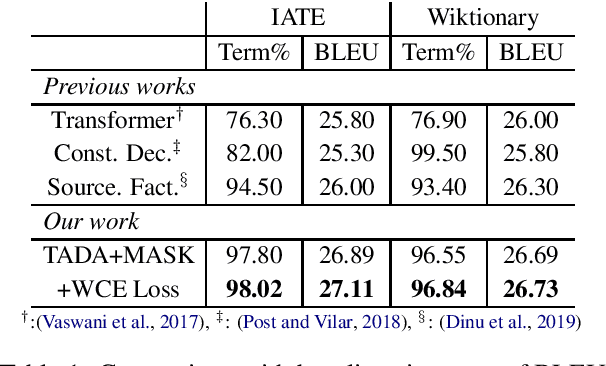


We present a new approach to encourage neural machine translation to satisfy lexical constraints. Our method acts at the training step and thereby avoiding the introduction of any extra computational overhead at inference step. The proposed method combines three main ingredients. The first one consists in augmenting the training data to specify the constraints. Intuitively, this encourages the model to learn a copy behavior when it encounters constraint terms. Compared to previous work, we use a simplified augmentation strategy without source factors. The second ingredient is constraint token masking, which makes it even easier for the model to learn the copy behavior and generalize better. The third one, is a modification of the standard cross entropy loss to bias the model towards assigning high probabilities to constraint words. Empirical results show that our method improves upon related baselines in terms of both BLEU score and the percentage of generated constraint terms.
Semi-Supervised Neural Text Generation by Joint Learning of Natural Language Generation and Natural Language Understanding Models
Sep 29, 2019
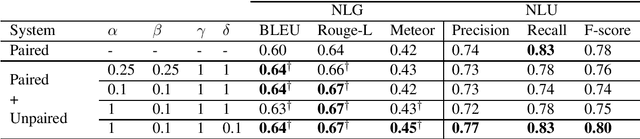
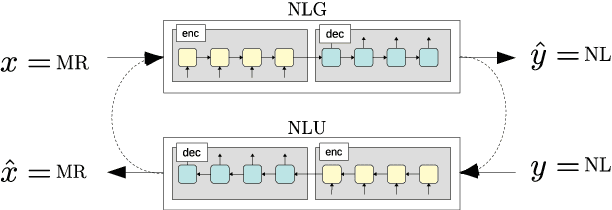
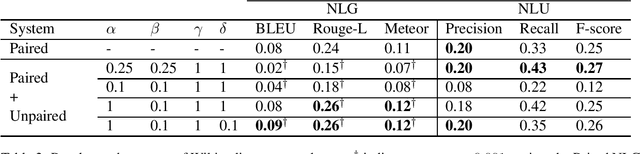
In Natural Language Generation (NLG), End-to-End (E2E) systems trained through deep learning have recently gained a strong interest. Such deep models need a large amount of carefully annotated data to reach satisfactory performance. However, acquiring such datasets for every new NLG application is a tedious and time-consuming task. In this paper, we propose a semi-supervised deep learning scheme that can learn from non-annotated data and annotated data when available. It uses an NLG and a Natural Language Understanding (NLU) sequence-to-sequence models which are learned jointly to compensate for the lack of annotation. Experiments on two benchmark datasets show that, with limited amount of annotated data, the method can achieve very competitive results while not using any pre-processing or re-scoring tricks. These findings open the way to the exploitation of non-annotated datasets which is the current bottleneck for the E2E NLG system development to new applications.