Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering based approach extracting collocations
Paper and Code
Jul 11, 2012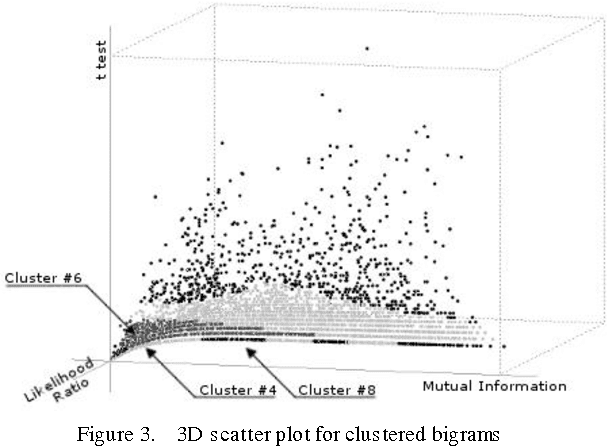
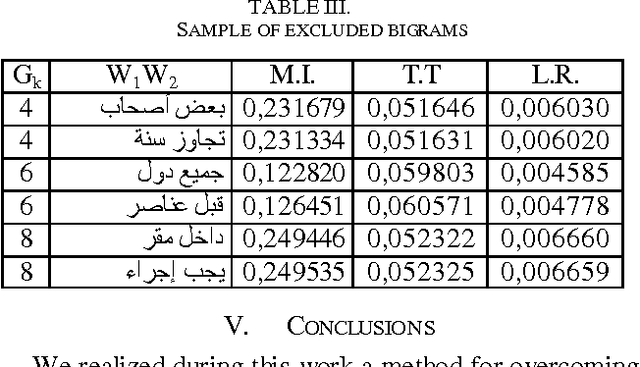
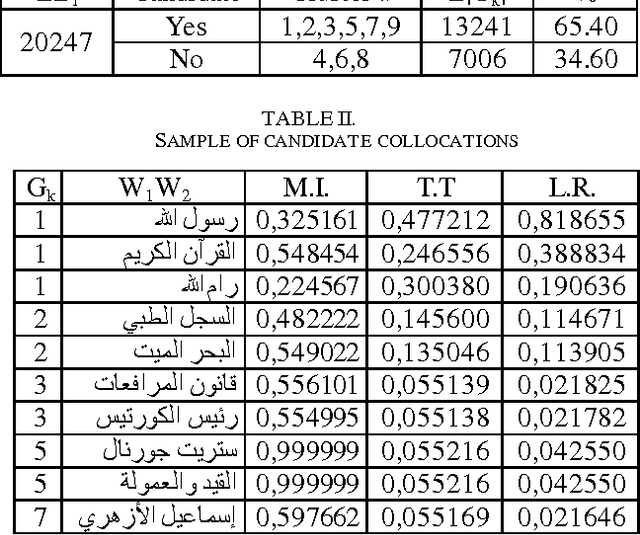

The following study presents a collocation extraction approach based on clustering technique. This study uses a combination of several classical measures which cover all aspects of a given corpus then it suggests separating bigrams found in the corpus in several disjoint groups according to the probability of presence of collocations. This will allow excluding groups where the presence of collocations is very unlikely and thus reducing in a meaningful way the search space.
* 4th International Conference on Arabic Language Processing. CITALA
2012. May 2nd -- 3rd 2012, Rabat, Morocco
View paper on