 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Self-Supervised Learning in Heterogeneous Settings: Limits of a Baseline Approach on HAR
Jul 17, 2022
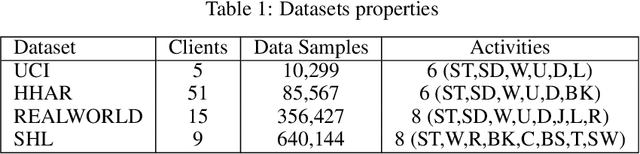
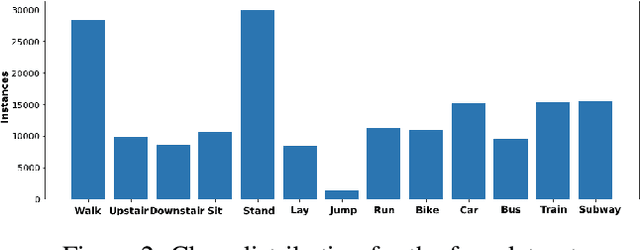

Federated Learning is a new machine learning paradigm dealing with distributed model learning on independent devices. One of the many advantages of federated learning is that training data stay on devices (such as smartphones), and only learned models are shared with a centralized server. In the case of supervised learning, labeling is entrusted to the clients. However, acquiring such labels can be prohibitively expensive and error-prone for many tasks, such as human activity recognition. Hence, a wealth of data remains unlabelled and unexploited. Most existing federated learning approaches that focus mainly on supervised learning have mostly ignored this mass of unlabelled data. Furthermore, it is unclear whether standard federated Learning approaches are suited to self-supervised learning. The few studies that have dealt with the problem have limited themselves to the favorable situation of homogeneous datasets. This work lays the groundwork for a reference evaluation of federated Learning with Semi-Supervised Learning in a realistic setting. We show that standard lightweight autoencoder and standard Federated Averaging fail to learn a robust representation for Human Activity Recognition with several realistic heterogeneous datasets. These findings advocate for a more intensive research effort in Federated Self Supervised Learning to exploit the mass of heterogeneous unlabelled data present on mobile devices.