 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Lucie-7B LLM and the Lucie Training Dataset: Open resources for multilingual language generation
Mar 15, 2025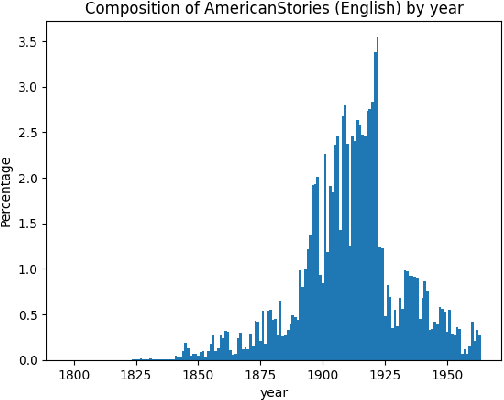

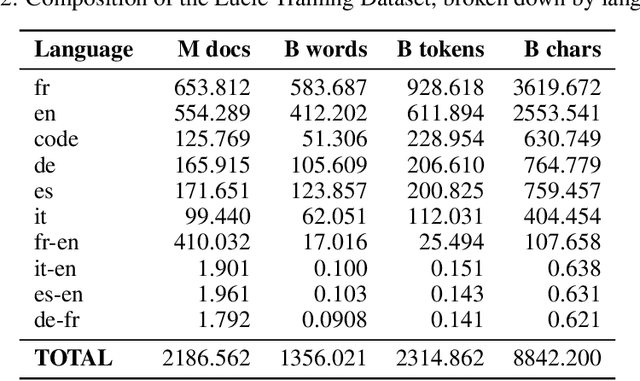
We present both the Lucie Training Dataset and the Lucie-7B foundation model. The Lucie Training Dataset is a multilingual collection of textual corpora centered around French and designed to offset anglo-centric biases found in many datasets for large language model pretraining. Its French data is pulled not only from traditional web sources, but also from French cultural heritage documents, filling an important gap in modern datasets. Beyond French, which makes up the largest share of the data, we added documents to support several other European languages, including English, Spanish, German, and Italian. Apart from its value as a resource for French language and culture, an important feature of this dataset is that it prioritizes data rights by minimizing copyrighted material. In addition, building on the philosophy of past open projects, it is redistributed in the form used for training and its processing is described on Hugging Face and GitHub. The Lucie-7B foundation model is trained on equal amounts of data in French and English -- roughly 33% each -- in an effort to better represent cultural aspects of French-speaking communities. We also describe two instruction fine-tuned models, Lucie-7B-Instruct-v1.1 and Lucie-7B-Instruct-human-data, which we release as demonstrations of Lucie-7B in use. These models achieve promising results compared to state-of-the-art models, demonstrating that an open approach prioritizing data rights can still deliver strong performance. We see these models as an initial step toward developing more performant, aligned models in the near future. Model weights for Lucie-7B and the Lucie instruct models, along with intermediate checkpoints for the former, are published on Hugging Face, while model training and data preparation code is available on GitHub. This makes Lucie-7B one of the first OSI compliant language models according to the new OSI definition.
LLaMIPa: An Incremental Discourse Parser
Jun 26, 2024This paper provides the first discourse parsing experiments with a large language model (LLM) finetuned on corpora annotated in the style of SDRT (Asher, 1993; Asher and Lascarides, 2003). The result is a discourse parser, LLaMIPa (LLaMA Incremental Parser), which is able to more fully exploit discourse context, leading to substantial performance gains over approaches that use encoder-only models to provide local, context-sensitive representations of discourse units. Furthermore, it is able to process discourse data incrementally, which is essential for the eventual use of discourse information in downstream tasks.
Leveraging Discourse Structure for Extractive Meeting Summarization
May 21, 2024We introduce an extractive summarization system for meetings that leverages discourse structure to better identify salient information from complex multi-party discussions. Using discourse graphs to represent semantic relations between the contents of utterances in a meeting, we train a GNN-based node classification model to select the most important utterances, which are then combined to create an extractive summary. Experimental results on AMI and ICSI demonstrate that our approach surpasses existing text-based and graph-based extractive summarization systems, as measured by both classification and summarization metrics. Additionally, we conduct ablation studies on discourse structure and relation type to provide insights for future NLP applications leveraging discourse analysis theory.
FREDSum: A Dialogue Summarization Corpus for French Political Debates
Dec 08, 2023Recent advances in deep learning, and especially the invention of encoder-decoder architectures, has significantly improved the performance of abstractive summarization systems. The majority of research has focused on written documents, however, neglecting the problem of multi-party dialogue summarization. In this paper, we present a dataset of French political debates for the purpose of enhancing resources for multi-lingual dialogue summarization. Our dataset consists of manually transcribed and annotated political debates, covering a range of topics and perspectives. We highlight the importance of high quality transcription and annotations for training accurate and effective dialogue summarization models, and emphasize the need for multilingual resources to support dialogue summarization in non-English languages. We also provide baseline experiments using state-of-the-art methods, and encourage further research in this area to advance the field of dialogue summarization. Our dataset will be made publicly available for use by the research community.
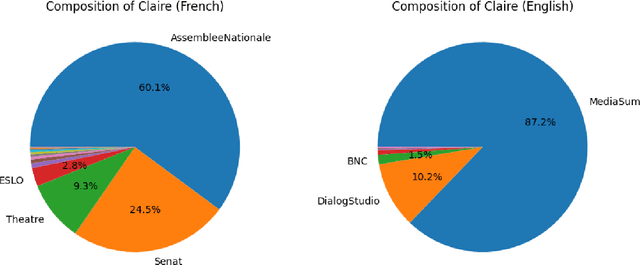
The Claire French Dialogue Dataset
Nov 28, 2023We present the Claire French Dialogue Dataset (CFDD), a resource created by members of LINAGORA Labs in the context of the OpenLLM France initiative. CFDD is a corpus containing roughly 160 million words from transcripts and stage plays in French that we have assembled and publicly released in an effort to further the development of multilingual, open source language models. This paper describes the 24 individual corpora of which CFDD is composed and provides links and citations to their original sources. It also provides our proposed breakdown of the full CFDD dataset into eight categories of subcorpora and describes the process we followed to standardize the format of the final dataset. We conclude with a discussion of similar work and future directions.
Limits for Learning with Language Models
Jun 21, 2023With the advent of large language models (LLMs), the trend in NLP has been to train LLMs on vast amounts of data to solve diverse language understanding and generation tasks. The list of LLM successes is long and varied. Nevertheless, several recent papers provide empirical evidence that LLMs fail to capture important aspects of linguistic meaning. Focusing on universal quantification, we provide a theoretical foundation for these empirical findings by proving that LLMs cannot learn certain fundamental semantic properties including semantic entailment and consistency as they are defined in formal semantics. More generally, we show that LLMs are unable to learn concepts beyond the first level of the Borel Hierarchy, which imposes severe limits on the ability of LMs, both large and small, to capture many aspects of linguistic meaning. This means that LLMs will continue to operate without formal guarantees on tasks that require entailments and deep linguistic understanding.
Abstractive Meeting Summarization: A Survey
Aug 08, 2022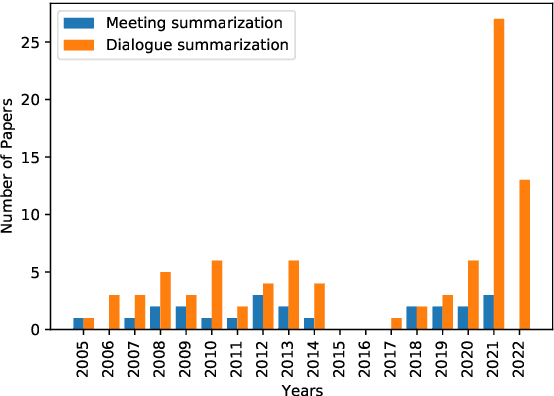
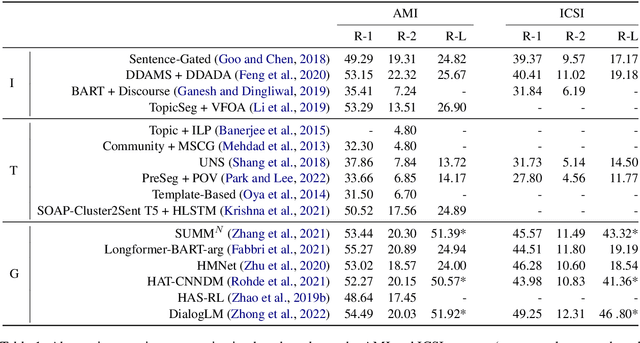
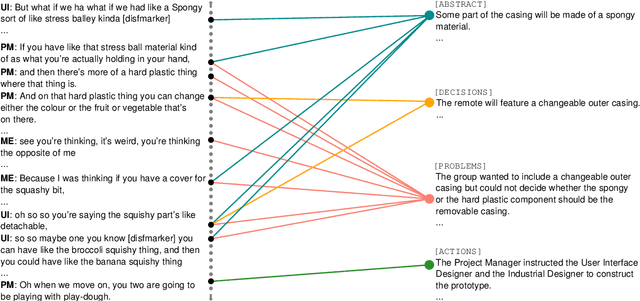
Recent advances in deep learning, and especially the invention of encoder-decoder architectures, has significantly improved the performance of abstractive summarization systems. While the majority of research has focused on written documents, we have observed an increasing interest in the summarization of dialogues and multi-party conversation over the past few years. A system that could reliably transform the audio or transcript of a human conversation into an abridged version that homes in on the most important points of the discussion would be valuable in a wide variety of real-world contexts, from business meetings to medical consultations to customer service calls. This paper focuses on abstractive summarization for multi-party meetings, providing a survey of the challenges, datasets and systems relevant to this task and a discussion of promising directions for future study.
Interpretive Blindness
Oct 19, 2021We model here an epistemic bias we call \textit{interpretive blindness} (IB). IB is a special problem for learning from testimony, in which one acquires information only from text or conversation. We show that IB follows from a co-dependence between background beliefs and interpretation in a Bayesian setting and the nature of contemporary testimony. We argue that a particular characteristic contemporary testimony, \textit{argumentative completeness}, can preclude learning in hierarchical Bayesian settings, even in the presence of constraints that are designed to promote good epistemic practices.