 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Multilingual Topic Dynamics and Trend Identification through ARIMA Time Series Analysis on Social Networks: A Novel Data Translation Framework Enhanced by LDA/HDP Models
Mar 18, 2024

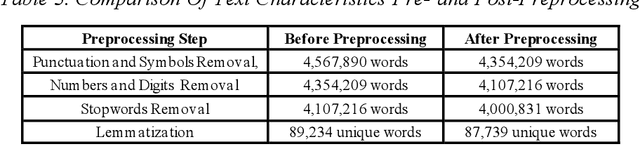
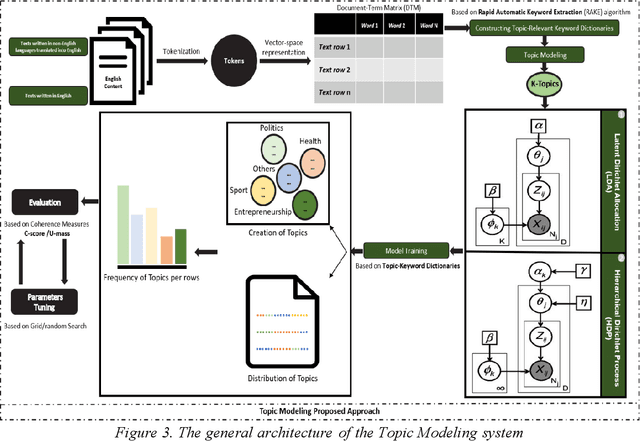
In this study, the authors present a novel methodology adept at decoding multilingual topic dynamics and identifying communication trends during crises. We focus on dialogues within Tunisian social networks during the Coronavirus Pandemic and other notable themes like sports and politics. We start by aggregating a varied multilingual corpus of comments relevant to these subjects. This dataset undergoes rigorous refinement during data preprocessing. We then introduce our No-English-to-English Machine Translation approach to handle linguistic differences. Empirical tests of this method showed high accuracy and F1 scores, highlighting its suitability for linguistically coherent tasks. Delving deeper, advanced modeling techniques, specifically LDA and HDP models are employed to extract pertinent topics from the translated content. This leads to applying ARIMA time series analysis to decode evolving topic trends. Applying our method to a multilingual Tunisian dataset, we effectively identified key topics mirroring public sentiment. Such insights prove vital for organizations and governments striving to understand public perspectives during crises. Compared to standard approaches, our model outperforms, as confirmed by metrics like Coherence Score, U-mass, and Topic Coherence. Additionally, an in-depth assessment of the identified topics revealed notable thematic shifts in discussions, with our trends identification indicating impressive accuracy, backed by RMSE-based analysis.
Système de traduction automatique statistique Anglais-Arabe
Feb 06, 2018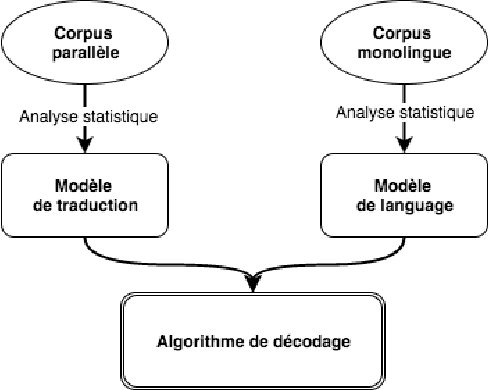



Machine translation (MT) is the process of translating text written in a source language into text in a target language. In this article, we present our English-Arabic statistical machine translation system. First, we present the general process for setting up a statistical machine translation system, then we describe the tools as well as the different corpora we used to build our MT system. Our system was evaluated in terms of the BLUE score (24.51%)
A Semantic Analyzer for the Comprehension of the Spontaneous Arabic Speech
Oct 08, 2016
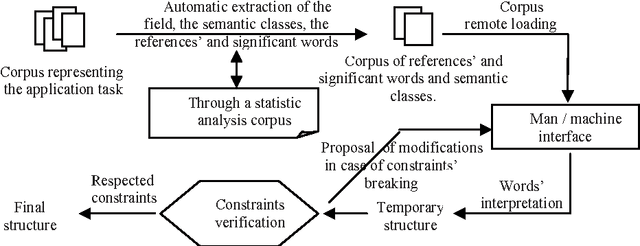
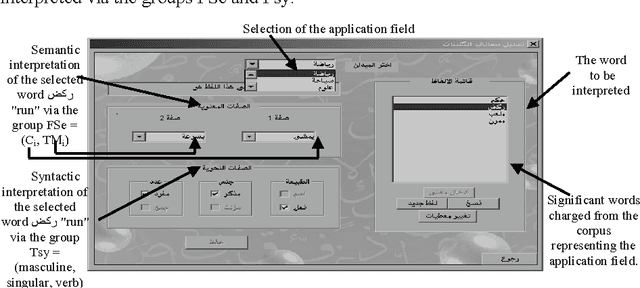
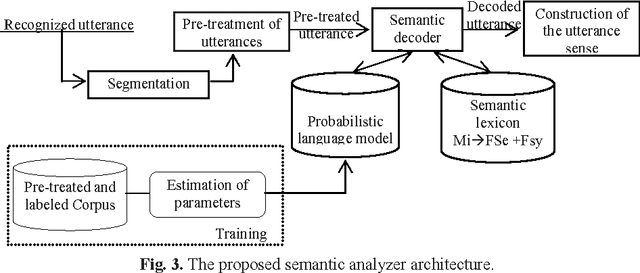
This work is part of a large research project entitled "Or\'eodule" aimed at developing tools for automatic speech recognition, translation, and synthesis for Arabic language. Our attention has mainly been focused on an attempt to improve the probabilistic model on which our semantic decoder is based. To achieve this goal, we have decided to test the influence of the pertinent context use, and of the contextual data integration of different types, on the effectiveness of the semantic decoder. The findings are quite satisfactory.
* Advances in Computer Science and Engineering. 12 pages 6 figures
Adaptation of pedagogical resources description standard (LOM) with the specificity of Arabic language
Aug 01, 2012
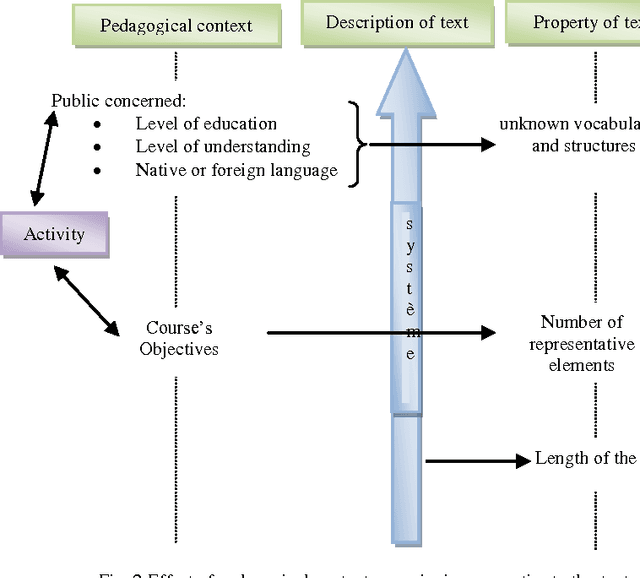
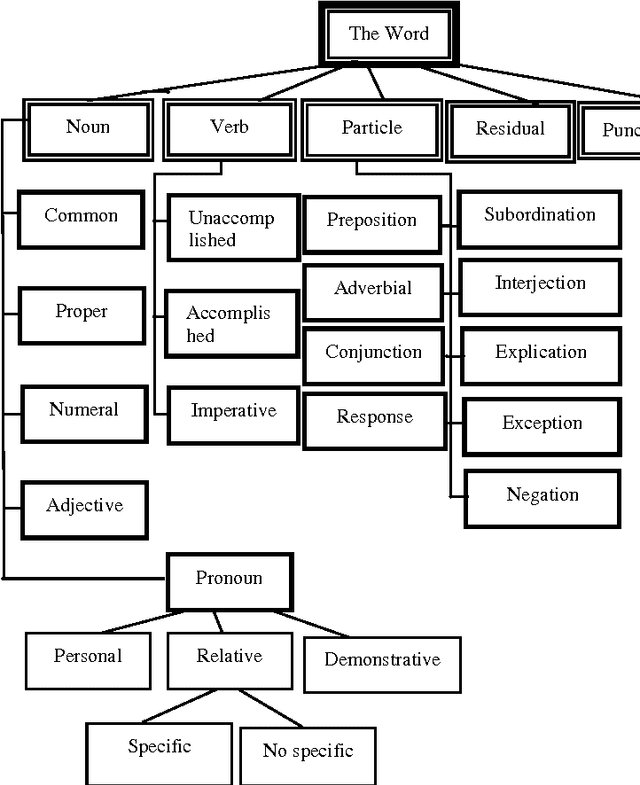
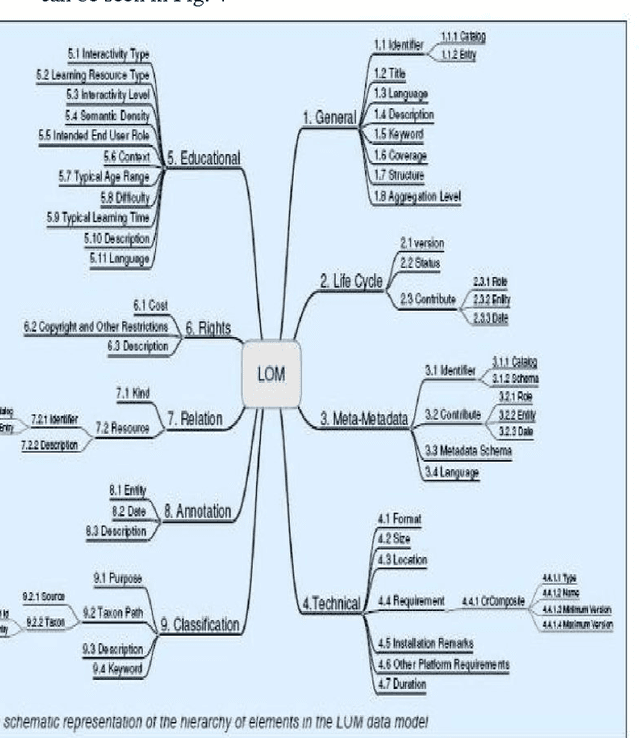
In this article we focus firstly on the principle of pedagogical indexing and characteristics of Arabic language and secondly on the possibility of adapting the standard for describing learning resources used (the LOM and its Application Profiles) with learning conditions such as the educational levels of students and their levels of understanding,... the educational context with taking into account the representative elements of text, text length, ... in particular, we put in relief the specificity of the Arabic language which is a complex language, characterized by its flexion, its voyellation and agglutination.
Clustering based approach extracting collocations
Jul 11, 2012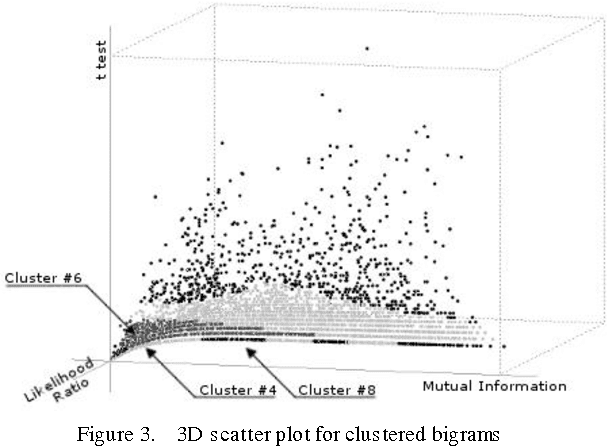
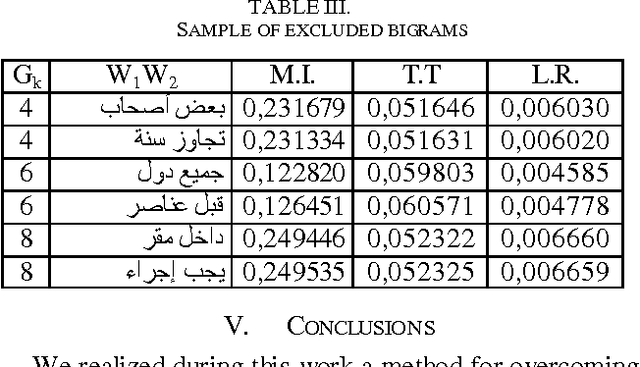
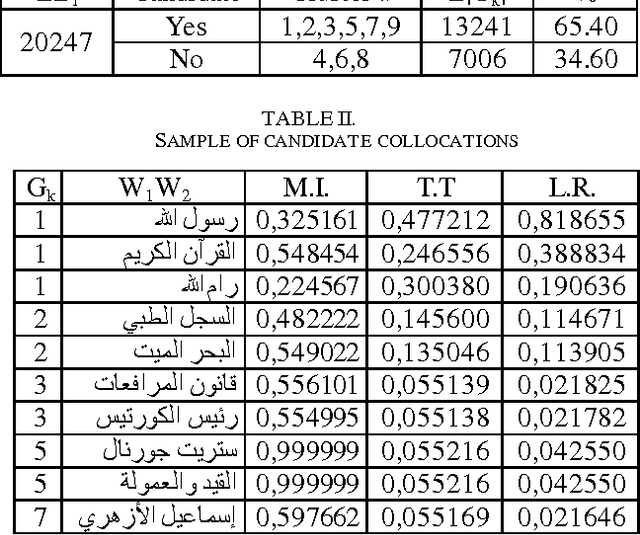

The following study presents a collocation extraction approach based on clustering technique. This study uses a combination of several classical measures which cover all aspects of a given corpus then it suggests separating bigrams found in the corpus in several disjoint groups according to the probability of presence of collocations. This will allow excluding groups where the presence of collocations is very unlikely and thus reducing in a meaningful way the search space.
Arabic CALL system based on pedagogically indexed text
Jul 10, 2012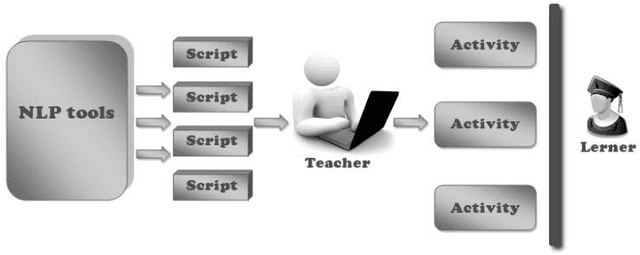
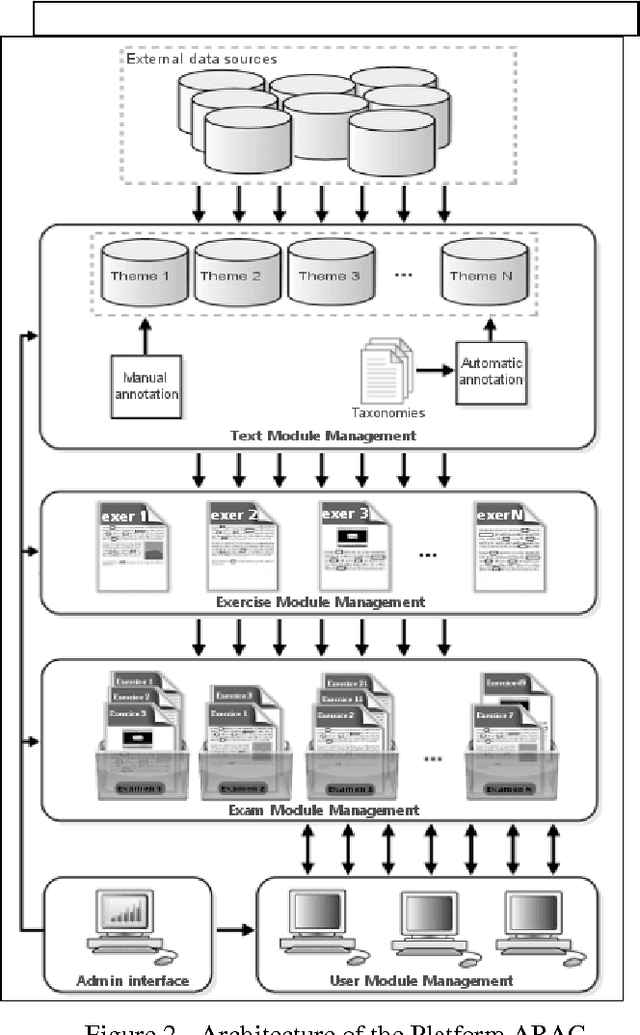

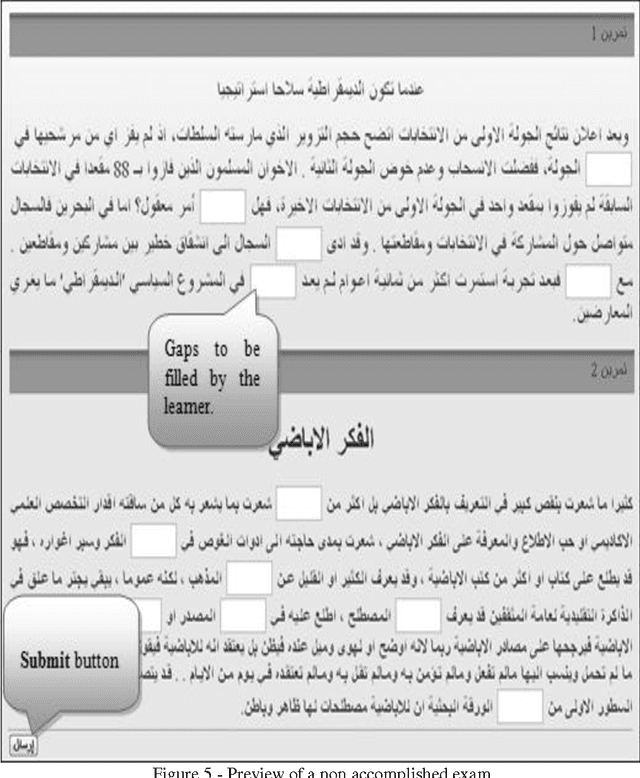
This article introduces the benefits of using computer as a tool for foreign language teaching and learning. It describes the effect of using Natural Language Processing (NLP) tools for learning Arabic. The technique explored in this particular case is the employment of pedagogically indexed corpora. This text-based method provides the teacher the advantage of building activities based on texts adapted to a particular pedagogical situation. This paper also presents ARAC: a Platform dedicated to language educators allowing them to create activities within their own pedagogical area of interest.
Developing a model for a text database indexed pedagogically for teaching the Arabic language
Jun 10, 2012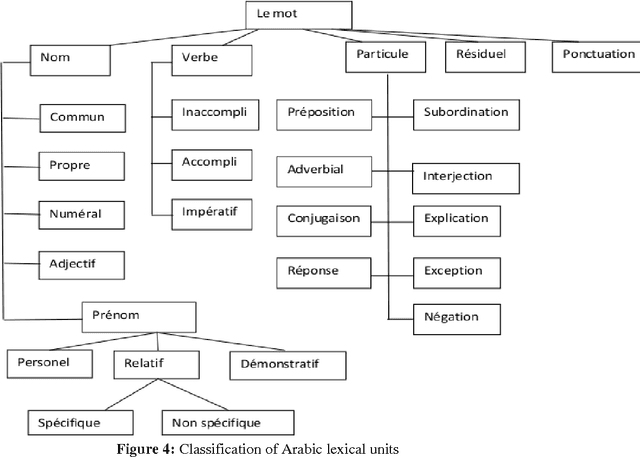
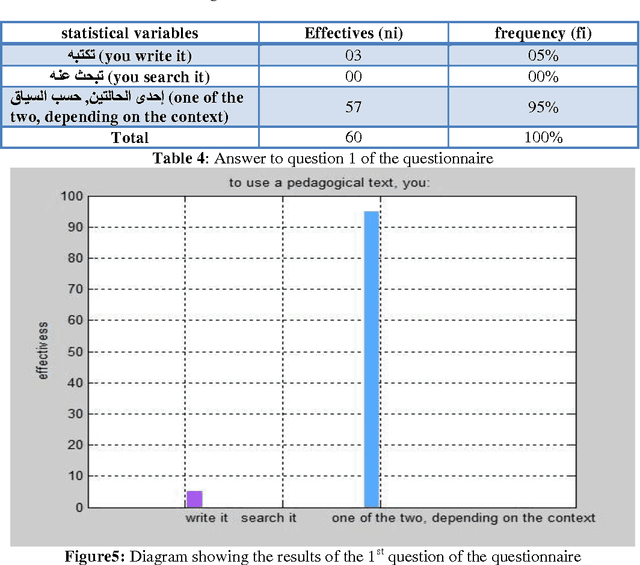
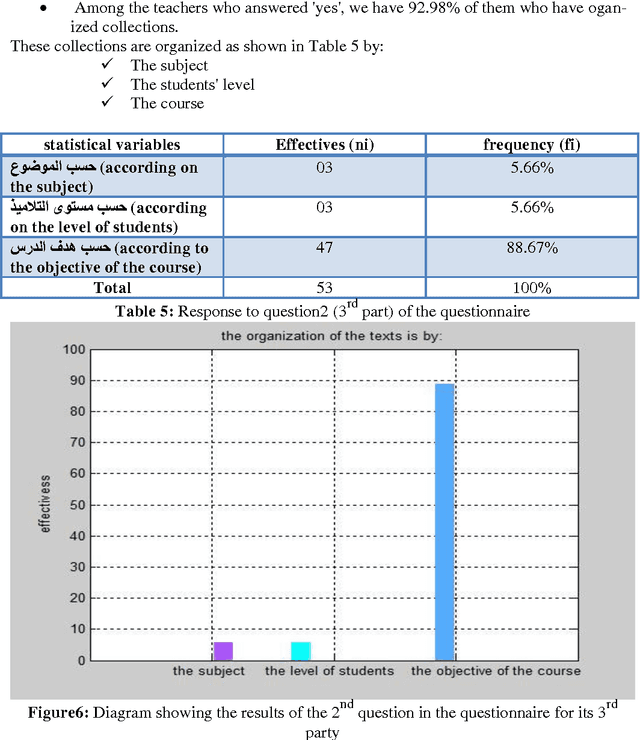
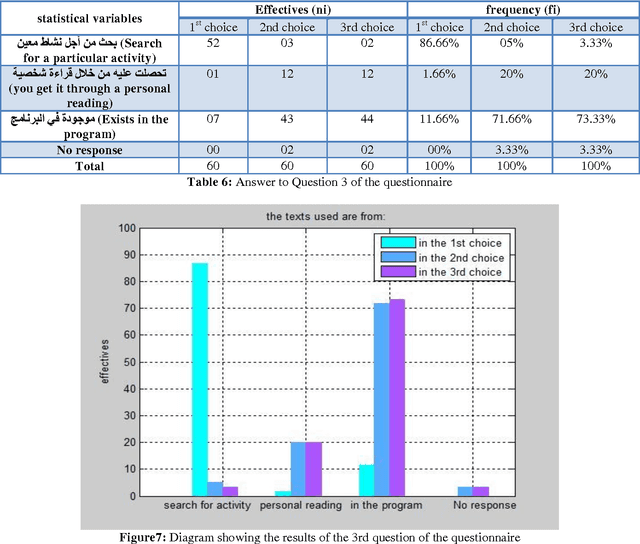
In this memory we made the design of an indexing model for Arabic language and adapting standards for describing learning resources used (the LOM and their application profiles) with learning conditions such as levels education of students, their levels of understanding...the pedagogical context with taking into account the repre-sentative elements of the text, text's length,...in particular, we highlight the specificity of the Arabic language which is a complex language, characterized by its flexion, its voyellation and its agglutination.
Arabic Language Learning Assisted by Computer, based on Automatic Speech Recognition
May 15, 2012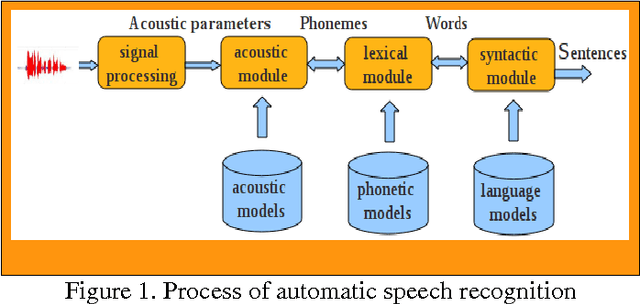
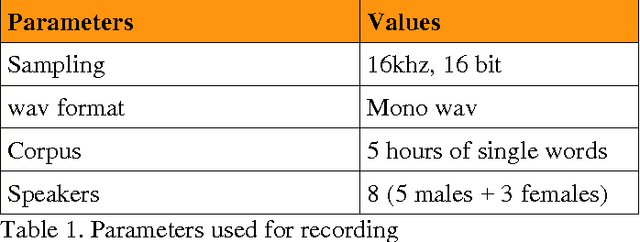
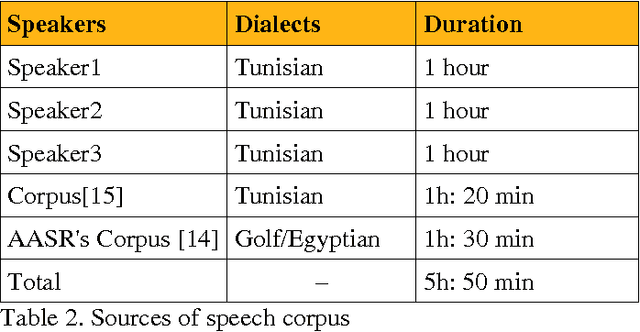

This work consists of creating a system of the Computer Assisted Language Learning (CALL) based on a system of Automatic Speech Recognition (ASR) for the Arabic language using the tool CMU Sphinx3 [1], based on the approach of HMM. To this work, we have constructed a corpus of six hours of speech recordings with a number of nine speakers. we find in the robustness to noise a grounds for the choice of the HMM approach [2]. the results achieved are encouraging since our corpus is made by only nine speakers, but they are always reasons that open the door for other improvement works.