 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffectiveness of French Language Models on Abstractive Dialogue Summarization Task
Paper and Code
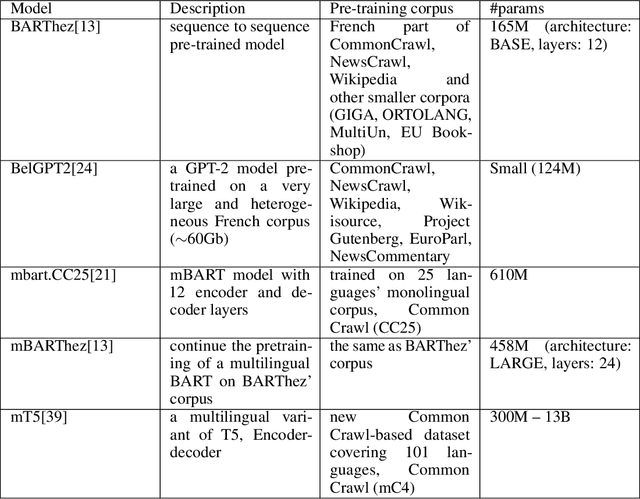
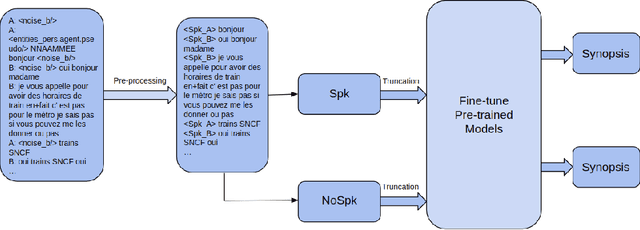


Pre-trained language models have established the state-of-the-art on various natural language processing tasks, including dialogue summarization, which allows the reader to quickly access key information from long conversations in meetings, interviews or phone calls. However, such dialogues are still difficult to handle with current models because the spontaneity of the language involves expressions that are rarely present in the corpora used for pre-training the language models. Moreover, the vast majority of the work accomplished in this field has been focused on English. In this work, we present a study on the summarization of spontaneous oral dialogues in French using several language specific pre-trained models: BARThez, and BelGPT-2, as well as multilingual pre-trained models: mBART, mBARThez, and mT5. Experiments were performed on the DECODA (Call Center) dialogue corpus whose task is to generate abstractive synopses from call center conversations between a caller and one or several agents depending on the situation. Results show that the BARThez models offer the best performance far above the previous state-of-the-art on DECODA. We further discuss the limits of such pre-trained models and the challenges that must be addressed for summarizing spontaneous dialogues.