 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomusFM: A Foundation Model for Smart-Home Sensor Data
Feb 02, 2026Smart-home sensor data holds significant potential for several applications, including healthcare monitoring and assistive technologies. Existing approaches, however, face critical limitations. Supervised models require impractical amounts of labeled data. Foundation models for activity recognition focus only on inertial sensors, failing to address the unique characteristics of smart-home binary sensor events: their sparse, discrete nature combined with rich semantic associations. LLM-based approaches, while tested in this domain, still raise several issues regarding the need for natural language descriptions or prompting, and reliance on either external services or expensive hardware, making them infeasible in real-life scenarios due to privacy and cost concerns. We introduce DomusFM, the first foundation model specifically designed and pretrained for smart-home sensor data. DomusFM employs a self-supervised dual contrastive learning paradigm to capture both token-level semantic attributes and sequence-level temporal dependencies. By integrating semantic embeddings from a lightweight language model and specialized encoders for temporal patterns and binary states, DomusFM learns generalizable representations that transfer across environments and tasks related to activity and event analysis. Through leave-one-dataset-out evaluation across seven public smart-home datasets, we demonstrate that DomusFM outperforms state-of-the-art baselines on different downstream tasks, achieving superior performance even with only 5% of labeled training data available for fine-tuning. Our approach addresses data scarcity while maintaining practical deployability for real-world smart-home systems.
Improving Zero-shot ADL Recognition with Large Language Models through Event-based Context and Confidence
Jan 13, 2026Unobtrusive sensor-based recognition of Activities of Daily Living (ADLs) in smart homes by processing data collected from IoT sensing devices supports applications such as healthcare, safety, and energy management. Recent zero-shot methods based on Large Language Models (LLMs) have the advantage of removing the reliance on labeled ADL sensor data. However, existing approaches rely on time-based segmentation, which is poorly aligned with the contextual reasoning capabilities of LLMs. Moreover, existing approaches lack methods for estimating prediction confidence. This paper proposes to improve zero-shot ADL recognition with event-based segmentation and a novel method for estimating prediction confidence. Our experimental evaluation shows that event-based segmentation consistently outperforms time-based LLM approaches on complex, realistic datasets and surpasses supervised data-driven methods, even with relatively small LLMs (e.g., Gemma 3 27B). The proposed confidence measure effectively distinguishes correct from incorrect predictions.
The SERENADE project: Sensor-Based Explainable Detection of Cognitive Decline
Apr 11, 2025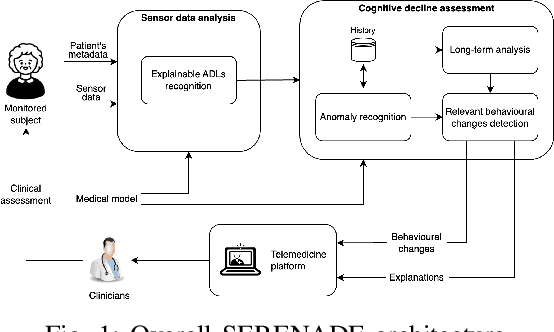
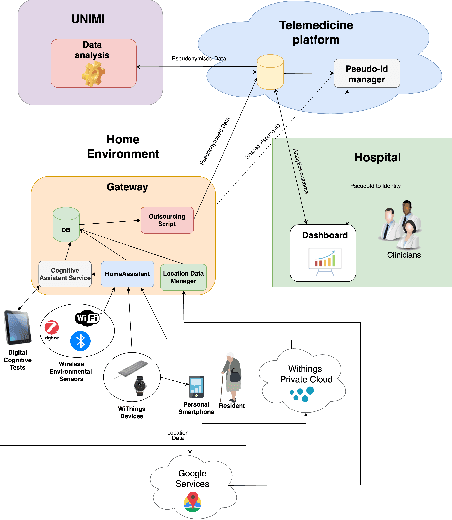
Mild Cognitive Impairment (MCI) affects 12-18% of individuals over 60. MCI patients exhibit cognitive dysfunctions without significant daily functional loss. While MCI may progress to dementia, predicting this transition remains a clinical challenge due to limited and unreliable indicators. Behavioral changes, like in the execution of Activities of Daily Living (ADLs), can signal such progression. Sensorized smart homes and wearable devices offer an innovative solution for continuous, non-intrusive monitoring ADLs for MCI patients. However, current machine learning models for detecting behavioral changes lack transparency, hindering clinicians' trust. This paper introduces the SERENADE project, a European Union-funded initiative that aims to detect and explain behavioral changes associated with cognitive decline using explainable AI methods. SERENADE aims at collecting one year of data from 30 MCI patients living alone, leveraging AI to support clinical decision-making and offering a new approach to early dementia detection.
GNN-XAR: A Graph Neural Network for Explainable Activity Recognition in Smart Homes
Feb 25, 2025



Sensor-based Human Activity Recognition (HAR) in smart home environments is crucial for several applications, especially in the healthcare domain. The majority of the existing approaches leverage deep learning models. While these approaches are effective, the rationale behind their outputs is opaque. Recently, eXplainable Artificial Intelligence (XAI) approaches emerged to provide intuitive explanations to the output of HAR models. To the best of our knowledge, these approaches leverage classic deep models like CNNs or RNNs. Recently, Graph Neural Networks (GNNs) proved to be effective for sensor-based HAR. However, existing approaches are not designed with explainability in mind. In this work, we propose the first explainable Graph Neural Network explicitly designed for smart home HAR. Our results on two public datasets show that this approach provides better explanations than state-of-the-art methods while also slightly improving the recognition rate.
ContextGPT: Infusing LLMs Knowledge into Neuro-Symbolic Activity Recognition Models
Mar 11, 2024
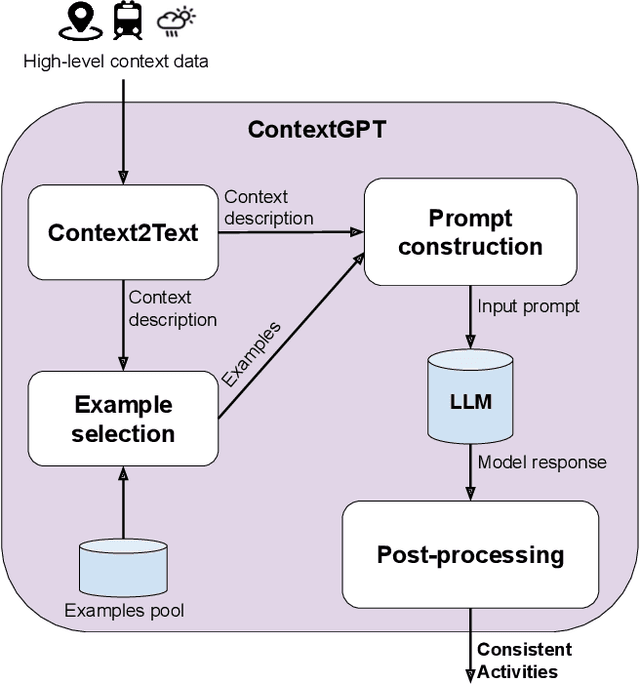


Context-aware Human Activity Recognition (HAR) is a hot research area in mobile computing, and the most effective solutions in the literature are based on supervised deep learning models. However, the actual deployment of these systems is limited by the scarcity of labeled data that is required for training. Neuro-Symbolic AI (NeSy) provides an interesting research direction to mitigate this issue, by infusing common-sense knowledge about human activities and the contexts in which they can be performed into HAR deep learning classifiers. Existing NeSy methods for context-aware HAR rely on knowledge encoded in logic-based models (e.g., ontologies) whose design, implementation, and maintenance to capture new activities and contexts require significant human engineering efforts, technical knowledge, and domain expertise. Recent works show that pre-trained Large Language Models (LLMs) effectively encode common-sense knowledge about human activities. In this work, we propose ContextGPT: a novel prompt engineering approach to retrieve from LLMs common-sense knowledge about the relationship between human activities and the context in which they are performed. Unlike ontologies, ContextGPT requires limited human effort and expertise. An extensive evaluation carried out on two public datasets shows how a NeSy model obtained by infusing common-sense knowledge from ContextGPT is effective in data scarcity scenarios, leading to similar (and sometimes better) recognition rates than logic-based approaches with a fraction of the effort.
Combining Public Human Activity Recognition Datasets to Mitigate Labeled Data Scarcity
Jun 23, 2023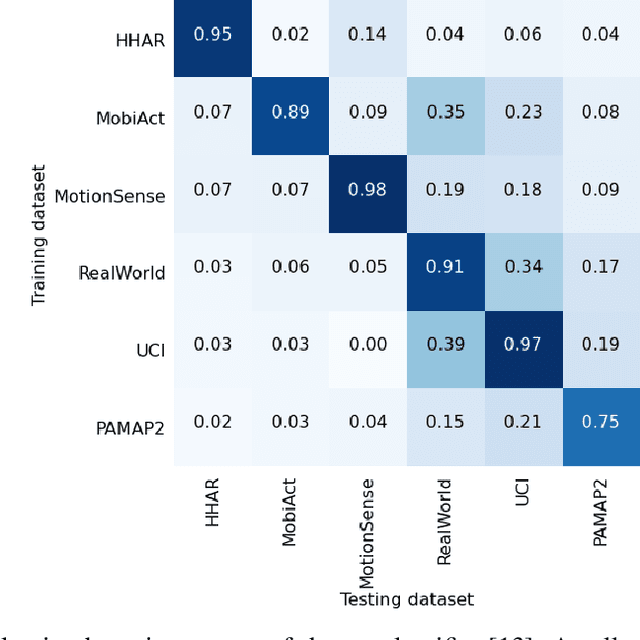
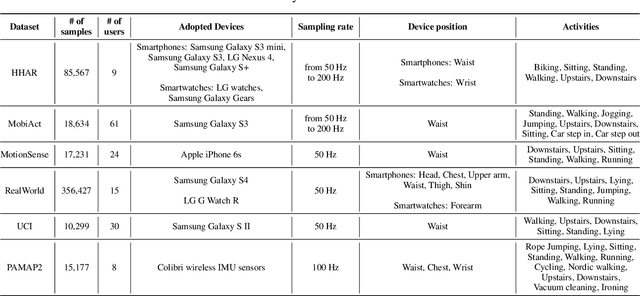
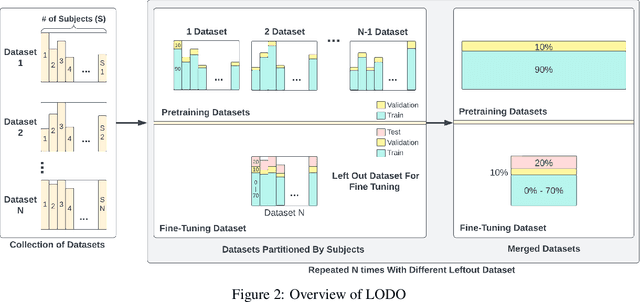
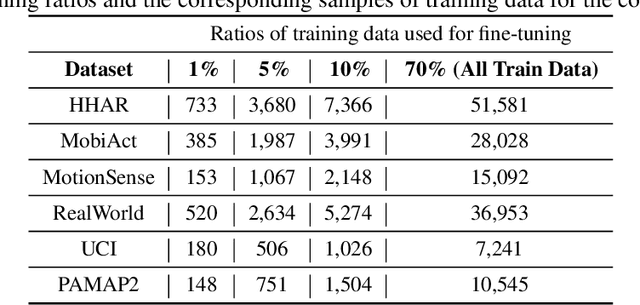
The use of supervised learning for Human Activity Recognition (HAR) on mobile devices leads to strong classification performances. Such an approach, however, requires large amounts of labeled data, both for the initial training of the models and for their customization on specific clients (whose data often differ greatly from the training data). This is actually impractical to obtain due to the costs, intrusiveness, and time-consuming nature of data annotation. Moreover, even with the help of a significant amount of labeled data, model deployment on heterogeneous clients faces difficulties in generalizing well on unseen data. Other domains, like Computer Vision or Natural Language Processing, have proposed the notion of pre-trained models, leveraging large corpora, to reduce the need for annotated data and better manage heterogeneity. This promising approach has not been implemented in the HAR domain so far because of the lack of public datasets of sufficient size. In this paper, we propose a novel strategy to combine publicly available datasets with the goal of learning a generalized HAR model that can be fine-tuned using a limited amount of labeled data on an unseen target domain. Our experimental evaluation, which includes experimenting with different state-of-the-art neural network architectures, shows that combining public datasets can significantly reduce the number of labeled samples required to achieve satisfactory performance on an unseen target domain.
Neuro-Symbolic Approaches for Context-Aware Human Activity Recognition
Jun 08, 2023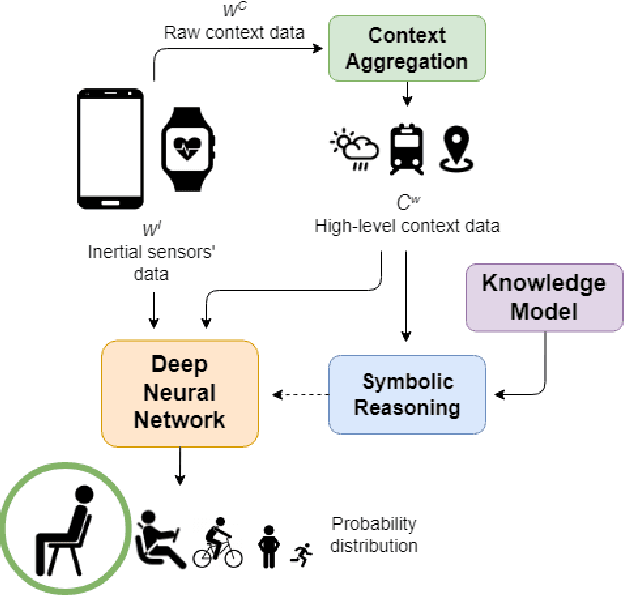
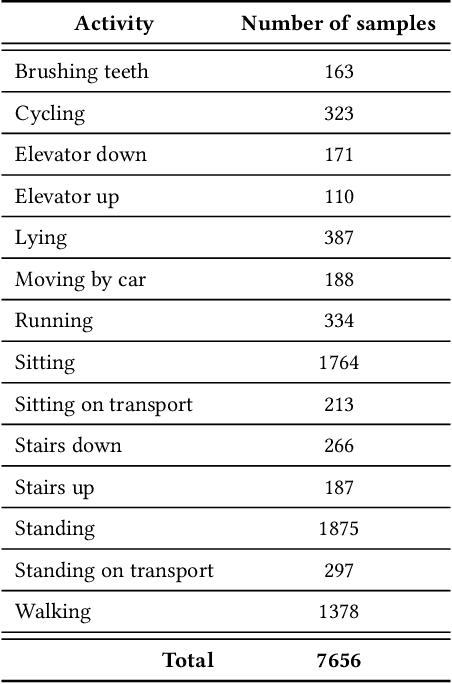
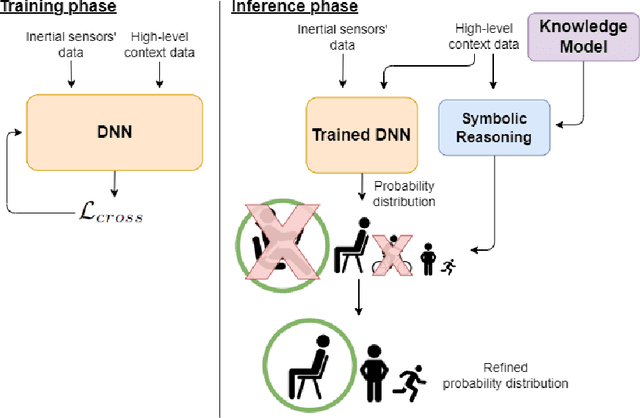
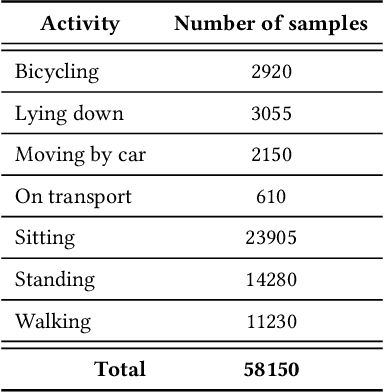
Deep Learning models are a standard solution for sensor-based Human Activity Recognition (HAR), but their deployment is often limited by labeled data scarcity and models' opacity. Neuro-Symbolic AI (NeSy) provides an interesting research direction to mitigate these issues by infusing knowledge about context information into HAR deep learning classifiers. However, existing NeSy methods for context-aware HAR require computationally expensive symbolic reasoners during classification, making them less suitable for deployment on resource-constrained devices (e.g., mobile devices). Additionally, NeSy approaches for context-aware HAR have never been evaluated on in-the-wild datasets, and their generalization capabilities in real-world scenarios are questionable. In this work, we propose a novel approach based on a semantic loss function that infuses knowledge constraints in the HAR model during the training phase, avoiding symbolic reasoning during classification. Our results on scripted and in-the-wild datasets show the impact of different semantic loss functions in outperforming a purely data-driven model. We also compare our solution with existing NeSy methods and analyze each approach's strengths and weaknesses. Our semantic loss remains the only NeSy solution that can be deployed as a single DNN without the need for symbolic reasoning modules, reaching recognition rates close (and better in some cases) to existing approaches.
SelfAct: Personalized Activity Recognition based on Self-Supervised and Active Learning
Apr 19, 2023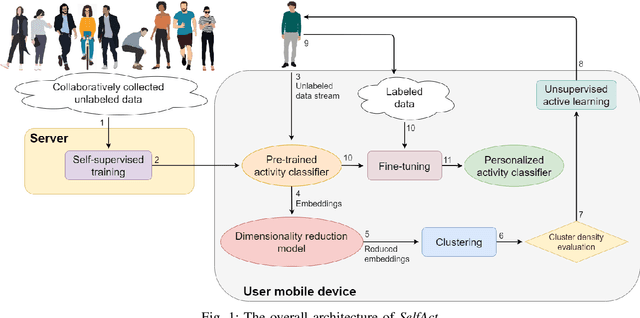
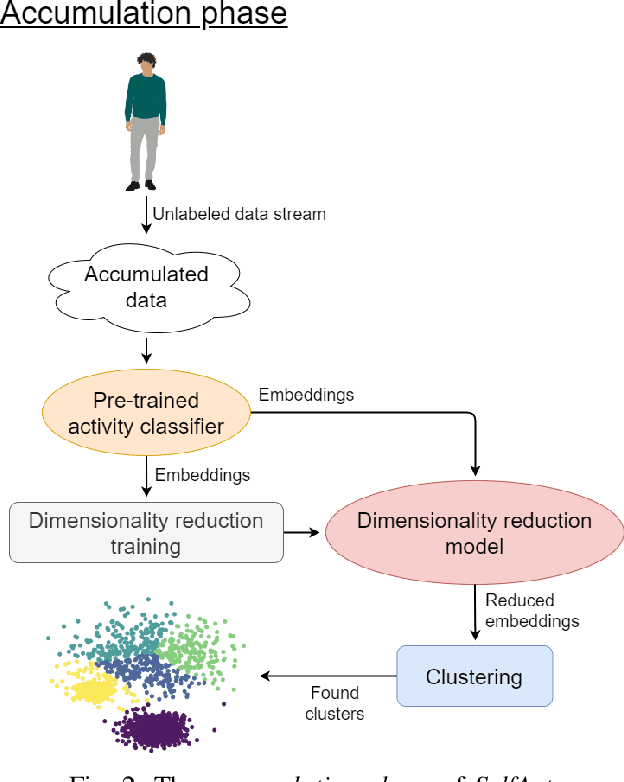
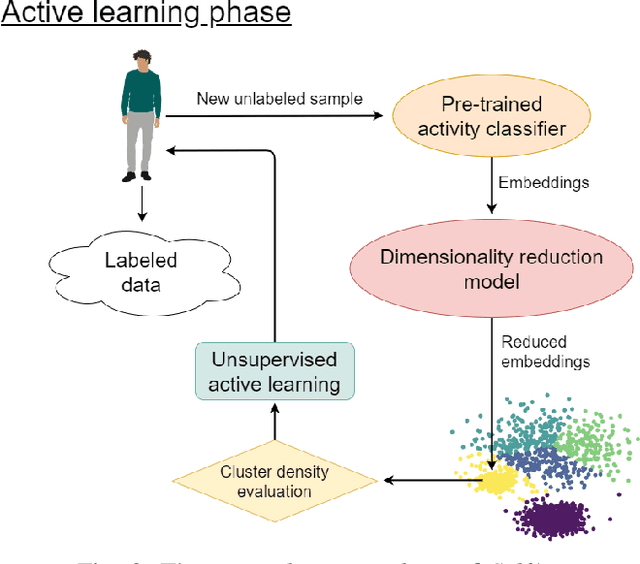
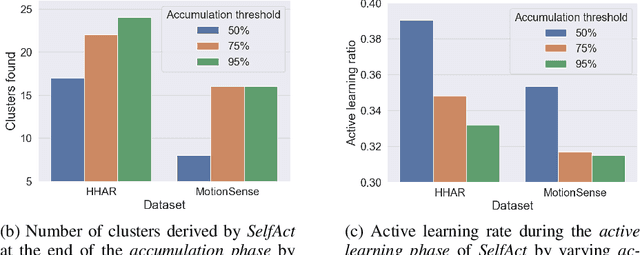
Supervised Deep Learning (DL) models are currently the leading approach for sensor-based Human Activity Recognition (HAR) on wearable and mobile devices. However, training them requires large amounts of labeled data whose collection is often time-consuming, expensive, and error-prone. At the same time, due to the intra- and inter-variability of activity execution, activity models should be personalized for each user. In this work, we propose SelfAct: a novel framework for HAR combining self-supervised and active learning to mitigate these problems. SelfAct leverages a large pool of unlabeled data collected from many users to pre-train through self-supervision a DL model, with the goal of learning a meaningful and efficient latent representation of sensor data. The resulting pre-trained model can be locally used by new users, which will fine-tune it thanks to a novel unsupervised active learning strategy. Our experiments on two publicly available HAR datasets demonstrate that SelfAct achieves results that are close to or even better than the ones of fully supervised approaches with a small number of active learning queries.
Ultrasound Detection of Subquadricipital Recess Distension
Nov 22, 2022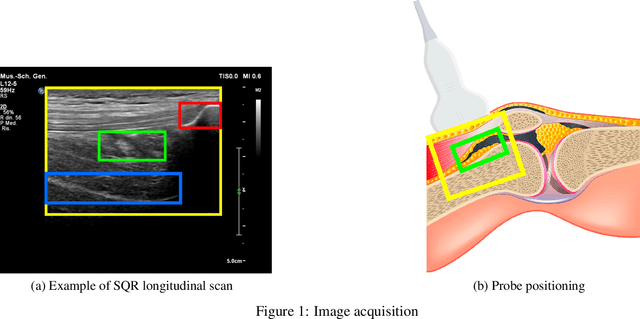
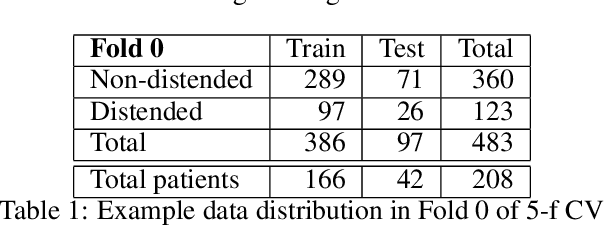
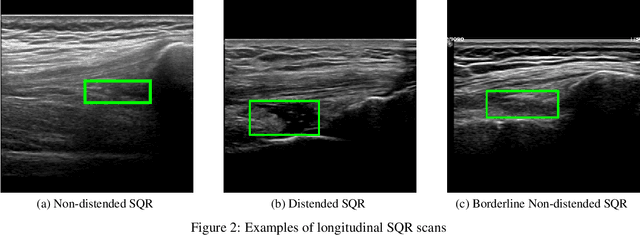

Joint bleeding is a common condition for people with hemophilia and, if untreated, can result in hemophilic arthropathy. Ultrasound imaging has recently emerged as an effective tool to diagnose joint recess distension caused by joint bleeding. However, no computer-aided diagnosis tool exists to support the practitioner in the diagnosis process. This paper addresses the problem of automatically detecting the recess and assessing whether it is distended in knee ultrasound images collected in patients with hemophilia. After framing the problem, we propose two different approaches: the first one adopts a one-stage object detection algorithm, while the second one is a multi-task approach with a classification and a detection branch. The experimental evaluation, conducted with $483$ annotated images, shows that the solution based on object detection alone has a balanced accuracy score of $0.74$ with a mean IoU value of $0.66$, while the multi-task approach has a higher balanced accuracy value ($0.78$) at the cost of a slightly lower mean IoU value.
Personalized Semi-Supervised Federated Learning for Human Activity Recognition
Apr 19, 2021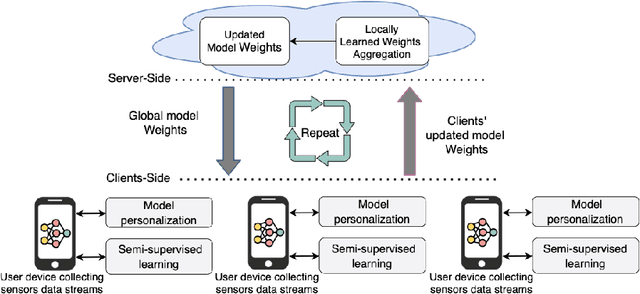
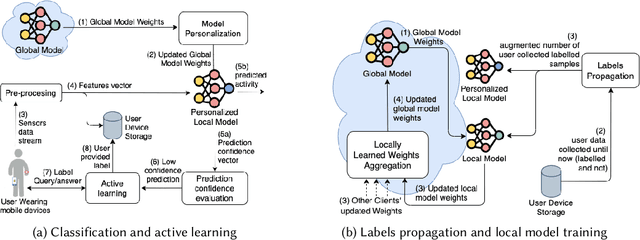
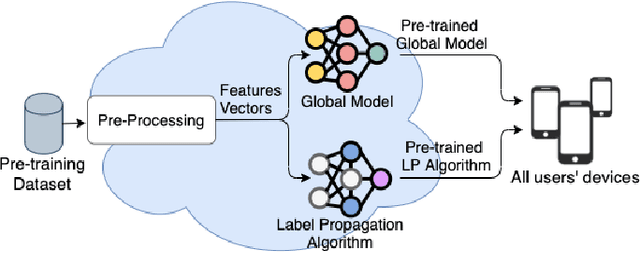

The most effective data-driven methods for human activities recognition (HAR) are based on supervised learning applied to the continuous stream of sensors data. However, these methods perform well on restricted sets of activities in domains for which there is a fully labeled dataset. It is still a challenge to cope with the intra- and inter-variability of activity execution among different subjects in large scale real world deployment. Semi-supervised learning approaches for HAR have been proposed to address the challenge of acquiring the large amount of labeled data that is necessary in realistic settings. However, their centralised architecture incurs in the scalability and privacy problems when the process involves a large number of users. Federated Learning (FL) is a promising paradigm to address these problems. However, the FL methods that have been proposed for HAR assume that the participating users can always obtain labels to train their local models. In this work, we propose FedHAR: a novel hybrid method for HAR that combines semi-supervised and federated learning. Indeed, FedHAR combines active learning and label propagation to semi-automatically annotate the local streams of unlabeled sensor data, and it relies on FL to build a global activity model in a scalable and privacy-aware fashion. FedHAR also includes a transfer learning strategy to personalize the global model on each user. We evaluated our method on two public datasets, showing that FedHAR reaches recognition rates and personalization capabilities similar to state-of-the-art FL supervised approaches. As a major advantage, FedHAR only requires a very limited number of annotated data to populate a pre-trained model and a small number of active learning questions that quickly decrease while using the system, leading to an effective and scalable solution for the data scarcity problem of HAR.