 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagic-MM-Embedding: Towards Visual-Token-Efficient Universal Multimodal Embedding with MLLMs
Feb 05, 2026Multimodal Large Language Models (MLLMs) have shown immense promise in universal multimodal retrieval, which aims to find relevant items of various modalities for a given query. But their practical application is often hindered by the substantial computational cost incurred from processing a large number of tokens from visual inputs. In this paper, we propose Magic-MM-Embedding, a series of novel models that achieve both high efficiency and state-of-the-art performance in universal multimodal embedding. Our approach is built on two synergistic pillars: (1) a highly efficient MLLM architecture incorporating visual token compression to drastically reduce inference latency and memory footprint, and (2) a multi-stage progressive training strategy designed to not only recover but significantly boost performance. This coarse-to-fine training paradigm begins with extensive continue pretraining to restore multimodal understanding and generation capabilities, progresses to large-scale contrastive pretraining and hard negative mining to enhance discriminative power, and culminates in a task-aware fine-tuning stage guided by an MLLM-as-a-Judge for precise data curation. Comprehensive experiments show that our model outperforms existing methods by a large margin while being more inference-efficient.
What Matters to an LLM? Behavioral and Computational Evidences from Summarization
Jan 31, 2026Large Language Models (LLMs) are now state-of-the-art at summarization, yet the internal notion of importance that drives their information selections remains hidden. We propose to investigate this by combining behavioral and computational analyses. Behaviorally, we generate a series of length-controlled summaries for each document and derive empirical importance distributions based on how often each information unit is selected. These reveal that LLMs converge on consistent importance patterns, sharply different from pre-LLM baselines, and that LLMs cluster more by family than by size. Computationally, we identify that certain attention heads align well with empirical importance distributions, and that middle-to-late layers are strongly predictive of importance. Together, these results provide initial insights into what LLMs prioritize in summarization and how this priority is internally represented, opening a path toward interpreting and ultimately controlling information selection in these models.
Can GPT models Follow Human Summarization Guidelines? Evaluating ChatGPT and GPT-4 for Dialogue Summarization
Oct 25, 2023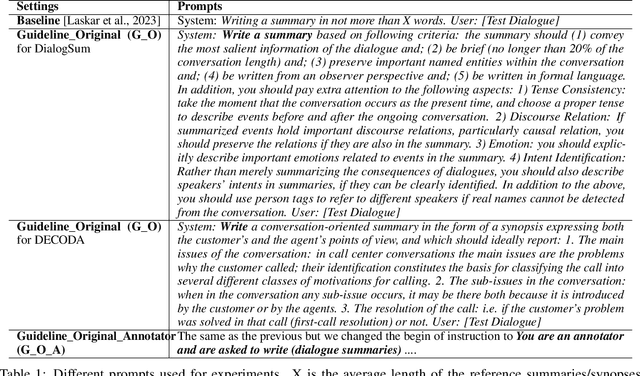
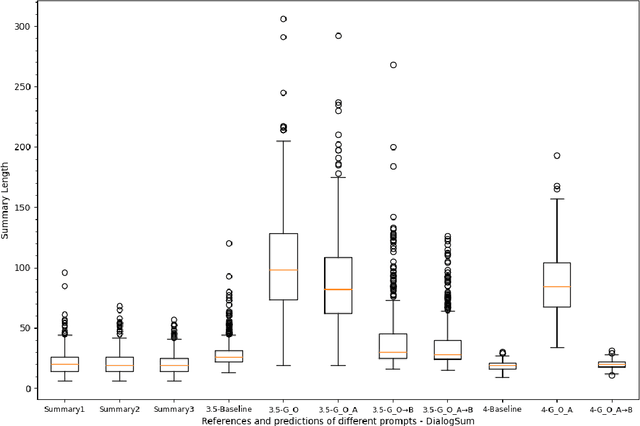
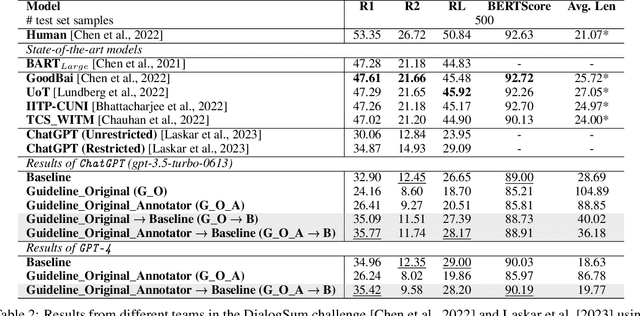
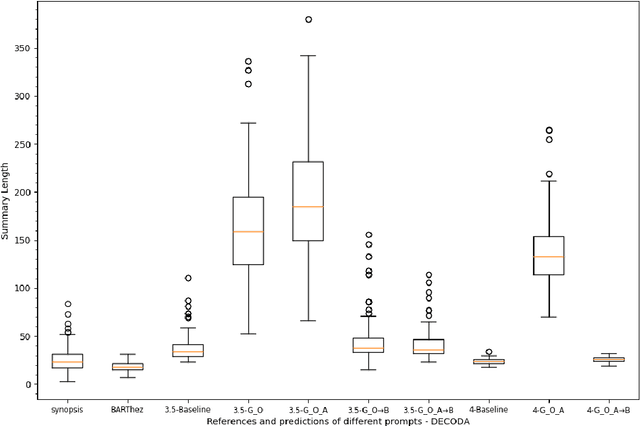
This study explores the capabilities of prompt-driven Large Language Models (LLMs) like ChatGPT and GPT-4 in adhering to human guidelines for dialogue summarization. Experiments employed DialogSum (English social conversations) and DECODA (French call center interactions), testing various prompts: including prompts from existing literature and those from human summarization guidelines, as well as a two-step prompt approach. Our findings indicate that GPT models often produce lengthy summaries and deviate from human summarization guidelines. However, using human guidelines as an intermediate step shows promise, outperforming direct word-length constraint prompts in some cases. The results reveal that GPT models exhibit unique stylistic tendencies in their summaries. While BERTScores did not dramatically decrease for GPT outputs suggesting semantic similarity to human references and specialised pre-trained models, ROUGE scores reveal grammatical and lexical disparities between GPT-generated and human-written summaries. These findings shed light on the capabilities and limitations of GPT models in following human instructions for dialogue summarization.
Evaluating Emotional Nuances in Dialogue Summarization
Jul 23, 2023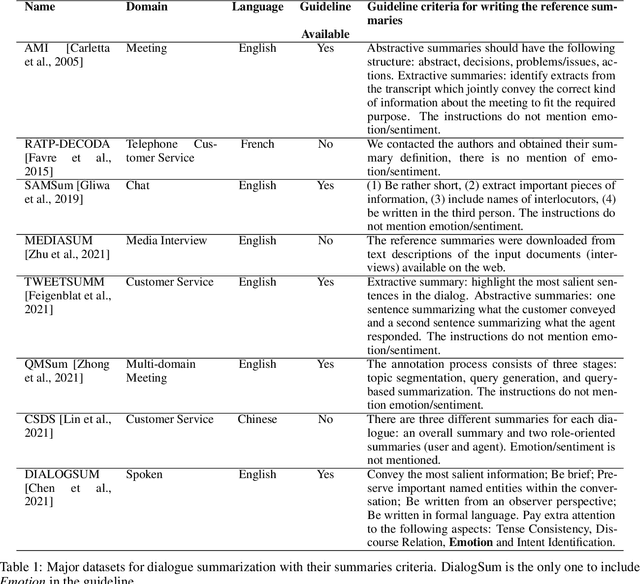
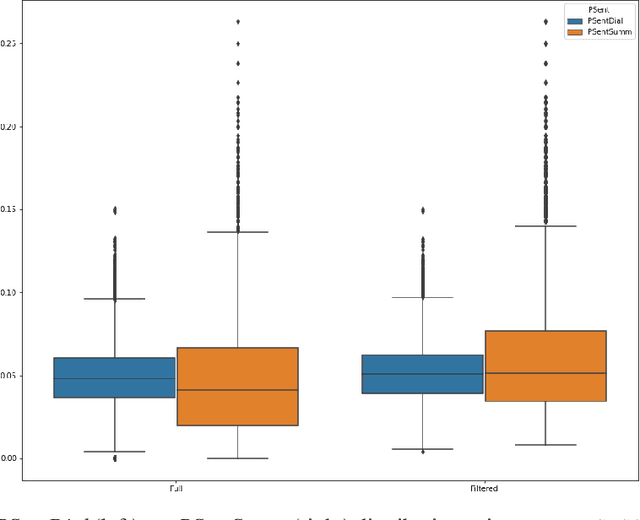


Automatic dialogue summarization is a well-established task that aims to identify the most important content from human conversations to create a short textual summary. Despite recent progress in the field, we show that most of the research has focused on summarizing the factual information, leaving aside the affective content, which can yet convey useful information to analyse, monitor, or support human interactions. In this paper, we propose and evaluate a set of measures $PEmo$, to quantify how much emotion is preserved in dialog summaries. Results show that, summarization models of the state-of-the-art do not preserve well the emotional content in the summaries. We also show that by reducing the training set to only emotional dialogues, the emotional content is better preserved in the generated summaries, while conserving the most salient factual information.
Effectiveness of French Language Models on Abstractive Dialogue Summarization Task
Jul 17, 2022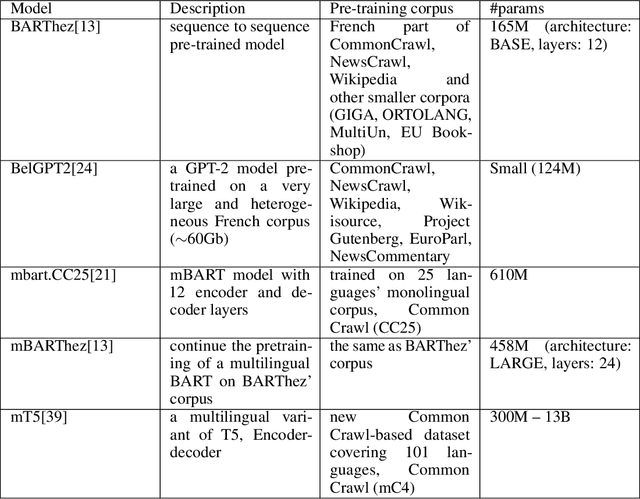
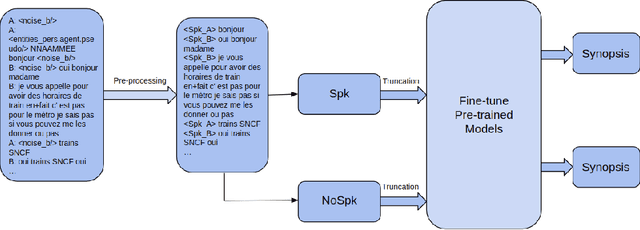


Pre-trained language models have established the state-of-the-art on various natural language processing tasks, including dialogue summarization, which allows the reader to quickly access key information from long conversations in meetings, interviews or phone calls. However, such dialogues are still difficult to handle with current models because the spontaneity of the language involves expressions that are rarely present in the corpora used for pre-training the language models. Moreover, the vast majority of the work accomplished in this field has been focused on English. In this work, we present a study on the summarization of spontaneous oral dialogues in French using several language specific pre-trained models: BARThez, and BelGPT-2, as well as multilingual pre-trained models: mBART, mBARThez, and mT5. Experiments were performed on the DECODA (Call Center) dialogue corpus whose task is to generate abstractive synopses from call center conversations between a caller and one or several agents depending on the situation. Results show that the BARThez models offer the best performance far above the previous state-of-the-art on DECODA. We further discuss the limits of such pre-trained models and the challenges that must be addressed for summarizing spontaneous dialogues.