 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Public Human Activity Recognition Datasets to Mitigate Labeled Data Scarcity
Jun 23, 2023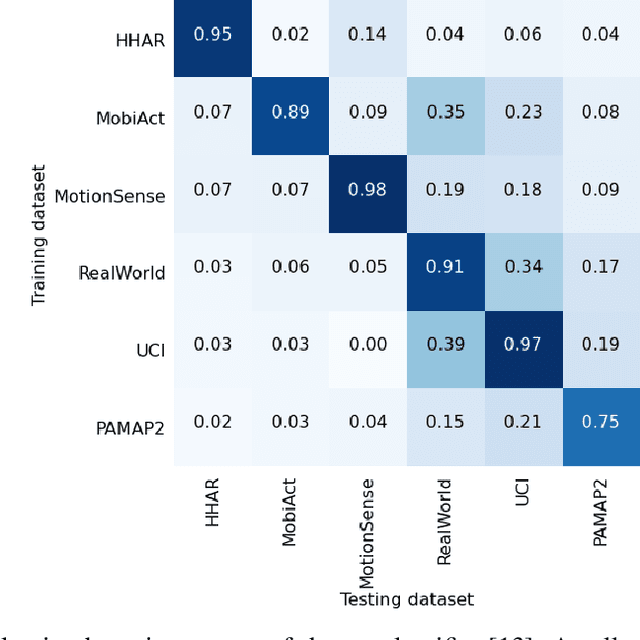
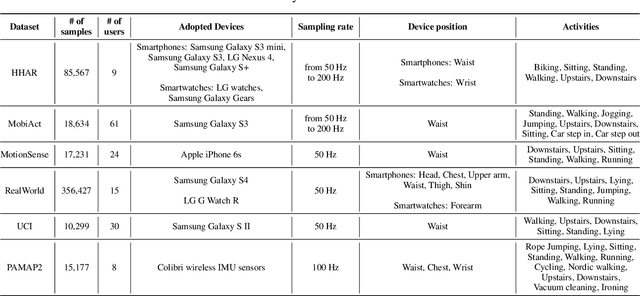
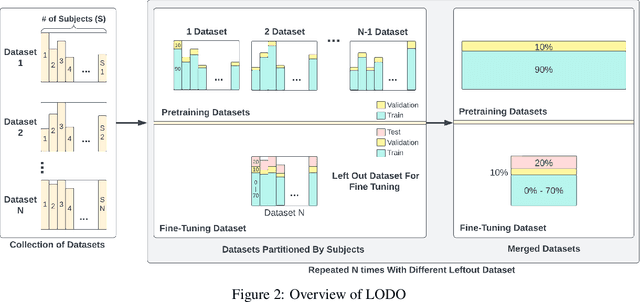
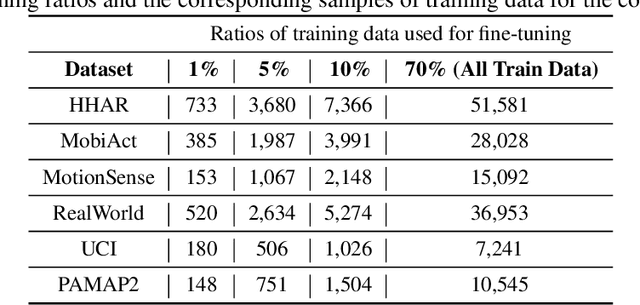
The use of supervised learning for Human Activity Recognition (HAR) on mobile devices leads to strong classification performances. Such an approach, however, requires large amounts of labeled data, both for the initial training of the models and for their customization on specific clients (whose data often differ greatly from the training data). This is actually impractical to obtain due to the costs, intrusiveness, and time-consuming nature of data annotation. Moreover, even with the help of a significant amount of labeled data, model deployment on heterogeneous clients faces difficulties in generalizing well on unseen data. Other domains, like Computer Vision or Natural Language Processing, have proposed the notion of pre-trained models, leveraging large corpora, to reduce the need for annotated data and better manage heterogeneity. This promising approach has not been implemented in the HAR domain so far because of the lack of public datasets of sufficient size. In this paper, we propose a novel strategy to combine publicly available datasets with the goal of learning a generalized HAR model that can be fine-tuned using a limited amount of labeled data on an unseen target domain. Our experimental evaluation, which includes experimenting with different state-of-the-art neural network architectures, shows that combining public datasets can significantly reduce the number of labeled samples required to achieve satisfactory performance on an unseen target domain.
Personalized Semi-Supervised Federated Learning for Human Activity Recognition
Apr 19, 2021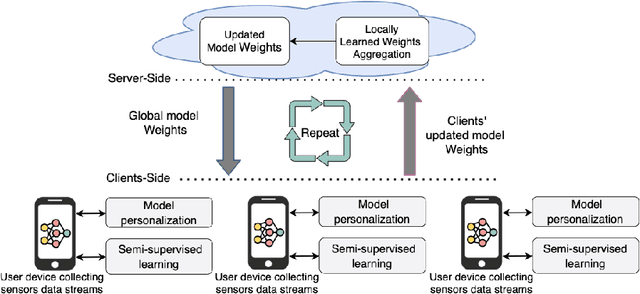
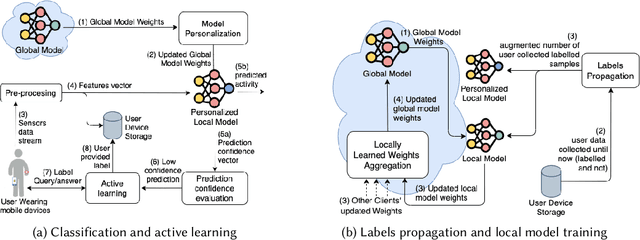
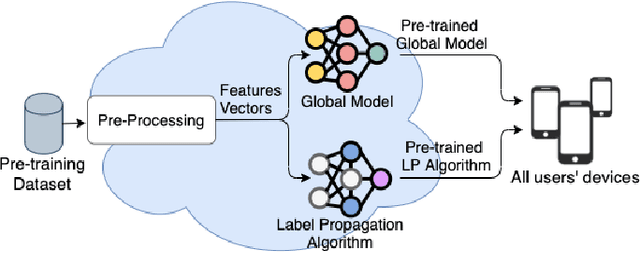

The most effective data-driven methods for human activities recognition (HAR) are based on supervised learning applied to the continuous stream of sensors data. However, these methods perform well on restricted sets of activities in domains for which there is a fully labeled dataset. It is still a challenge to cope with the intra- and inter-variability of activity execution among different subjects in large scale real world deployment. Semi-supervised learning approaches for HAR have been proposed to address the challenge of acquiring the large amount of labeled data that is necessary in realistic settings. However, their centralised architecture incurs in the scalability and privacy problems when the process involves a large number of users. Federated Learning (FL) is a promising paradigm to address these problems. However, the FL methods that have been proposed for HAR assume that the participating users can always obtain labels to train their local models. In this work, we propose FedHAR: a novel hybrid method for HAR that combines semi-supervised and federated learning. Indeed, FedHAR combines active learning and label propagation to semi-automatically annotate the local streams of unlabeled sensor data, and it relies on FL to build a global activity model in a scalable and privacy-aware fashion. FedHAR also includes a transfer learning strategy to personalize the global model on each user. We evaluated our method on two public datasets, showing that FedHAR reaches recognition rates and personalization capabilities similar to state-of-the-art FL supervised approaches. As a major advantage, FedHAR only requires a very limited number of annotated data to populate a pre-trained model and a small number of active learning questions that quickly decrease while using the system, leading to an effective and scalable solution for the data scarcity problem of HAR.
Context-driven Active and Incremental Activity Recognition
Jun 07, 2019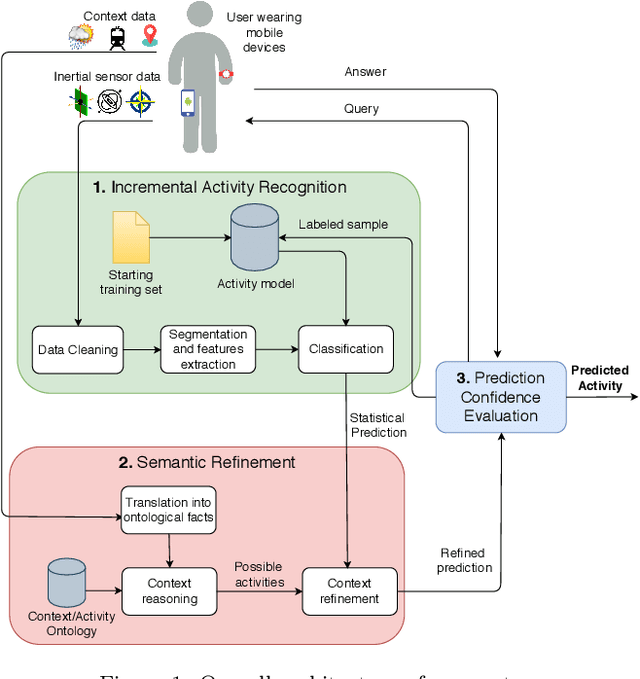


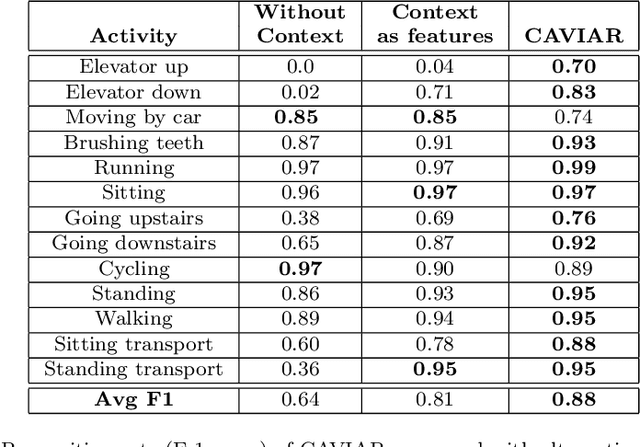
Human activity recognition based on mobile device sensor data has been an active research area in mobile and pervasive computing for several years. While the majority of the proposed techniques are based on supervised learning, semi-supervised approaches are being considered to significantly reduce the size of the training set required to initialize the recognition model. These approaches usually apply self-training or active learning to incrementally refine the model, but their effectiveness seems to be limited to a restricted set of physical activities. We claim that the context which surrounds the user (e.g., semantic location, proximity to transportation routes, time of the day) combined with common knowledge about the relationship between this context and human activities could be effective in significantly increasing the set of recognized activities including those that are difficult to discriminate only considering inertial sensors, and the ones that are highly context-dependent. In this paper, we propose CAVIAR, a novel hybrid semi-supervised and knowledge-based system for real-time activity recognition. Our method applies semantic reasoning to context data to refine the prediction of a semi-supervised classifier. The context-refined predictions are used as new labeled samples to update the classifier combining self-training and active learning techniques. Results on a real dataset obtained from 26 subjects show the effectiveness of the context-aware approach both on the recognition rates and on the number of queries to the subjects generated by the active learning module. In order to evaluate the impact of context reasoning, we also compare CAVIAR with a purely statistical version, considering features computed on context data as part of the machine learning process.