 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSagaQA: A Multi-hop Reasoning Benchmark for Long-form Narrative Understanding in TV Series
Jun 02, 2026We introduce SagaQA, a long-form video benchmark for multi-hop reasoning over full-length TV series. Existing video reasoning benchmarks often emphasize local understanding of adjacent frames or clips. SagaQA addresses this gap by requiring high-level comprehension of extended multimodal narratives in entire TV shows. A distinguishing feature of SagaQA is the granularity of its reasoning steps. Our dataset necessitates long-range reasoning hops to connect information across completely different episodes. This requires models to reason over entire events and actions, demanding a deep understanding of the show's narration and progression at a multimodal level. Motivated by recent progress in agentic methods, we further study how different planning strategies handle such complex reasoning. We categorize these approaches into three classes-Parallel, Sequential, and Hybrid planners-and evaluate their ability to generate coherent and complete reasoning plans. Our results on SagaQA suggest that hybrid planners consistently produce higher-quality plans and exhibit stronger capabilities for complex, high-level narrative understanding in TV shows.
TAPIOCA: Why Task- Aware Pruning Improves OOD model Capability
May 14, 2026Recent work has promoted task-aware layer pruning as a way to improve model performance on particular tasks, as shown by TALE. In this paper, we investigate when such improvements occur and why. We show first that, across controlled polynomial regression tasks and large language models, such pruning yields no benefit on in-distribution (ID) data but consistently improves out-of-distribution (OOD) accuracy. We further show empirically that OOD inputs induce layerwise norm and pairwise-distance profiles that deviate from the corresponding ID profiles. This leads to a geometric explanation of task-aware pruning: each task induces a task-adapted geometry, characterized empirically by the representation profiles observed on ID inputs. OOD inputs can introduce a distorted version of the task-adapted geometry. Task-aware pruning identifies layers that create or amplify this distortion; by removing them, it shifts OOD representational norms and pairwise distances toward those observed on the adapted distribution. This realigns OOD inputs with the model's task-adapted geometry and improves performance. We provide causal evidence through controlled distribution shifts and residual-scaling interventions, and demonstrate consistent behavior across model scales.
Exploring Plan Space through Conversation: An Agentic Framework for LLM-Mediated Explanations in Planning
Mar 02, 2026When automating plan generation for a real-world sequential decision problem, the goal is often not to replace the human planner, but to facilitate an iterative reasoning and elicitation process, where the human's role is to guide the AI planner according to their preferences and expertise. In this context, explanations that respond to users' questions are crucial to improve their understanding of potential solutions and increase their trust in the system. To enable natural interaction with such a system, we present a multi-agent Large Language Model (LLM) architecture that is agnostic to the explanation framework and enables user- and context-dependent interactive explanations. We also describe an instantiation of this framework for goal-conflict explanations, which we use to conduct a user study comparing the LLM-powered interaction with a baseline template-based explanation interface.
Minimal Clips, Maximum Salience: Long Video Summarization via Key Moment Extraction
Dec 12, 2025Vision-Language Models (VLMs) are able to process increasingly longer videos. Yet, important visual information is easily lost throughout the entire context and missed by VLMs. Also, it is important to design tools that enable cost-effective analysis of lengthy video content. In this paper, we propose a clip selection method that targets key video moments to be included in a multimodal summary. We divide the video into short clips and generate compact visual descriptions of each using a lightweight video captioning model. These are then passed to a large language model (LLM), which selects the K clips containing the most relevant visual information for a multimodal summary. We evaluate our approach on reference clips for the task, automatically derived from full human-annotated screenplays and summaries in the MovieSum dataset. We further show that these reference clips (less than 6% of the movie) are sufficient to build a complete multimodal summary of the movies in MovieSum. Using our clip selection method, we achieve a summarization performance close to that of these reference clips while capturing substantially more relevant video information than random clip selection. Importantly, we maintain low computational cost by relying on a lightweight captioning model.
TELL-TALE: Task Efficient LLMs with Task Aware Layer Elimination
Oct 26, 2025In this paper we introduce Tale, Task-Aware Layer Elimination, an inference-time algorithm that prunes entire transformer layers in an LLM by directly optimizing task-specific validation performance. We evaluate TALE on 9 tasks and 5 models, including LLaMA 3.1 8B, Qwen 2.5 7B, Qwen 2.5 0.5B, Mistral 7B, and Lucie 7B, under both zero-shot and few-shot settings. Unlike prior approaches, TALE requires no retraining and consistently improves accuracy while reducing computational cost across all benchmarks. Furthermore, applying TALE during finetuning leads to additional performance gains. Finally, TALE provides flexible user control over trade-offs between accuracy and efficiency. Mutual information analysis shows that certain layers act as bottlenecks, degrading task-relevant representations. Tale's selective layer removal remedies this problem, producing smaller, faster, and more accurate models that are also faster to fine-tune while offering new insights into transformer interpretability.
Improving in-context learning with a better scoring function
Aug 20, 2025Large language models (LLMs) exhibit a remarkable capacity to learn by analogy, known as in-context learning (ICL). However, recent studies have revealed limitations in this ability. In this paper, we examine these limitations on tasks involving first-order quantifiers such as {\em all} and {\em some}, as well as on ICL with linear functions. We identify Softmax, the scoring function in attention mechanism, as a contributing factor to these constraints. To address this, we propose \textbf{scaled signed averaging (SSA)}, a novel alternative to Softmax. Empirical results show that SSA dramatically improves performance on our target tasks. Furthermore, we evaluate both encoder-only and decoder-only transformers models with SSA, demonstrating that they match or exceed their Softmax-based counterparts across a variety of linguistic probing tasks.
KisMATH: Do LLMs Have Knowledge of Implicit Structures in Mathematical Reasoning?
Jul 15, 2025



Chain-of-thought traces have been shown to improve performance of large language models in a plethora of reasoning tasks, yet there is no consensus on the mechanism through which this performance boost is achieved. To shed more light on this, we introduce Causal CoT Graphs (CCGs), which are directed acyclic graphs automatically extracted from reasoning traces that model fine-grained causal dependencies in the language model output. A collection of $1671$ mathematical reasoning problems from MATH500, GSM8K and AIME, and their associated CCGs are compiled into our dataset -- \textbf{KisMATH}. Our detailed empirical analysis with 15 open-weight LLMs shows that (i) reasoning nodes in the CCG are mediators for the final answer, a condition necessary for reasoning; and (ii) LLMs emphasise reasoning paths given by the CCG, indicating that models internally realise structures akin to our graphs. KisMATH enables controlled, graph-aligned interventions and opens up avenues for further investigation into the role of chain-of-thought in LLM reasoning.
Integrating Video and Text: A Balanced Approach to Multimodal Summary Generation and Evaluation
May 10, 2025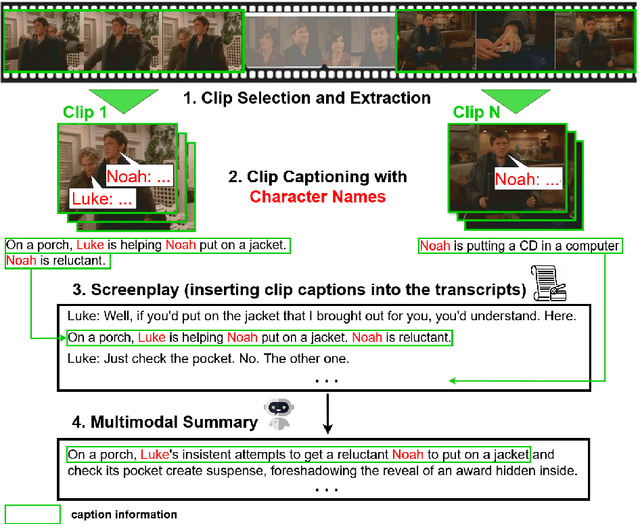
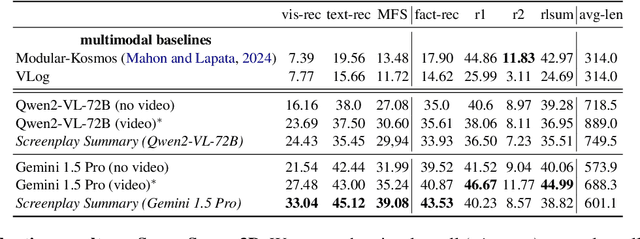
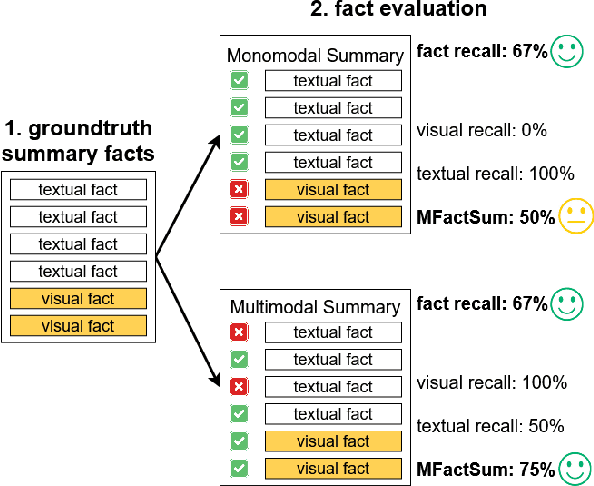

Vision-Language Models (VLMs) often struggle to balance visual and textual information when summarizing complex multimodal inputs, such as entire TV show episodes. In this paper, we propose a zero-shot video-to-text summarization approach that builds its own screenplay representation of an episode, effectively integrating key video moments, dialogue, and character information into a unified document. Unlike previous approaches, we simultaneously generate screenplays and name the characters in zero-shot, using only the audio, video, and transcripts as input. Additionally, we highlight that existing summarization metrics can fail to assess the multimodal content in summaries. To address this, we introduce MFactSum, a multimodal metric that evaluates summaries with respect to both vision and text modalities. Using MFactSum, we evaluate our screenplay summaries on the SummScreen3D dataset, demonstrating superiority against state-of-the-art VLMs such as Gemini 1.5 by generating summaries containing 20% more relevant visual information while requiring 75% less of the video as input.
DIMSUM: Discourse in Mathematical Reasoning as a Supervision Module
Mar 07, 2025


We look at reasoning on GSM8k, a dataset of short texts presenting primary school, math problems. We find, with Mirzadeh et al. (2024), that current LLM progress on the data set may not be explained by better reasoning but by exposure to a broader pretraining data distribution. We then introduce a novel information source for helping models with less data or inferior training reason better: discourse structure. We show that discourse structure improves performance for models like Llama2 13b by up to 160%. Even for models that have most likely memorized the data set, adding discourse structural information to the model still improves predictions and dramatically improves large model performance on out of distribution examples.
Two in context learning tasks with complex functions
Feb 05, 2025We examine two in context learning (ICL) tasks with mathematical functions in several train and test settings for transformer models. Our study generalizes work on linear functions by showing that small transformers, even models with attention layers only, can approximate arbitrary polynomial functions and hence continuous functions under certain conditions. Our models also can approximate previously unseen classes of polynomial functions, as well as the zeros of complex functions. Our models perform far better on this task than LLMs like GPT4 and involve complex reasoning when provided with suitable training data and methods. Our models also have important limitations; they fail to generalize outside of training distributions and so don't learn class forms of functions. We explain why this is so.