 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLadder Up, Memory Down: Low-Cost Fine-Tuning With Side Nets
Dec 16, 2025Fine-tuning large language models (LLMs) is often limited by the memory available on commodity GPUs. Parameter-efficient fine-tuning (PEFT) methods such as QLoRA reduce the number of trainable parameters, yet still incur high memory usage induced by the backward pass in the full model. We revisit Ladder Side Tuning (LST), a rarely explored PEFT technique that adds a lightweight side network, and show that it matches QLoRA's compute scaling slope while cutting peak memory by 50\%. Across different downstream benchmarks spanning natural language understanding, mathematical and LLM-critic tasks, LST has competitive performance with QLoRA's accuracy on average while being much more memory-efficient. This efficiency enables fine-tuning of 7B-parameter models on a single 12 GB consumer GPU with 2k-token contexts, requiring no gradient checkpointing\textemdash conditions under which QLoRA exhausts memory. Beyond memory efficiency, we also establish scaling laws showing that LST scales similarly to QLoRA. We exploit Ladder's architectural flexibility by introducing xLadder, a depth-extended variant that increases effective depth via cross-connections and shortens chain-of-thought (CoT) at fixed parameter count. Ladder is strong when memory is the bottleneck; xLadder builds on this by enabling deeper reasoning without additional memory overhead.
Speech Language Models for Under-Represented Languages: Insights from Wolof
Sep 18, 2025We present our journey in training a speech language model for Wolof, an underrepresented language spoken in West Africa, and share key insights. We first emphasize the importance of collecting large-scale, spontaneous, high-quality speech data, and show that continued pretraining HuBERT on this dataset outperforms both the base model and African-centric models on ASR. We then integrate this speech encoder into a Wolof LLM to train the first Speech LLM for this language, extending its capabilities to tasks such as speech translation. Furthermore, we explore training the Speech LLM to perform multi-step Chain-of-Thought before transcribing or translating. Our results show that the Speech LLM not only improves speech recognition but also performs well in speech translation. The models and the code will be openly shared.
LibriQuote: A Speech Dataset of Fictional Character Utterances for Expressive Zero-Shot Speech Synthesis
Sep 04, 2025Text-to-speech (TTS) systems have recently achieved more expressive and natural speech synthesis by scaling to large speech datasets. However, the proportion of expressive speech in such large-scale corpora is often unclear. Besides, existing expressive speech corpora are typically smaller in scale and primarily used for benchmarking TTS systems. In this paper, we introduce the LibriQuote dataset, an English corpus derived from read audiobooks, designed for both fine-tuning and benchmarking expressive zero-shot TTS system. The training dataset includes 12.7K hours of read, non-expressive speech and 5.3K hours of mostly expressive speech drawn from character quotations. Each utterance in the expressive subset is supplemented with the context in which it was written, along with pseudo-labels of speech verbs and adverbs used to describe the quotation (\textit{e.g. ``he whispered softly''}). Additionally, we provide a challenging 7.5 hour test set intended for benchmarking TTS systems: given a neutral reference speech as input, we evaluate system's ability to synthesize an expressive utterance while preserving reference timbre. We validate qualitatively the test set by showing that it covers a wide range of emotions compared to non-expressive speech, along with various accents. Extensive subjective and objective evaluations show that fine-tuning a baseline TTS system on LibriQuote significantly improves its synthesized speech intelligibility, and that recent systems fail to synthesize speech as expressive and natural as the ground-truth utterances. The dataset and evaluation code are freely available. Audio samples can be found at https://libriquote.github.io/.
The Lucie-7B LLM and the Lucie Training Dataset: Open resources for multilingual language generation
Mar 15, 2025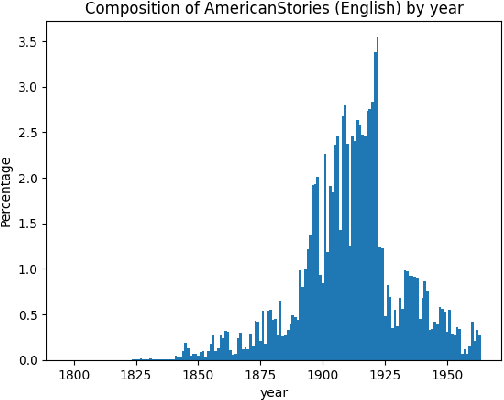

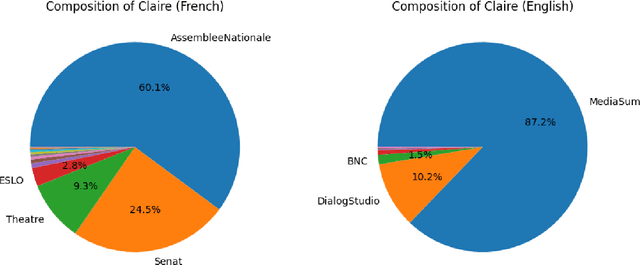
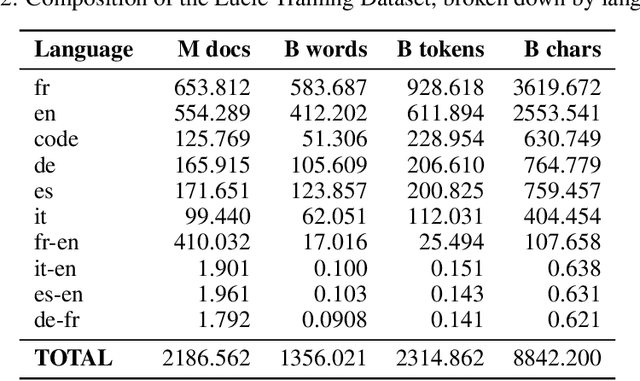
We present both the Lucie Training Dataset and the Lucie-7B foundation model. The Lucie Training Dataset is a multilingual collection of textual corpora centered around French and designed to offset anglo-centric biases found in many datasets for large language model pretraining. Its French data is pulled not only from traditional web sources, but also from French cultural heritage documents, filling an important gap in modern datasets. Beyond French, which makes up the largest share of the data, we added documents to support several other European languages, including English, Spanish, German, and Italian. Apart from its value as a resource for French language and culture, an important feature of this dataset is that it prioritizes data rights by minimizing copyrighted material. In addition, building on the philosophy of past open projects, it is redistributed in the form used for training and its processing is described on Hugging Face and GitHub. The Lucie-7B foundation model is trained on equal amounts of data in French and English -- roughly 33% each -- in an effort to better represent cultural aspects of French-speaking communities. We also describe two instruction fine-tuned models, Lucie-7B-Instruct-v1.1 and Lucie-7B-Instruct-human-data, which we release as demonstrations of Lucie-7B in use. These models achieve promising results compared to state-of-the-art models, demonstrating that an open approach prioritizing data rights can still deliver strong performance. We see these models as an initial step toward developing more performant, aligned models in the near future. Model weights for Lucie-7B and the Lucie instruct models, along with intermediate checkpoints for the former, are published on Hugging Face, while model training and data preparation code is available on GitHub. This makes Lucie-7B one of the first OSI compliant language models according to the new OSI definition.
Lillama: Large Language Models Compression via Low-Rank Feature Distillation
Dec 28, 2024



Current LLM structured pruning methods typically involve two steps: (1) compression with calibration data and (2) costly continued pretraining on billions of tokens to recover lost performance. This second step is necessary as the first significantly impacts model accuracy. Prior research suggests pretrained Transformer weights aren't inherently low-rank, unlike their activations, which may explain this drop. Based on this observation, we propose Lillama, a compression method that locally distills activations with low-rank weights. Using SVD for initialization and a joint loss combining teacher and student activations, we accelerate convergence and reduce memory use with local gradient updates. Lillama compresses Mixtral-8x7B within minutes on a single A100 GPU, removing 10 billion parameters while retaining over 95% of its original performance. Phi-2 3B can be compressed by 40% with just 13 million calibration tokens, resulting in a small model that competes with recent models of similar size. The method generalizes well to non-transformer architectures, compressing Mamba-3B by 20% while maintaining 99% performance.
Large Language Models Compression via Low-Rank Feature Distillation
Dec 21, 2024Current LLM structured pruning methods involve two steps: (1) compressing with calibration data and (2) continued pretraining on billions of tokens to recover the lost performance. This costly second step is needed as the first step significantly impacts performance. Previous studies have found that pretrained Transformer weights aren't inherently low-rank, unlike their activations, which may explain this performance drop. Based on this observation, we introduce a one-shot compression method that locally distills low-rank weights. We accelerate convergence by initializing the low-rank weights with SVD and using a joint loss that combines teacher and student activations. We reduce memory requirements by applying local gradient updates only. Our approach can compress Mixtral-8x7B within minutes on a single A100 GPU, removing 10 billion parameters while maintaining over 95% of the original performance. Phi-2 3B can be compressed by 40% using only 13 million calibration tokens into a small model that competes with recent models of similar size. We show our method generalizes well to non-transformer architectures: Mamba-3B can be compressed by 20% while maintaining 99% of its performance.
Novel-WD: Exploring acquisition of Novel World Knowledge in LLMs Using Prefix-Tuning
Aug 30, 2024Teaching new information to pre-trained large language models (PLM) is a crucial but challenging task. Model adaptation techniques, such as fine-tuning and parameter-efficient training have been shown to store new facts at a slow rate; continual learning is an option but is costly and prone to catastrophic forgetting. This work studies and quantifies how PLM may learn and remember new world knowledge facts that do not occur in their pre-training corpus, which only contains world knowledge up to a certain date. To that purpose, we first propose Novel-WD, a new dataset consisting of sentences containing novel facts extracted from recent Wikidata updates, along with two evaluation tasks in the form of causal language modeling and multiple choice questions (MCQ). We make this dataset freely available to the community, and release a procedure to later build new versions of similar datasets with up-to-date information. We also explore the use of prefix-tuning for novel information learning, and analyze how much information can be stored within a given prefix. We show that a single fact can reliably be encoded within a single prefix, and that the prefix capacity increases with its length and with the base model size.
Improving Quotation Attribution with Fictional Character Embeddings
Jun 17, 2024



Humans naturally attribute utterances of direct speech to their speaker in literary works. When attributing quotes, we process contextual information but also access mental representations of characters that we build and revise throughout the narrative. Recent methods to automatically attribute such utterances have explored simulating human logic with deterministic rules or learning new implicit rules with neural networks when processing contextual information. However, these systems inherently lack \textit{character} representations, which often leads to errors on more challenging examples of attribution: anaphoric and implicit quotes. In this work, we propose to augment a popular quotation attribution system, BookNLP, with character embeddings that encode global information of characters. To build these embeddings, we create DramaCV, a corpus of English drama plays from the 15th to 20th century focused on Character Verification (CV), a task similar to Authorship Verification (AV), that aims at analyzing fictional characters. We train a model similar to the recently proposed AV model, Universal Authorship Representation (UAR), on this dataset, showing that it outperforms concurrent methods of characters embeddings on the CV task and generalizes better to literary novels. Then, through an extensive evaluation on 22 novels, we show that combining BookNLP's contextual information with our proposed global character embeddings improves the identification of speakers for anaphoric and implicit quotes, reaching state-of-the-art performance. Code and data will be made publicly available.
A Realistic Evaluation of LLMs for Quotation Attribution in Literary Texts: A Case Study of LLaMa3
Jun 17, 2024Large Language Models (LLMs) zero-shot and few-shot performance are subject to memorization and data contamination, complicating the assessment of their validity. In literary tasks, the performance of LLMs is often correlated to the degree of book memorization. In this work, we carry out a realistic evaluation of LLMs for quotation attribution in novels, taking the instruction fined-tuned version of Llama3 as an example. We design a task-specific memorization measure and use it to show that Llama3's ability to perform quotation attribution is positively correlated to the novel degree of memorization. However, Llama3 still performs impressively well on books it has not memorized nor seen. Data and code will be made publicly available.
Distinguishing Fictional Voices: a Study of Authorship Verification Models for Quotation Attribution
Jan 30, 2024

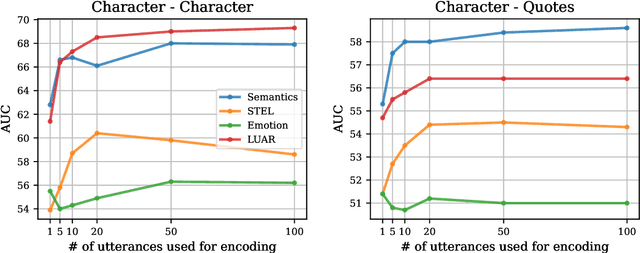
Recent approaches to automatically detect the speaker of an utterance of direct speech often disregard general information about characters in favor of local information found in the context, such as surrounding mentions of entities. In this work, we explore stylistic representations of characters built by encoding their quotes with off-the-shelf pretrained Authorship Verification models in a large corpus of English novels (the Project Dialogism Novel Corpus). Results suggest that the combination of stylistic and topical information captured in some of these models accurately distinguish characters among each other, but does not necessarily improve over semantic-only models when attributing quotes. However, these results vary across novels and more investigation of stylometric models particularly tailored for literary texts and the study of characters should be conducted.