 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Multilingual Topic Dynamics and Trend Identification through ARIMA Time Series Analysis on Social Networks: A Novel Data Translation Framework Enhanced by LDA/HDP Models
Mar 18, 2024

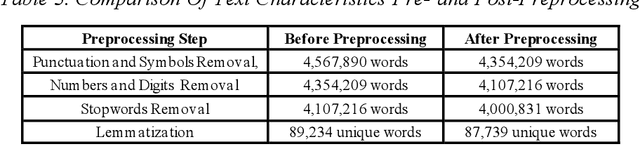
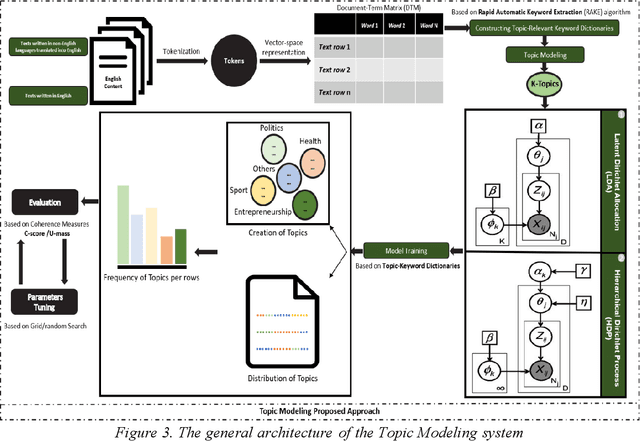
In this study, the authors present a novel methodology adept at decoding multilingual topic dynamics and identifying communication trends during crises. We focus on dialogues within Tunisian social networks during the Coronavirus Pandemic and other notable themes like sports and politics. We start by aggregating a varied multilingual corpus of comments relevant to these subjects. This dataset undergoes rigorous refinement during data preprocessing. We then introduce our No-English-to-English Machine Translation approach to handle linguistic differences. Empirical tests of this method showed high accuracy and F1 scores, highlighting its suitability for linguistically coherent tasks. Delving deeper, advanced modeling techniques, specifically LDA and HDP models are employed to extract pertinent topics from the translated content. This leads to applying ARIMA time series analysis to decode evolving topic trends. Applying our method to a multilingual Tunisian dataset, we effectively identified key topics mirroring public sentiment. Such insights prove vital for organizations and governments striving to understand public perspectives during crises. Compared to standard approaches, our model outperforms, as confirmed by metrics like Coherence Score, U-mass, and Topic Coherence. Additionally, an in-depth assessment of the identified topics revealed notable thematic shifts in discussions, with our trends identification indicating impressive accuracy, backed by RMSE-based analysis.