 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOLFIN -- Document-Level Financial test set for Machine Translation
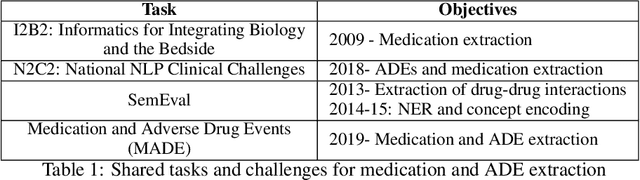
Feb 05, 2025Despite the strong research interest in document-level Machine Translation (MT), the test sets dedicated to this task are still scarce. The existing test sets mainly cover topics from the general domain and fall short on specialised domains, such as legal and financial. Also, in spite of their document-level aspect, they still follow a sentence-level logic that does not allow for including certain linguistic phenomena such as information reorganisation. In this work, we aim to fill this gap by proposing a novel test set: DOLFIN. The dataset is built from specialised financial documents, and it makes a step towards true document-level MT by abandoning the paradigm of perfectly aligned sentences, presenting data in units of sections rather than sentences. The test set consists of an average of 1950 aligned sections for five language pairs. We present a detailed data collection pipeline that can serve as inspiration for aligning new document-level datasets. We demonstrate the usefulness and quality of this test set by evaluating a number of models. Our results show that the test set is able to discriminate between context-sensitive and context-agnostic models and shows the weaknesses when models fail to accurately translate financial texts. The test set is made public for the community.
Spoken Dialogue System for Medical Prescription Acquisition on Smartphone: Development, Corpus and Evaluation
Nov 06, 2023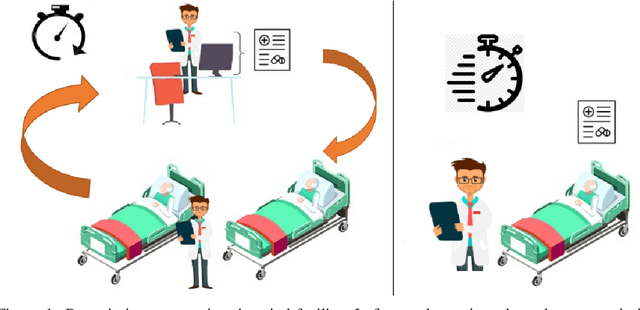


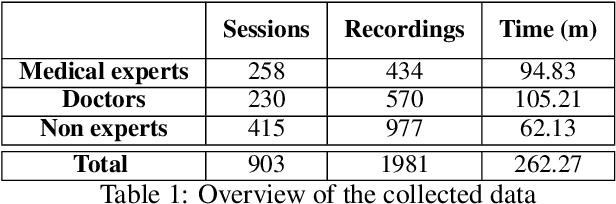
Hospital information systems (HIS) have become an essential part of healthcare institutions and now incorporate prescribing support software. Prescription support software allows for structured information capture, which improves the safety, appropriateness and efficiency of prescriptions and reduces the number of adverse drug events (ADEs). However, such a system increases the amount of time physicians spend at a computer entering information instead of providing medical care. In addition, any new visiting clinician must learn to manage complex interfaces since each HIS has its own interfaces. In this paper, we present a natural language interface for e-prescribing software in the form of a spoken dialogue system accessible on a smartphone. This system allows prescribers to record their prescriptions verbally, a form of interaction closer to their usual practice. The system extracts the formal representation of the prescription ready to be checked by the prescribing software and uses the dialogue to request mandatory information, correct errors or warn of particular situations. Since, to the best of our knowledge, there is no existing voice-based prescription dialogue system, we present the system developed in a low-resource environment, focusing on dialogue modeling, semantic extraction and data augmentation. The system was evaluated in the wild with 55 participants. This evaluation showed that our system has an average prescription time of 66.15 seconds for physicians and 35.64 seconds for other experts, and a task success rate of 76\% for physicians and 72\% for other experts. All evaluation data were recorded and annotated to form PxCorpus, the first spoken drug prescription corpus that has been made fully available to the community (\url{https://doi.org/10.5281/zenodo.6524162}).
A Spoken Drug Prescription Dataset in French for Spoken Language Understanding
Jul 17, 2022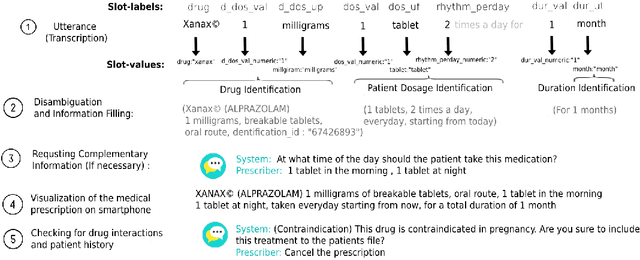


Spoken medical dialogue systems are increasingly attracting interest to enhance access to healthcare services and improve quality and traceability of patient care. In this paper, we focus on medical drug prescriptions acquired on smartphones through spoken dialogue. Such systems would facilitate the traceability of care and would free clinicians' time. However, there is a lack of speech corpora to develop such systems since most of the related corpora are in text form and in English. To facilitate the research and development of spoken medical dialogue systems, we present, to the best of our knowledge, the first spoken medical drug prescriptions corpus, named PxSLU. It contains 4 hours of transcribed and annotated dialogues of drug prescriptions in French acquired through an experiment with 55 participants experts and non-experts in prescriptions. We also present some experiments that demonstrate the interest of this corpus for the evaluation and development of medical dialogue systems.
Système de traduction automatique statistique Anglais-Arabe
Feb 06, 2018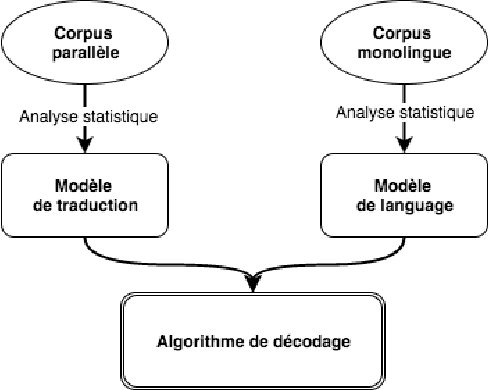



Machine translation (MT) is the process of translating text written in a source language into text in a target language. In this article, we present our English-Arabic statistical machine translation system. First, we present the general process for setting up a statistical machine translation system, then we describe the tools as well as the different corpora we used to build our MT system. Our system was evaluated in terms of the BLUE score (24.51%)
Word2Vec vs DBnary: Augmenting METEOR using Vector Representations or Lexical Resources?
Oct 05, 2016

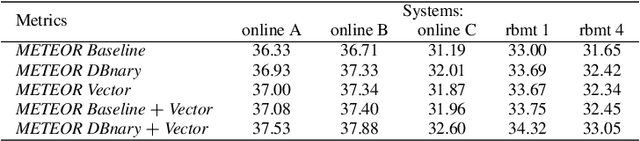
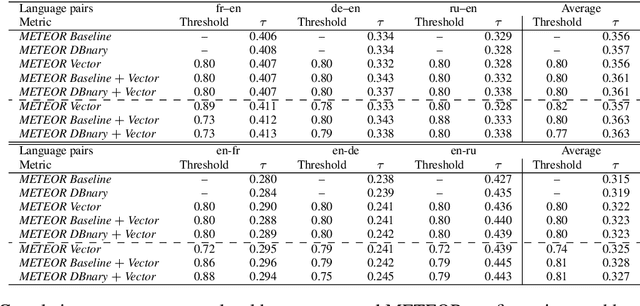
This paper presents an approach combining lexico-semantic resources and distributed representations of words applied to the evaluation in machine translation (MT). This study is made through the enrichment of a well-known MT evaluation metric: METEOR. This metric enables an approximate match (synonymy or morphological similarity) between an automatic and a reference translation. Our experiments are made in the framework of the Metrics task of WMT 2014. We show that distributed representations are a good alternative to lexico-semantic resources for MT evaluation and they can even bring interesting additional information. The augmented versions of METEOR, using vector representations, are made available on our Github page.