 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinTO Audio and Textual Datasets to Train and Evaluate Automatic Speech Recognition in Tunisian Arabic Dialect
Apr 03, 2025Developing Automatic Speech Recognition (ASR) systems for Tunisian Arabic Dialect is challenging due to the dialect's linguistic complexity and the scarcity of annotated speech datasets. To address these challenges, we propose the LinTO audio and textual datasets -- comprehensive resources that capture phonological and lexical features of Tunisian Arabic Dialect. These datasets include a variety of texts from numerous sources and real-world audio samples featuring diverse speakers and code-switching between Tunisian Arabic Dialect and English or French. By providing high-quality audio paired with precise transcriptions, the LinTO audio and textual datasets aim to provide qualitative material to build and benchmark ASR systems for the Tunisian Arabic Dialect. Keywords -- Tunisian Arabic Dialect, Speech-to-Text, Low-Resource Languages, Audio Data Augmentation
The Lucie-7B LLM and the Lucie Training Dataset: Open resources for multilingual language generation
Mar 15, 2025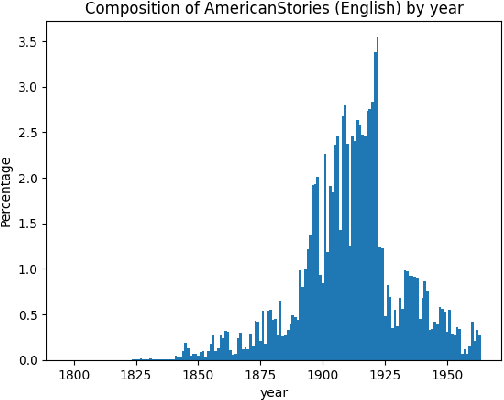

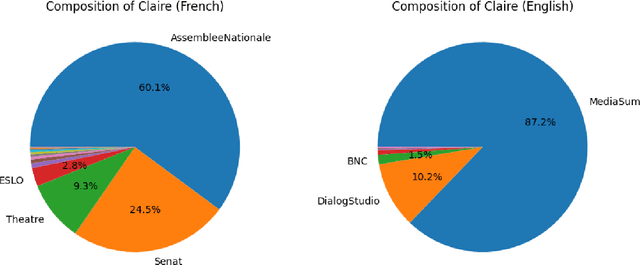
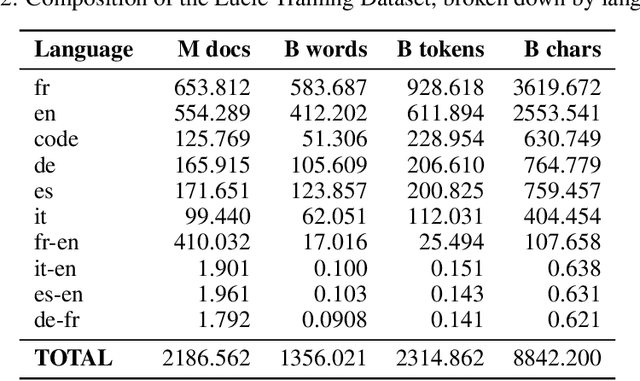
We present both the Lucie Training Dataset and the Lucie-7B foundation model. The Lucie Training Dataset is a multilingual collection of textual corpora centered around French and designed to offset anglo-centric biases found in many datasets for large language model pretraining. Its French data is pulled not only from traditional web sources, but also from French cultural heritage documents, filling an important gap in modern datasets. Beyond French, which makes up the largest share of the data, we added documents to support several other European languages, including English, Spanish, German, and Italian. Apart from its value as a resource for French language and culture, an important feature of this dataset is that it prioritizes data rights by minimizing copyrighted material. In addition, building on the philosophy of past open projects, it is redistributed in the form used for training and its processing is described on Hugging Face and GitHub. The Lucie-7B foundation model is trained on equal amounts of data in French and English -- roughly 33% each -- in an effort to better represent cultural aspects of French-speaking communities. We also describe two instruction fine-tuned models, Lucie-7B-Instruct-v1.1 and Lucie-7B-Instruct-human-data, which we release as demonstrations of Lucie-7B in use. These models achieve promising results compared to state-of-the-art models, demonstrating that an open approach prioritizing data rights can still deliver strong performance. We see these models as an initial step toward developing more performant, aligned models in the near future. Model weights for Lucie-7B and the Lucie instruct models, along with intermediate checkpoints for the former, are published on Hugging Face, while model training and data preparation code is available on GitHub. This makes Lucie-7B one of the first OSI compliant language models according to the new OSI definition.
The Claire French Dialogue Dataset
Nov 28, 2023We present the Claire French Dialogue Dataset (CFDD), a resource created by members of LINAGORA Labs in the context of the OpenLLM France initiative. CFDD is a corpus containing roughly 160 million words from transcripts and stage plays in French that we have assembled and publicly released in an effort to further the development of multilingual, open source language models. This paper describes the 24 individual corpora of which CFDD is composed and provides links and citations to their original sources. It also provides our proposed breakdown of the full CFDD dataset into eight categories of subcorpora and describes the process we followed to standardize the format of the final dataset. We conclude with a discussion of similar work and future directions.
Scan, Attend and Read: End-to-End Handwritten Paragraph Recognition with MDLSTM Attention
Aug 23, 2016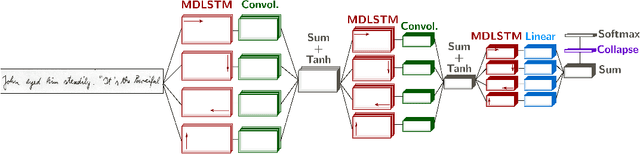
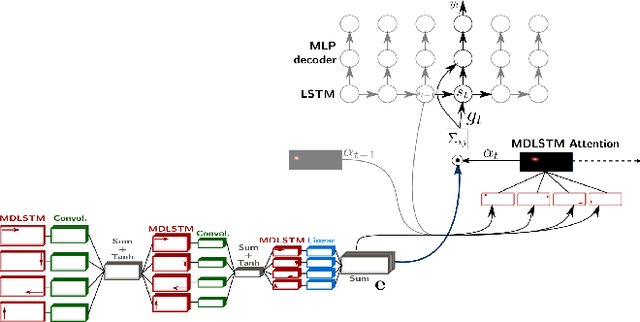

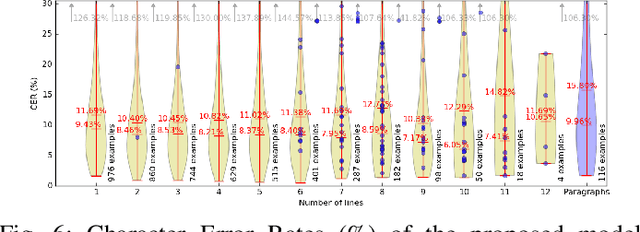
We present an attention-based model for end-to-end handwriting recognition. Our system does not require any segmentation of the input paragraph. The model is inspired by the differentiable attention models presented recently for speech recognition, image captioning or translation. The main difference is the covert and overt attention, implemented as a multi-dimensional LSTM network. Our principal contribution towards handwriting recognition lies in the automatic transcription without a prior segmentation into lines, which was crucial in previous approaches. To the best of our knowledge this is the first successful attempt of end-to-end multi-line handwriting recognition. We carried out experiments on the well-known IAM Database. The results are encouraging and bring hope to perform full paragraph transcription in the near future.
Dropout improves Recurrent Neural Networks for Handwriting Recognition
Mar 10, 2014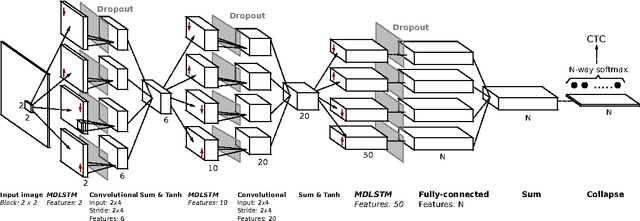
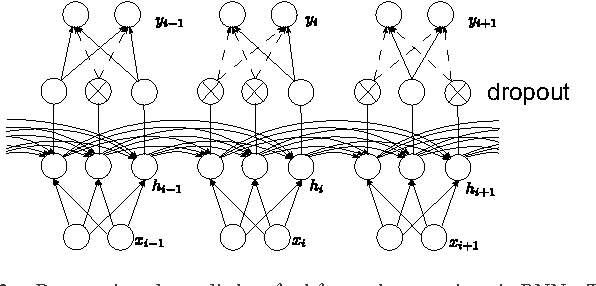
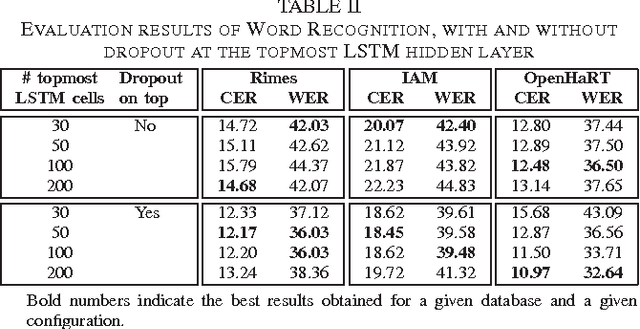
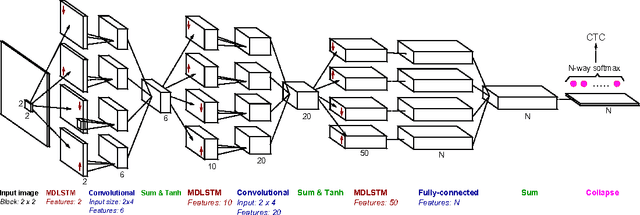
Recurrent neural networks (RNNs) with Long Short-Term memory cells currently hold the best known results in unconstrained handwriting recognition. We show that their performance can be greatly improved using dropout - a recently proposed regularization method for deep architectures. While previous works showed that dropout gave superior performance in the context of convolutional networks, it had never been applied to RNNs. In our approach, dropout is carefully used in the network so that it does not affect the recurrent connections, hence the power of RNNs in modeling sequence is preserved. Extensive experiments on a broad range of handwritten databases confirm the effectiveness of dropout on deep architectures even when the network mainly consists of recurrent and shared connections.
Curriculum Learning for Handwritten Text Line Recognition
Dec 05, 2013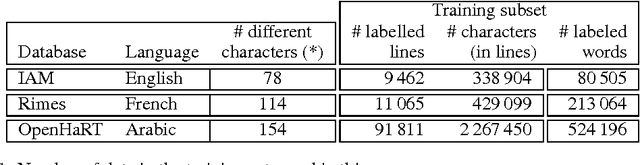
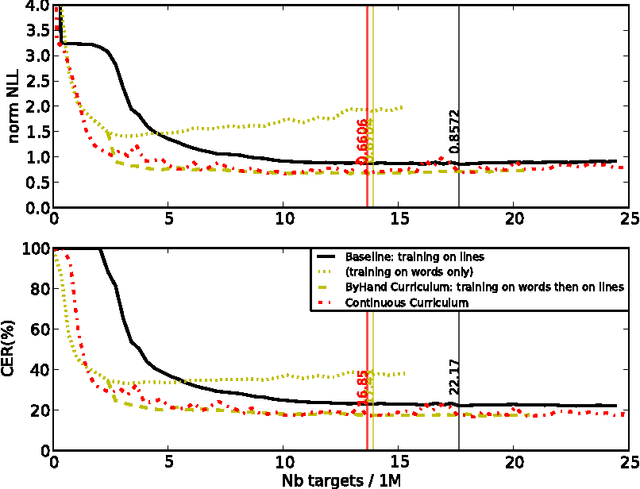
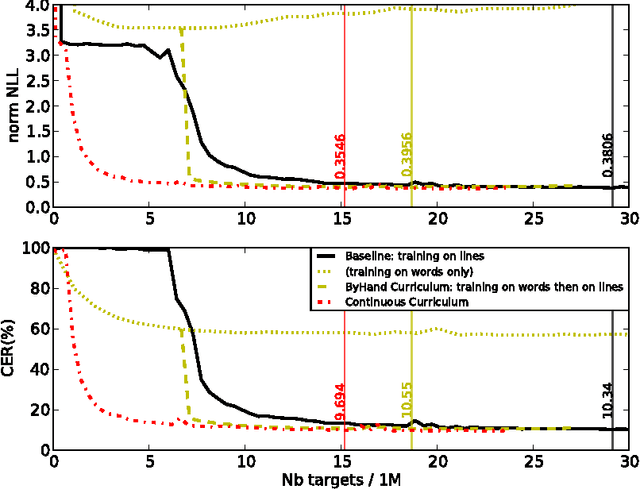
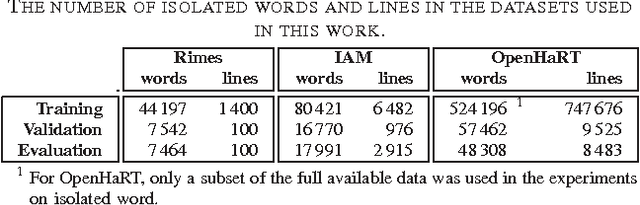
Recurrent Neural Networks (RNN) have recently achieved the best performance in off-line Handwriting Text Recognition. At the same time, learning RNN by gradient descent leads to slow convergence, and training times are particularly long when the training database consists of full lines of text. In this paper, we propose an easy way to accelerate stochastic gradient descent in this set-up, and in the general context of learning to recognize sequences. The principle is called Curriculum Learning, or shaping. The idea is to first learn to recognize short sequences before training on all available training sequences. Experiments on three different handwritten text databases (Rimes, IAM, OpenHaRT) show that a simple implementation of this strategy can significantly speed up the training of RNN for Text Recognition, and even significantly improve performance in some cases.
Classification of Sets using Restricted Boltzmann Machines
Mar 25, 2011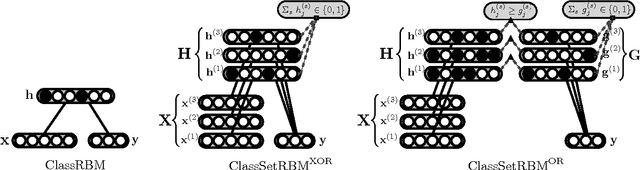
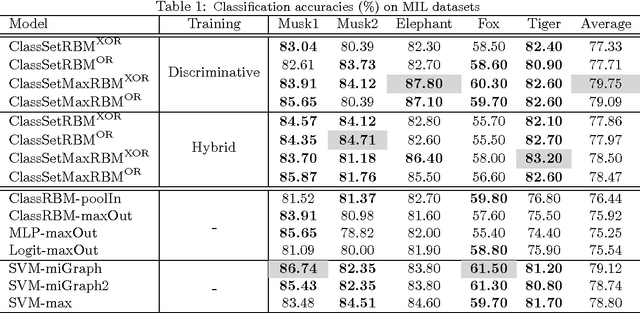
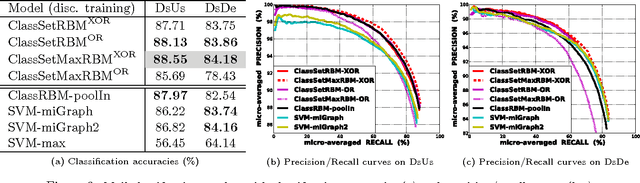
We consider the problem of classification when inputs correspond to sets of vectors. This setting occurs in many problems such as the classification of pieces of mail containing several pages, of web sites with several sections or of images that have been pre-segmented into smaller regions. We propose generalizations of the restricted Boltzmann machine (RBM) that are appropriate in this context and explore how to incorporate different assumptions about the relationship between the input sets and the target class within the RBM. In experiments on standard multiple-instance learning datasets, we demonstrate the competitiveness of approaches based on RBMs and apply the proposed variants to the problem of incoming mail classification.