 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Dead Salmons of AI Interpretability
Dec 21, 2025In a striking neuroscience study, the authors placed a dead salmon in an MRI scanner and showed it images of humans in social situations. Astonishingly, standard analyses of the time reported brain regions predictive of social emotions. The explanation, of course, was not supernatural cognition but a cautionary tale about misapplied statistical inference. In AI interpretability, reports of similar ''dead salmon'' artifacts abound: feature attribution, probing, sparse auto-encoding, and even causal analyses can produce plausible-looking explanations for randomly initialized neural networks. In this work, we examine this phenomenon and argue for a pragmatic statistical-causal reframing: explanations of computational systems should be treated as parameters of a (statistical) model, inferred from computational traces. This perspective goes beyond simply measuring statistical variability of explanations due to finite sampling of input data; interpretability methods become statistical estimators, and findings should be tested against explicit and meaningful alternative computational hypotheses, with uncertainty quantified with respect to the postulated statistical model. It also highlights important theoretical issues, such as the identifiability of common interpretability queries, which we argue is critical to understand the field's susceptibility to false discoveries, poor generalizability, and high variance. More broadly, situating interpretability within the standard toolkit of statistical inference opens promising avenues for future work aimed at turning AI interpretability into a pragmatic and rigorous science.
Mechanistic Interpretability as Statistical Estimation: A Variance Analysis of EAP-IG
Oct 02, 2025The development of trustworthy artificial intelligence requires moving beyond black-box performance metrics toward an understanding of models' internal computations. Mechanistic Interpretability (MI) aims to meet this need by identifying the algorithmic mechanisms underlying model behaviors. Yet, the scientific rigor of MI critically depends on the reliability of its findings. In this work, we argue that interpretability methods, such as circuit discovery, should be viewed as statistical estimators, subject to questions of variance and robustness. To illustrate this statistical framing, we present a systematic stability analysis of a state-of-the-art circuit discovery method: EAP-IG. We evaluate its variance and robustness through a comprehensive suite of controlled perturbations, including input resampling, prompt paraphrasing, hyperparameter variation, and injected noise within the causal analysis itself. Across a diverse set of models and tasks, our results demonstrate that EAP-IG exhibits high structural variance and sensitivity to hyperparameters, questioning the stability of its findings. Based on these results, we offer a set of best-practice recommendations for the field, advocating for the routine reporting of stability metrics to promote a more rigorous and statistically grounded science of interpretability.
Everything, Everywhere, All at Once: Is Mechanistic Interpretability Identifiable?
Feb 28, 2025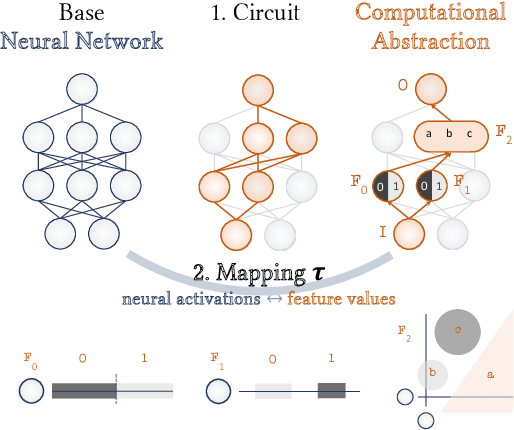
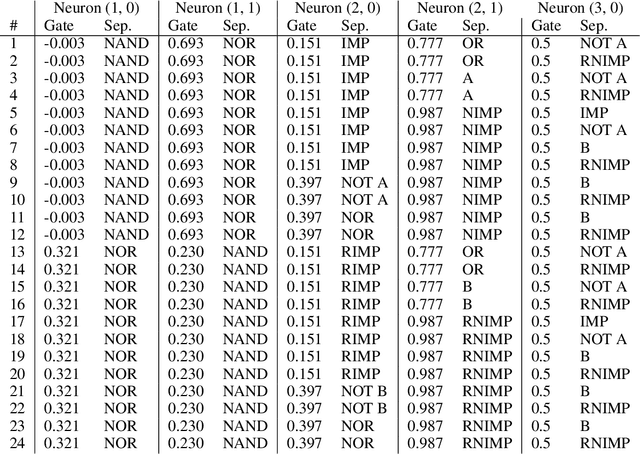
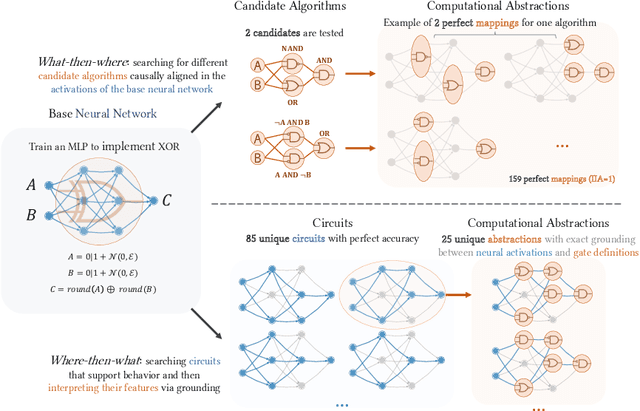

As AI systems are used in high-stakes applications, ensuring interpretability is crucial. Mechanistic Interpretability (MI) aims to reverse-engineer neural networks by extracting human-understandable algorithms to explain their behavior. This work examines a key question: for a given behavior, and under MI's criteria, does a unique explanation exist? Drawing on identifiability in statistics, where parameters are uniquely inferred under specific assumptions, we explore the identifiability of MI explanations. We identify two main MI strategies: (1) "where-then-what," which isolates a circuit replicating model behavior before interpreting it, and (2) "what-then-where," which starts with candidate algorithms and searches for neural activation subspaces implementing them, using causal alignment. We test both strategies on Boolean functions and small multi-layer perceptrons, fully enumerating candidate explanations. Our experiments reveal systematic non-identifiability: multiple circuits can replicate behavior, a circuit can have multiple interpretations, several algorithms can align with the network, and one algorithm can align with different subspaces. Is uniqueness necessary? A pragmatic approach may require only predictive and manipulability standards. If uniqueness is essential for understanding, stricter criteria may be needed. We also reference the inner interpretability framework, which validates explanations through multiple criteria. This work contributes to defining explanation standards in AI.
Novel-WD: Exploring acquisition of Novel World Knowledge in LLMs Using Prefix-Tuning
Aug 30, 2024Teaching new information to pre-trained large language models (PLM) is a crucial but challenging task. Model adaptation techniques, such as fine-tuning and parameter-efficient training have been shown to store new facts at a slow rate; continual learning is an option but is costly and prone to catastrophic forgetting. This work studies and quantifies how PLM may learn and remember new world knowledge facts that do not occur in their pre-training corpus, which only contains world knowledge up to a certain date. To that purpose, we first propose Novel-WD, a new dataset consisting of sentences containing novel facts extracted from recent Wikidata updates, along with two evaluation tasks in the form of causal language modeling and multiple choice questions (MCQ). We make this dataset freely available to the community, and release a procedure to later build new versions of similar datasets with up-to-date information. We also explore the use of prefix-tuning for novel information learning, and analyze how much information can be stored within a given prefix. We show that a single fact can reliably be encoded within a single prefix, and that the prefix capacity increases with its length and with the base model size.