 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResponsible Benchmarking of Fairness for Automatic Speech Recognition
May 11, 2026Many studies have shown automatic speech processing (ASR) systems have unequal performance across speakergroups (SG's). However, the manner in which such studies arrive at this conclusion is inconsistent. To pave the wayfor more reliable results in future studies, we lay out best practices for benchmarking ASR fairness based on literaturefrom machine learning fairness, social sciences, and speech science. We first describe the importance of preciselythe fairness hypothesis being interrogated, and tailoring fairness metrics to apply specifically to said hypothesis.We then examine several benchmarks used to rate ASR systems on fairness and discuss how their results can bemisconstrued without assiduous oversight into the intersections between SG's. We find that evaluating fairnessbased on single heterogeneous SG's, such as they are defined in fairness benchmarks, can lead to misidentifyingwhich SG's are actually being mistreated by ASR systems. We advocate for as fine-grained an analysis as possibleof the intersectionality of as many demographic variables as are available in the metadata of fairness corpora in orderto tease out such spurious correlations
Automated Clinical Report Generation for Remote Cognitive Remediation: Comparing Knowledge-Engineered Templates and LLMs in Low-Resource Settings
May 07, 2026The growing demand for cognitive remediation therapy, combined with limited speech therapist availability, has accelerated the adoption of remote rehabilitation tools. These systems generate large volumes of interaction data that are difficult for clinicians to review efficiently. This paper investigates automated clinical report generation for avatar-guided, home-based cognitive remediation sessions in a low-resource setting with no reference reports. We present and compare two approaches: (1) a rule-based template system encoding speech therapy domain knowledge as explicit decision rules and validated templates, ensuring clinical reliability and traceability; and (2) a zero-shot LLM-based approach (GPT-4) aimed at more fluent and concise output. Both systems use identical pre-extracted, expert-validated structured variables, enabling a controlled factual comparison. Outputs were evaluated by eight speech therapists and final-year students using a nine-criterion questionnaire. Results reveal a clear trade-off between clinical reliability and linguistic quality. The template-based system scored higher on fluidity, coherence, and results presentation, while GPT-4 produced more concise output. Directional differences are consistent across evaluation dimensions, though no comparison reached statistical significance after correction, reflecting the scale constraints of expert clinical evaluation. Based on evaluator feedback, we derive eight design recommendations for clinical reporting systems in remote rehabilitation settings. More broadly, this work contributes a replicable methodology combining expert elicitation, taxonomy-driven generation, and multi-dimensional human evaluation for clinical NLG in low-resource settings, and illustrates how controlled comparisons can inform the responsible adoption of generative AI in healthcare.
Identifying and typifying demographic unfairness in phoneme-level embeddings of self-supervised speech recognition models
Apr 24, 2026Modern automatic speech recognition (ASR) systems have been observed to function better for certain speaker groups (SGs) than others, despite recent gains in overall performance. One potential impediment to progress towards fairer ASR is a more nuanced understanding of the types of modeling errors that speech encoder models make, and in particular the difference between the structure of embeddings for high-performance and low-performance SGs. This paper proposes a framework typifying two types of error that can occur in modeling phonemes in ASR systems: random error/high variance in phoneme embedding, vs systematic error/embedding bias. We find that training phoneme classification probes only on a single, typically disadvantaged SG, sometimes improves performance for that SG, which is evidence for the existence of SG-level bias in phoneme embeddings. On the other hand, we find that speakers and SGs with higher levels of phoneme variance are the same as those with worse phoneme prediction accuracy. We conclude that both types of error are present in phoneme embeddings and both are candidate causes for SG-level unfairness in ASR, though random error is likely a greater hindrance to fairness than systematic error. Furthermore, we find that finetuning encoder models using a fairness-enhancing algorithm (domain enhancing and adversarial training) changes neither the benefits of in-domain phoneme classification probe training, nor measured levels of random embedding error.
What Makes an LLM a Good Optimizer? A Trajectory Analysis of LLM-Guided Evolutionary Search
Apr 21, 2026Recent work has demonstrated the promise of orchestrating large language models (LLMs) within evolutionary and agentic optimization systems. However, the mechanisms driving these optimization gains remain poorly understood. In this work, we present a large-scale study of LLM-guided evolutionary search, collecting optimization trajectories for 15 LLMs across 8 tasks. Although zero-shot problem-solving ability correlates with final optimization outcomes, it explains only part of the variance: models with similar initial capability often induce dramatically different search trajectories and outcomes. By analyzing these trajectories, we find that strong LLM optimizers behave as local refiners, producing frequent incremental improvements while progressively localizing the search in semantic space. Conversely, weaker optimizers exhibit large semantic drift, with sporadic breakthroughs followed by stagnation. Notably, various measures of solution novelty do not predict final performance; novelty is beneficial only when the search remains sufficiently localized around high-performing regions of the solution space. Our results highlight the importance of trajectory analysis for understanding and improving LLM-based optimization systems and provide actionable insights for their design and training.
Where Do Self-Supervised Speech Models Become Unfair?
Apr 20, 2026Speech encoder models are known to model members of some speaker groups (SGs) better than others. However, there has been little work in establishing why this occurs on a technological level. To our knowledge, we present the first layerwise fairness analysis of pretrained self-supervised speech encoder models (S3Ms), probing each embedding layer for speaker identification (SID) automatic speech recognition (ASR). We find S3Ms produce embeddings biased against certain SGs for both tasks, starting at the very first latent layers. Furthermore, we find opposite patterns of layerwise bias for SID vs ASR for all models in our study: SID bias is minimized in layers that minimize overall SID error; on the other hand, ASR bias is maximized in layers that minimize overall ASR error. The inverse bias/error relationship for ASR is unaffected when probing S3Ms that are finetuned for ASR, suggesting SG-level bias is established during pretraining and is difficult to remove.
Is Biomedical Specialization Still Worth It? Insights from Domain-Adaptive Language Modelling with a New French Health Corpus
Apr 08, 2026Large language models (LLMs) have demonstrated remarkable capabilities across diverse domains, yet their adaptation to specialized fields remains challenging, particularly for non-English languages. This study investigates domain-adaptive pre-training (DAPT) as a strategy for specializing small to mid-sized LLMs in the French biomedical domain through continued pre-training. We address two key research questions: the viability of specialized continued pre-training for domain adaptation and the relationship between domain-specific performance gains and general capability degradation. Our contributions include the release of a fully open-licensed French biomedical corpus suitable for commercial and open-source applications, the training and release of specialized French biomedical LLMs, and novel insights for DAPT implementation. Our methodology encompasses the collection and refinement of high-quality French biomedical texts, the exploration of causal language modeling approaches using DAPT, and conducting extensive comparative evaluations. Our results cast doubt on the efficacy of DAPT, in contrast to previous works, but we highlight its viability in smaller-scale, resource-constrained scenarios under the right conditions. Findings in this paper further suggest that model merging post-DAPT is essential to mitigate generalization trade-offs, and in some cases even improves performance on specialized tasks at which the DAPT was directed.
Pantagruel: Unified Self-Supervised Encoders for French Text and Speech
Jan 09, 2026We release Pantagruel models, a new family of self-supervised encoder models for French text and speech. Instead of predicting modality-tailored targets such as textual tokens or speech units, Pantagruel learns contextualized target representations in the feature space, allowing modality-specific encoders to capture linguistic and acoustic regularities more effectively. Separate models are pre-trained on large-scale French corpora, including Wikipedia, OSCAR and CroissantLLM for text, together with MultilingualLibriSpeech, LeBenchmark, and INA-100k for speech. INA-100k is a newly introduced 100,000-hour corpus of French audio derived from the archives of the Institut National de l'Audiovisuel (INA), the national repository of French radio and television broadcasts, providing highly diverse audio data. We evaluate Pantagruel across a broad range of downstream tasks spanning both modalities, including those from the standard French benchmarks such as FLUE or LeBenchmark. Across these tasks, Pantagruel models show competitive or superior performance compared to strong French baselines such as CamemBERT, FlauBERT, and LeBenchmark2.0, while maintaining a shared architecture that can seamlessly handle either speech or text inputs. These results confirm the effectiveness of feature-space self-supervised objectives for French representation learning and highlight Pantagruel as a robust foundation for multimodal speech-text understanding.
The Dead Salmons of AI Interpretability
Dec 21, 2025In a striking neuroscience study, the authors placed a dead salmon in an MRI scanner and showed it images of humans in social situations. Astonishingly, standard analyses of the time reported brain regions predictive of social emotions. The explanation, of course, was not supernatural cognition but a cautionary tale about misapplied statistical inference. In AI interpretability, reports of similar ''dead salmon'' artifacts abound: feature attribution, probing, sparse auto-encoding, and even causal analyses can produce plausible-looking explanations for randomly initialized neural networks. In this work, we examine this phenomenon and argue for a pragmatic statistical-causal reframing: explanations of computational systems should be treated as parameters of a (statistical) model, inferred from computational traces. This perspective goes beyond simply measuring statistical variability of explanations due to finite sampling of input data; interpretability methods become statistical estimators, and findings should be tested against explicit and meaningful alternative computational hypotheses, with uncertainty quantified with respect to the postulated statistical model. It also highlights important theoretical issues, such as the identifiability of common interpretability queries, which we argue is critical to understand the field's susceptibility to false discoveries, poor generalizability, and high variance. More broadly, situating interpretability within the standard toolkit of statistical inference opens promising avenues for future work aimed at turning AI interpretability into a pragmatic and rigorous science.
Mechanistic Interpretability as Statistical Estimation: A Variance Analysis of EAP-IG
Oct 02, 2025The development of trustworthy artificial intelligence requires moving beyond black-box performance metrics toward an understanding of models' internal computations. Mechanistic Interpretability (MI) aims to meet this need by identifying the algorithmic mechanisms underlying model behaviors. Yet, the scientific rigor of MI critically depends on the reliability of its findings. In this work, we argue that interpretability methods, such as circuit discovery, should be viewed as statistical estimators, subject to questions of variance and robustness. To illustrate this statistical framing, we present a systematic stability analysis of a state-of-the-art circuit discovery method: EAP-IG. We evaluate its variance and robustness through a comprehensive suite of controlled perturbations, including input resampling, prompt paraphrasing, hyperparameter variation, and injected noise within the causal analysis itself. Across a diverse set of models and tasks, our results demonstrate that EAP-IG exhibits high structural variance and sensitivity to hyperparameters, questioning the stability of its findings. Based on these results, we offer a set of best-practice recommendations for the field, advocating for the routine reporting of stability metrics to promote a more rigorous and statistically grounded science of interpretability.
Everything, Everywhere, All at Once: Is Mechanistic Interpretability Identifiable?
Feb 28, 2025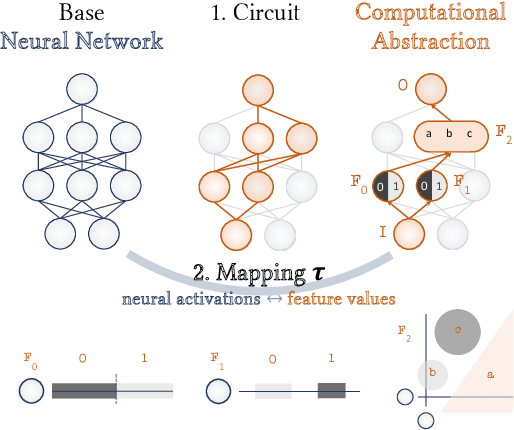
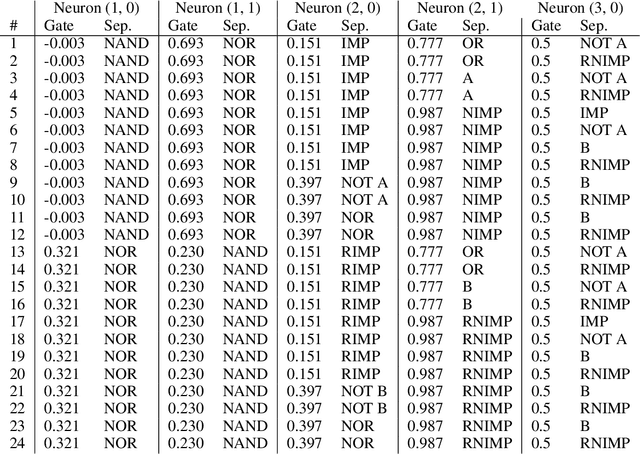
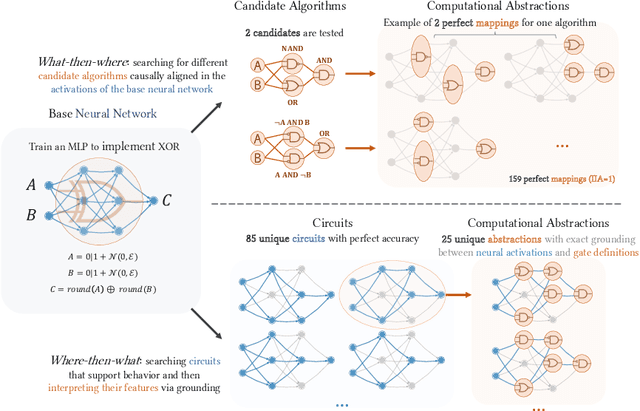

As AI systems are used in high-stakes applications, ensuring interpretability is crucial. Mechanistic Interpretability (MI) aims to reverse-engineer neural networks by extracting human-understandable algorithms to explain their behavior. This work examines a key question: for a given behavior, and under MI's criteria, does a unique explanation exist? Drawing on identifiability in statistics, where parameters are uniquely inferred under specific assumptions, we explore the identifiability of MI explanations. We identify two main MI strategies: (1) "where-then-what," which isolates a circuit replicating model behavior before interpreting it, and (2) "what-then-where," which starts with candidate algorithms and searches for neural activation subspaces implementing them, using causal alignment. We test both strategies on Boolean functions and small multi-layer perceptrons, fully enumerating candidate explanations. Our experiments reveal systematic non-identifiability: multiple circuits can replicate behavior, a circuit can have multiple interpretations, several algorithms can align with the network, and one algorithm can align with different subspaces. Is uniqueness necessary? A pragmatic approach may require only predictive and manipulability standards. If uniqueness is essential for understanding, stricter criteria may be needed. We also reference the inner interpretability framework, which validates explanations through multiple criteria. This work contributes to defining explanation standards in AI.