 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Fine-Tuning for HAR: Integrating LoRA and QLoRA into Transformer Models
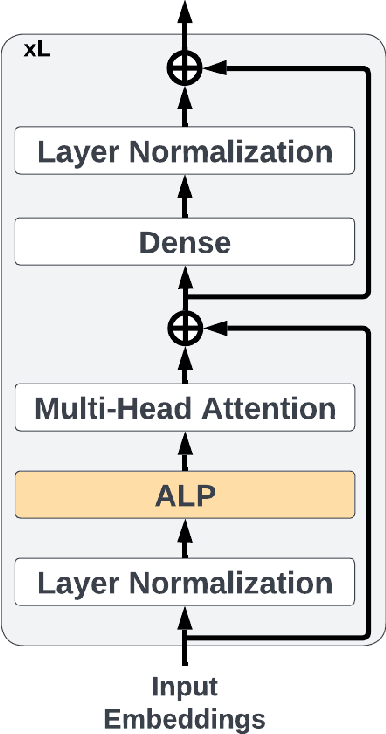
Dec 19, 2025Human Activity Recognition is a foundational task in pervasive computing. While recent advances in self-supervised learning and transformer-based architectures have significantly improved HAR performance, adapting large pretrained models to new domains remains a practical challenge due to limited computational resources on target devices. This papers investigates parameter-efficient fine-tuning techniques, specifically Low-Rank Adaptation (LoRA) and Quantized LoRA, as scalable alternatives to full model fine-tuning for HAR. We propose an adaptation framework built upon a Masked Autoencoder backbone and evaluate its performance under a Leave-One-Dataset-Out validation protocol across five open HAR datasets. Our experiments demonstrate that both LoRA and QLoRA can match the recognition performance of full fine-tuning while significantly reducing the number of trainable parameters, memory usage, and training time. Further analyses reveal that LoRA maintains robust performance even under limited supervision and that the adapter rank provides a controllable trade-off between accuracy and efficiency. QLoRA extends these benefits by reducing the memory footprint of frozen weights through quantization, with minimal impact on classification quality.
Quantifying Uncertainty in Machine Learning-Based Pervasive Systems: Application to Human Activity Recognition
Dec 10, 2025The recent convergence of pervasive computing and machine learning has given rise to numerous services, impacting almost all areas of economic and social activity. However, the use of AI techniques precludes certain standard software development practices, which emphasize rigorous testing to ensure the elimination of all bugs and adherence to well-defined specifications. ML models are trained on numerous high-dimensional examples rather than being manually coded. Consequently, the boundaries of their operating range are uncertain, and they cannot guarantee absolute error-free performance. In this paper, we propose to quantify uncertainty in ML-based systems. To achieve this, we propose to adapt and jointly utilize a set of selected techniques to evaluate the relevance of model predictions at runtime. We apply and evaluate these proposals in the highly heterogeneous and evolving domain of Human Activity Recognition (HAR). The results presented demonstrate the relevance of the approach, and we discuss in detail the assistance provided to domain experts.
FedAli: Personalized Federated Learning with Aligned Prototypes through Optimal Transport
Nov 15, 2024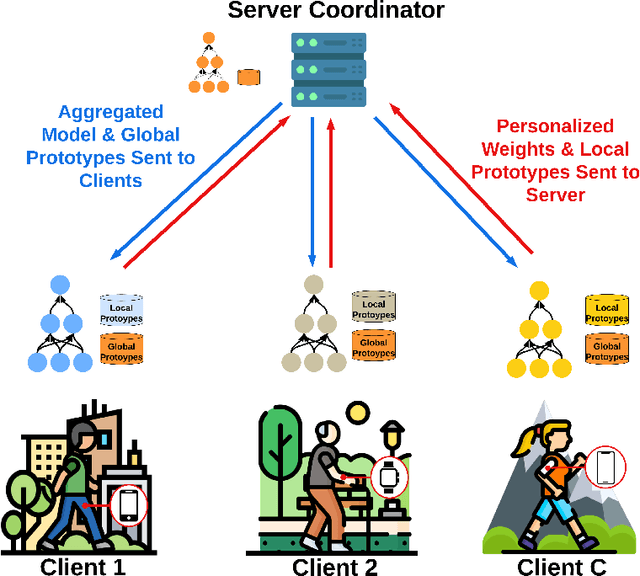
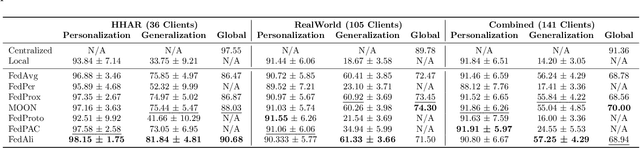

Federated Learning (FL) enables collaborative, personalized model training across multiple devices without sharing raw data, making it ideal for pervasive computing applications that optimize user-centric performances in diverse environments. However, data heterogeneity among clients poses a significant challenge, leading to inconsistencies among trained client models and reduced performance. To address this, we introduce the Alignment with Prototypes (ALP) layers, which align incoming embeddings closer to learnable prototypes through an optimal transport plan. During local training, the ALP layer updates local prototypes and aligns embeddings toward global prototypes aggregated from all clients using our novel FL framework, Federated Alignment (FedAli). For model inferences, embeddings are guided toward local prototypes to better reflect the client's local data distribution. We evaluate FedAli on heterogeneous sensor-based human activity recognition and vision benchmark datasets, demonstrating that it outperforms existing FL strategies. We publicly release our source code to facilitate reproducibility and furthered research.
Combining Public Human Activity Recognition Datasets to Mitigate Labeled Data Scarcity
Jun 23, 2023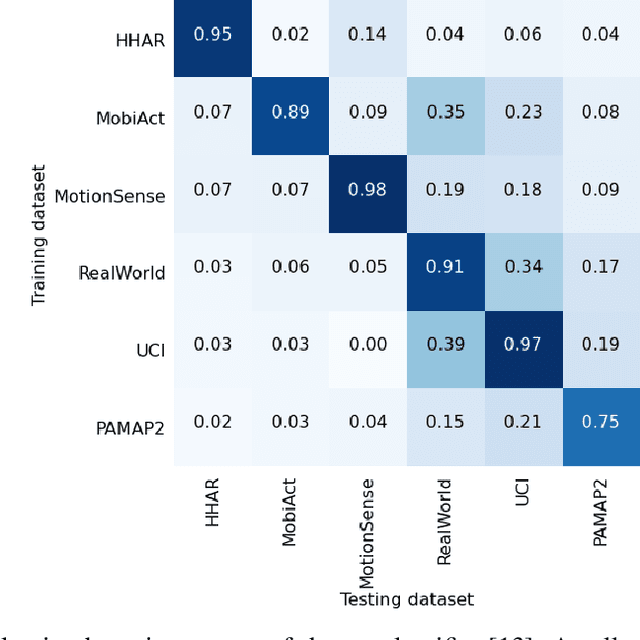
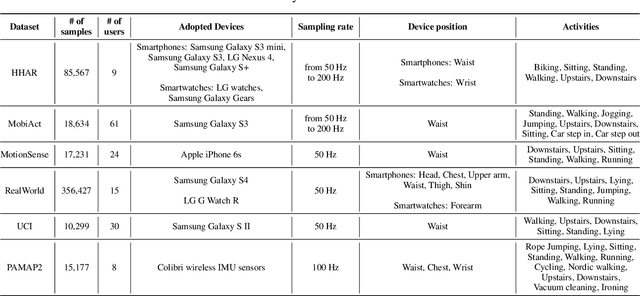
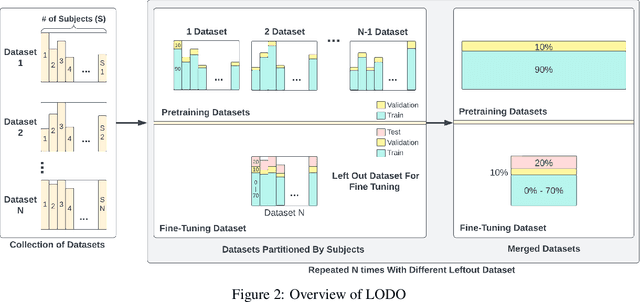
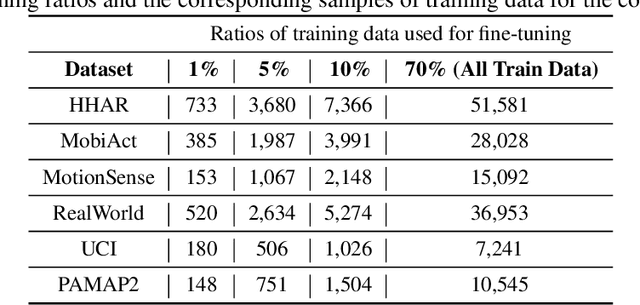
The use of supervised learning for Human Activity Recognition (HAR) on mobile devices leads to strong classification performances. Such an approach, however, requires large amounts of labeled data, both for the initial training of the models and for their customization on specific clients (whose data often differ greatly from the training data). This is actually impractical to obtain due to the costs, intrusiveness, and time-consuming nature of data annotation. Moreover, even with the help of a significant amount of labeled data, model deployment on heterogeneous clients faces difficulties in generalizing well on unseen data. Other domains, like Computer Vision or Natural Language Processing, have proposed the notion of pre-trained models, leveraging large corpora, to reduce the need for annotated data and better manage heterogeneity. This promising approach has not been implemented in the HAR domain so far because of the lack of public datasets of sufficient size. In this paper, we propose a novel strategy to combine publicly available datasets with the goal of learning a generalized HAR model that can be fine-tuned using a limited amount of labeled data on an unseen target domain. Our experimental evaluation, which includes experimenting with different state-of-the-art neural network architectures, shows that combining public datasets can significantly reduce the number of labeled samples required to achieve satisfactory performance on an unseen target domain.
Evaluation of Regularization-based Continual Learning Approaches: Application to HAR
Apr 26, 2023Pervasive computing allows the provision of services in many important areas, including the relevant and dynamic field of health and well-being. In this domain, Human Activity Recognition (HAR) has gained a lot of attention in recent years. Current solutions rely on Machine Learning (ML) models and achieve impressive results. However, the evolution of these models remains difficult, as long as a complete retraining is not performed. To overcome this problem, the concept of Continual Learning is very promising today and, more particularly, the techniques based on regularization. These techniques are particularly interesting for their simplicity and their low cost. Initial studies have been conducted and have shown promising outcomes. However, they remain very specific and difficult to compare. In this paper, we provide a comprehensive comparison of three regularization-based methods that we adapted to the HAR domain, highlighting their strengths and limitations. Our experiments were conducted on the UCI HAR dataset and the results showed that no single technique outperformed all others in all scenarios considered.
Evaluation and comparison of federated learning algorithms for Human Activity Recognition on smartphones
Oct 30, 2022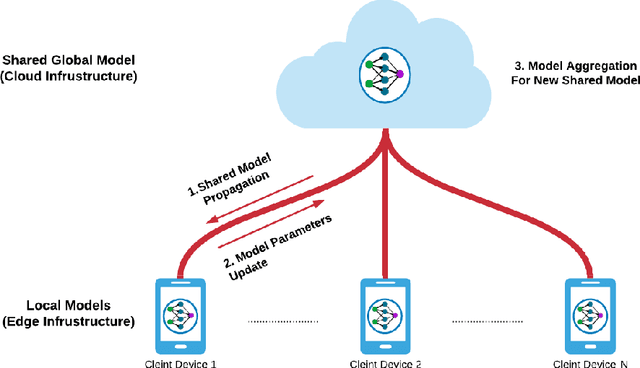
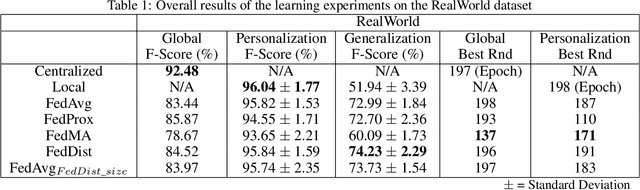
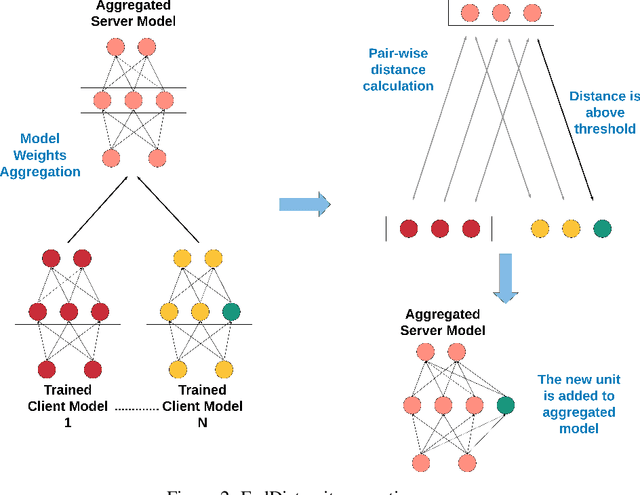

Pervasive computing promotes the integration of smart devices in our living spaces to develop services providing assistance to people. Such smart devices are increasingly relying on cloud-based Machine Learning, which raises questions in terms of security (data privacy), reliance (latency), and communication costs. In this context, Federated Learning (FL) has been introduced as a new machine learning paradigm enhancing the use of local devices. At the server level, FL aggregates models learned locally on distributed clients to obtain a more general model. In this way, no private data is sent over the network, and the communication cost is reduced. Unfortunately, however, the most popular federated learning algorithms have been shown not to be adapted to some highly heterogeneous pervasive computing environments. In this paper, we propose a new FL algorithm, termed FedDist, which can modify models (here, deep neural network) during training by identifying dissimilarities between neurons among the clients. This permits to account for clients' specificity without impairing generalization. FedDist evaluated with three state-of-the-art federated learning algorithms on three large heterogeneous mobile Human Activity Recognition datasets. Results have shown the ability of FedDist to adapt to heterogeneous data and the capability of FL to deal with asynchronous situations.
* arXiv admin note: substantial text overlap with arXiv:2110.10223
Lightweight Transformers for Human Activity Recognition on Mobile Devices
Sep 22, 2022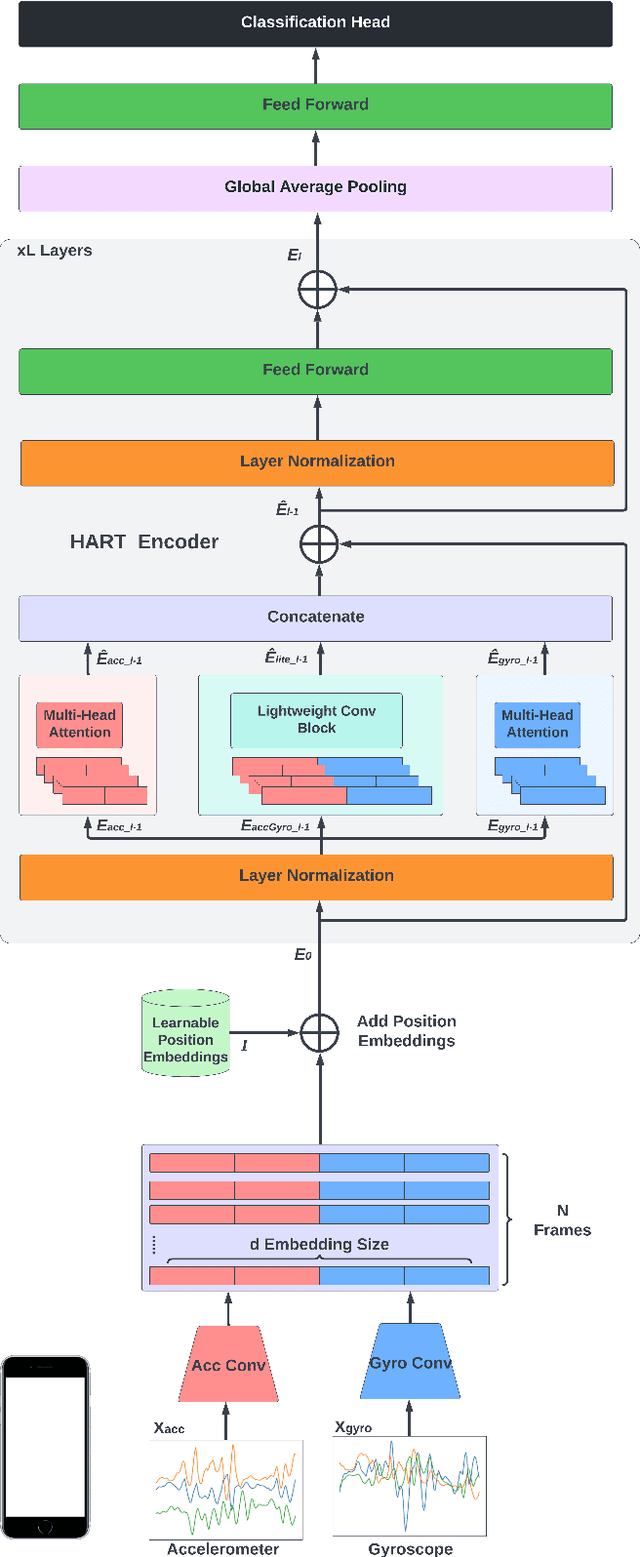
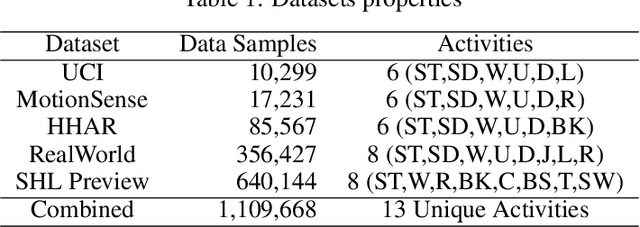
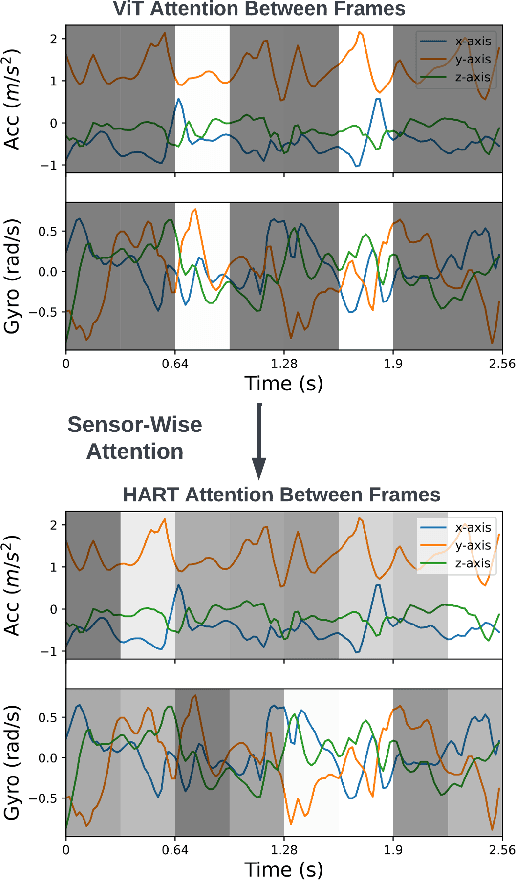
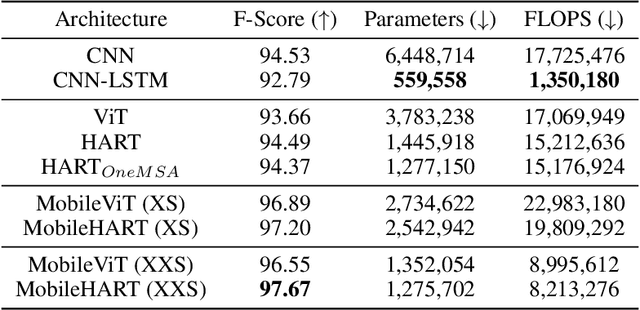
Human Activity Recognition (HAR) on mobile devices has shown to be achievable with lightweight neural models learned from data generated by the user's inertial measurement units (IMUs). Most approaches for instanced-based HAR have used Convolutional Neural Networks (CNNs), Long Short-Term Memory (LSTMs), or a combination of the two to achieve state-of-the-art results with real-time performances. Recently, the Transformers architecture in the language processing domain and then in the vision domain has pushed further the state-of-the-art over classical architectures. However, such Transformers architecture is heavyweight in computing resources, which is not well suited for embedded applications of HAR that can be found in the pervasive computing domain. In this study, we present Human Activity Recognition Transformer (HART), a lightweight, sensor-wise transformer architecture that has been specifically adapted to the domain of the IMUs embedded on mobile devices. Our experiments on HAR tasks with several publicly available datasets show that HART uses fewer FLoating-point Operations Per Second (FLOPS) and parameters while outperforming current state-of-the-art results. Furthermore, we present evaluations across various architectures on their performances in heterogeneous environments and show that our models can better generalize on different sensing devices or on-body positions.
Federated Self-Supervised Learning in Heterogeneous Settings: Limits of a Baseline Approach on HAR
Jul 17, 2022
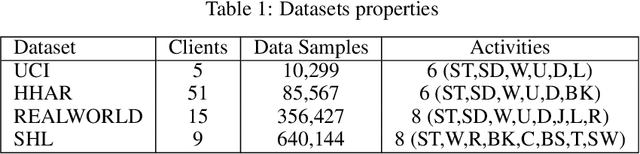
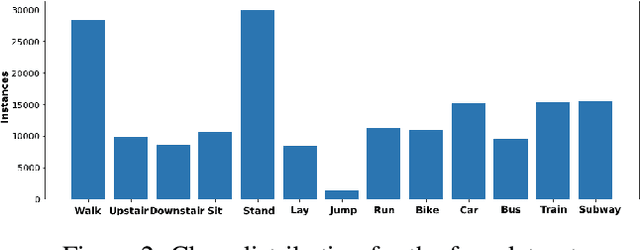

Federated Learning is a new machine learning paradigm dealing with distributed model learning on independent devices. One of the many advantages of federated learning is that training data stay on devices (such as smartphones), and only learned models are shared with a centralized server. In the case of supervised learning, labeling is entrusted to the clients. However, acquiring such labels can be prohibitively expensive and error-prone for many tasks, such as human activity recognition. Hence, a wealth of data remains unlabelled and unexploited. Most existing federated learning approaches that focus mainly on supervised learning have mostly ignored this mass of unlabelled data. Furthermore, it is unclear whether standard federated Learning approaches are suited to self-supervised learning. The few studies that have dealt with the problem have limited themselves to the favorable situation of homogeneous datasets. This work lays the groundwork for a reference evaluation of federated Learning with Semi-Supervised Learning in a realistic setting. We show that standard lightweight autoencoder and standard Federated Averaging fail to learn a robust representation for Human Activity Recognition with several realistic heterogeneous datasets. These findings advocate for a more intensive research effort in Federated Self Supervised Learning to exploit the mass of heterogeneous unlabelled data present on mobile devices.
Federated Continual Learning through distillation in pervasive computing
Jul 17, 2022



Federated Learning has been introduced as a new machine learning paradigm enhancing the use of local devices. At a server level, FL regularly aggregates models learned locally on distributed clients to obtain a more general model. Current solutions rely on the availability of large amounts of stored data at the client side in order to fine-tune the models sent by the server. Such setting is not realistic in mobile pervasive computing where data storage must be kept low and data characteristic can change dramatically. To account for this variability, a solution is to use the data regularly collected by the client to progressively adapt the received model. But such naive approach exposes clients to the well-known problem of catastrophic forgetting. To address this problem, we have defined a Federated Continual Learning approach which is mainly based on distillation. Our approach allows a better use of resources, eliminating the need to retrain from scratch at the arrival of new data and reducing memory usage by limiting the amount of data to be stored. This proposal has been evaluated in the Human Activity Recognition (HAR) domain and has shown to effectively reduce the catastrophic forgetting effect.
Federated Learning and catastrophic forgetting in pervasive computing: demonstration in HAR domain
Jul 17, 2022


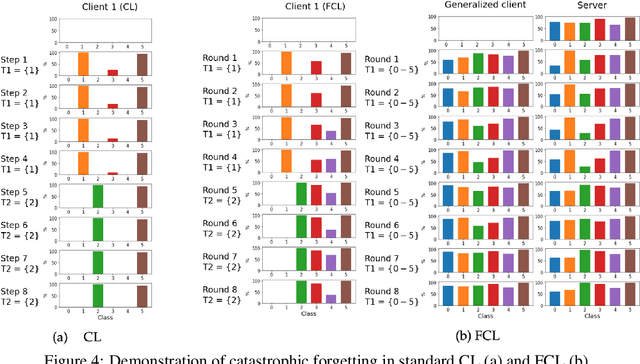
Federated Learning has been introduced as a new machine learning paradigm enhancing the use of local devices. At a server level, FL regularly aggregates models learned locally on distributed clients to obtain a more general model. In this way, no private data is sent over the network, and the communication cost is reduced. However, current solutions rely on the availability of large amounts of stored data at the client side in order to fine-tune the models sent by the server. Such setting is not realistic in mobile pervasive computing where data storage must be kept low and data characteristic (distribution) can change dramatically. To account for this variability, a solution is to use the data regularly collected by the client to progressively adapt the received model. But such naive approach exposes clients to the well-known problem of catastrophic forgetting. The purpose of this paper is to demonstrate this problem in the mobile human activity recognition context on smartphones.