 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKisMATH: Do LLMs Have Knowledge of Implicit Structures in Mathematical Reasoning?
Jul 15, 2025



Chain-of-thought traces have been shown to improve performance of large language models in a plethora of reasoning tasks, yet there is no consensus on the mechanism through which this performance boost is achieved. To shed more light on this, we introduce Causal CoT Graphs (CCGs), which are directed acyclic graphs automatically extracted from reasoning traces that model fine-grained causal dependencies in the language model output. A collection of $1671$ mathematical reasoning problems from MATH500, GSM8K and AIME, and their associated CCGs are compiled into our dataset -- \textbf{KisMATH}. Our detailed empirical analysis with 15 open-weight LLMs shows that (i) reasoning nodes in the CCG are mediators for the final answer, a condition necessary for reasoning; and (ii) LLMs emphasise reasoning paths given by the CCG, indicating that models internally realise structures akin to our graphs. KisMATH enables controlled, graph-aligned interventions and opens up avenues for further investigation into the role of chain-of-thought in LLM reasoning.
sudoLLM : On Multi-role Alignment of Language Models
May 20, 2025



User authorization-based access privileges are a key feature in many safety-critical systems, but have thus far been absent from the large language model (LLM) realm. In this work, drawing inspiration from such access control systems, we introduce sudoLLM, a novel framework that results in multi-role aligned LLMs, i.e., LLMs that account for, and behave in accordance with, user access rights. sudoLLM injects subtle user-based biases into queries and trains an LLM to utilize this bias signal in order to produce sensitive information if and only if the user is authorized. We present empirical results demonstrating that this approach shows substantially improved alignment, generalization, and resistance to prompt-based jailbreaking attacks. The persistent tension between the language modeling objective and safety alignment, which is often exploited to jailbreak LLMs, is somewhat resolved with the aid of the injected bias signal. Our framework is meant as an additional security layer, and complements existing guardrail mechanisms for enhanced end-to-end safety with LLMs.
DIMSUM: Discourse in Mathematical Reasoning as a Supervision Module
Mar 07, 2025


We look at reasoning on GSM8k, a dataset of short texts presenting primary school, math problems. We find, with Mirzadeh et al. (2024), that current LLM progress on the data set may not be explained by better reasoning but by exposure to a broader pretraining data distribution. We then introduce a novel information source for helping models with less data or inferior training reason better: discourse structure. We show that discourse structure improves performance for models like Llama2 13b by up to 160%. Even for models that have most likely memorized the data set, adding discourse structural information to the model still improves predictions and dramatically improves large model performance on out of distribution examples.
Learning Semantic Structure through First-Order-Logic Translation
Oct 04, 2024



In this paper, we study whether transformer-based language models can extract predicate argument structure from simple sentences. We firstly show that language models sometimes confuse which predicates apply to which objects. To mitigate this, we explore two tasks: question answering (Q/A), and first order logic (FOL) translation, and two regimes, prompting and finetuning. In FOL translation, we finetune several large language models on synthetic datasets designed to gauge their generalization abilities. For Q/A, we finetune encoder models like BERT and RoBERTa and use prompting for LLMs. The results show that FOL translation for LLMs is better suited to learn predicate argument structure.
LLaMIPa: An Incremental Discourse Parser
Jun 26, 2024This paper provides the first discourse parsing experiments with a large language model (LLM) finetuned on corpora annotated in the style of SDRT (Asher, 1993; Asher and Lascarides, 2003). The result is a discourse parser, LLaMIPa (LLaMA Incremental Parser), which is able to more fully exploit discourse context, leading to substantial performance gains over approaches that use encoder-only models to provide local, context-sensitive representations of discourse units. Furthermore, it is able to process discourse data incrementally, which is essential for the eventual use of discourse information in downstream tasks.
NeBuLa: A discourse aware Minecraft Builder
Jun 26, 2024
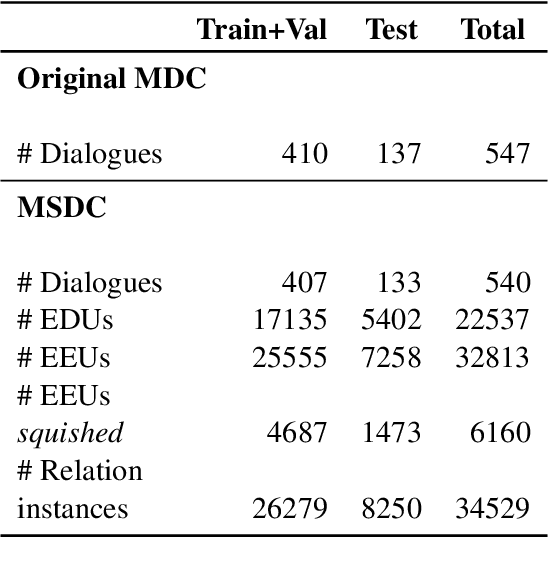


When engaging in collaborative tasks, humans efficiently exploit the semantic structure of a conversation to optimize verbal and nonverbal interactions. But in recent "language to code" or "language to action" models, this information is lacking. We show how incorporating the prior discourse and nonlinguistic context of a conversation situated in a nonlinguistic environment can improve the "language to action" component of such interactions. We fine tune an LLM to predict actions based on prior context; our model, NeBuLa, doubles the net-action F1 score over the baseline on this task of Jayannavar et al.(2020). We also investigate our model's ability to construct shapes and understand location descriptions using a synthetic dataset.
Limits for Learning with Language Models
Jun 21, 2023With the advent of large language models (LLMs), the trend in NLP has been to train LLMs on vast amounts of data to solve diverse language understanding and generation tasks. The list of LLM successes is long and varied. Nevertheless, several recent papers provide empirical evidence that LLMs fail to capture important aspects of linguistic meaning. Focusing on universal quantification, we provide a theoretical foundation for these empirical findings by proving that LLMs cannot learn certain fundamental semantic properties including semantic entailment and consistency as they are defined in formal semantics. More generally, we show that LLMs are unable to learn concepts beyond the first level of the Borel Hierarchy, which imposes severe limits on the ability of LMs, both large and small, to capture many aspects of linguistic meaning. This means that LLMs will continue to operate without formal guarantees on tasks that require entailments and deep linguistic understanding.
Analyzing Semantic Faithfulness of Language Models via Input Intervention on Conversational Question Answering
Dec 21, 2022Transformer-based language models have been shown to be highly effective for several NLP tasks. In this paper, we consider three transformer models, BERT, RoBERTa, and XLNet, in both small and large version, and investigate how faithful their representations are with respect to the semantic content of texts. We formalize a notion of semantic faithfulness, in which the semantic content of a text should causally figure in a model's inferences in question answering. We then test this notion by observing a model's behavior on answering questions about a story after performing two novel semantic interventions -- deletion intervention and negation intervention. While transformer models achieve high performance on standard question answering tasks, we show that they fail to be semantically faithful once we perform these interventions for a significant number of cases (~50% for deletion intervention, and ~20% drop in accuracy for negation intervention). We then propose an intervention-based training regime that can mitigate the undesirable effects for deletion intervention by a significant margin (from ~50% to ~6%). We analyze the inner-workings of the models to better understand the effectiveness of intervention-based training for deletion intervention. But we show that this training does not attenuate other aspects of semantic unfaithfulness such as the models' inability to deal with negation intervention or to capture the predicate-argument structure of texts. We also test InstructGPT, via prompting, for its ability to handle the two interventions and to capture predicate-argument structure. While InstructGPT models do achieve very high performance on predicate-argument structure task, they fail to respond adequately to our deletion and negation interventions.
Pick-Object-Attack: Type-Specific Adversarial Attack for Object Detection
Jun 05, 2020
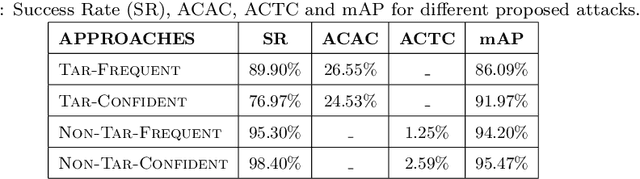
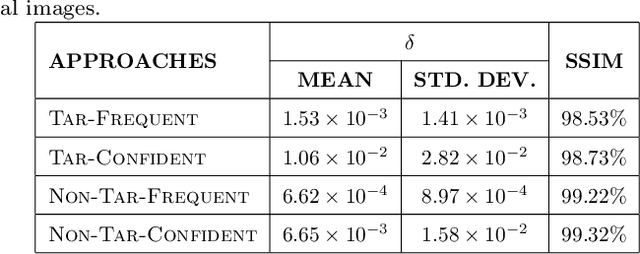
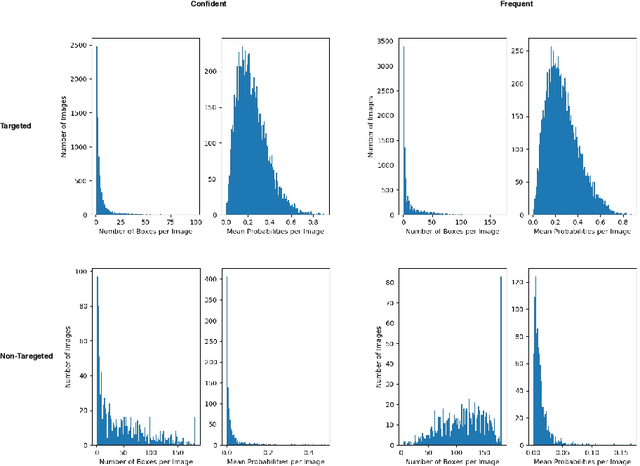
Many recent studies have shown that deep neural models are vulnerable to adversarial samples: images with imperceptible perturbations, for example, can fool image classifiers. In this paper, we generate adversarial examples for object detection, which entails detecting bounding boxes around multiple objects present in the image and classifying them at the same time, making it a harder task than against image classification. We specifically aim to attack the widely used Faster R-CNN by changing the predicted label for a particular object in an image: where prior work has targeted one specific object (a stop sign), we generalise to arbitrary objects, with the key challenge being the need to change the labels of all bounding boxes for all instances of that object type. To do so, we propose a novel method, named Pick-Object-Attack. Pick-Object-Attack successfully adds perturbations only to bounding boxes for the targeted object, preserving the labels of other detected objects in the image. In terms of perceptibility, the perturbations induced by the method are very small. Furthermore, for the first time, we examine the effect of adversarial attacks on object detection in terms of a downstream task, image captioning; we show that where a method that can modify all object types leads to very obvious changes in captions, the changes from our constrained attack are much less apparent.
Invariance-based Adversarial Attack on Neural Machine Translation Systems
Aug 03, 2019
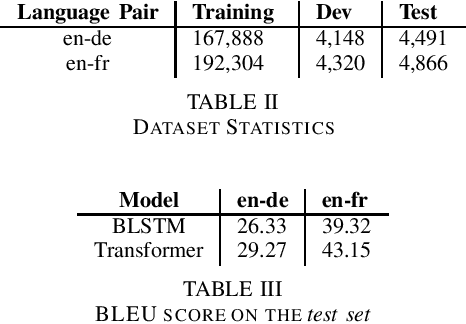
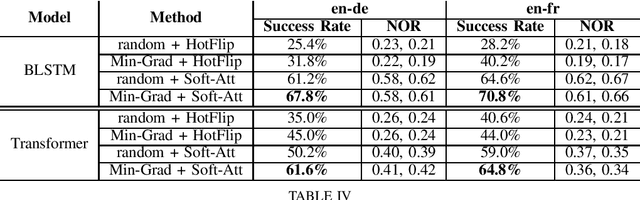

Recently, NLP models have been shown to be susceptible to adversarial attacks. In this paper, we explore adversarial attacks on neural machine translation (NMT) systems. Given a sentence in the source language, the goal of the proposed attack is to change multiple words while ensuring that the predicted translation remains unchanged. In order to choose the word from the source vocabulary, we propose a soft-attention based technique. The experiments are conducted on two language pairs: English-German (en-de) and English-French (en-fr) and two state-of-the-art NMT systems: BLSTM-based encoder-decoder with attention and Transformer. The proposed soft-attention based technique outperforms existing methods like HotFlip by a significant margin for all the conducted experiments The results demonstrate that state-of-the-art NMT systems are unable to capture the semantics of the source language.