 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parallel Approach to Counting Exact Covers Based on Decomposability Property
Apr 16, 2026The exact cover problem is a classical NP-hard problem with broad applications in the area of AI. Algorithm DXZ is a method to count exact covers representing by zero-suppressed binary decision diagrams (ZBDDs). In this paper, we propose a zero-suppressed variant of decision decomposable negation normal form (in short, decision-ZDNNF), which is strictly more succinct than ZBDDs. We then design a novel parallel algorithm, namely DXD, which constructs a decision-ZDNNF representing the set of all exact covers. Furthermore, we improve DXD by dynamically updating connected components. The experimental results demonstrate that the improved DXD algorithm outperforms all of state-of-the-art methods.
Rigorous Explanations for Tree Ensembles
Mar 31, 2026Tree ensembles (TEs) find a multitude of practical applications. They represent one of the most general and accurate classes of machine learning methods. While they are typically quite concise in representation, their operation remains inscrutable to human decision makers. One solution to build trust in the operation of TEs is to automatically identify explanations for the predictions made. Evidently, we can only achieve trust using explanations, if those explanations are rigorous, that is truly reflect properties of the underlying predictor they explain This paper investigates the computation of rigorously-defined, logically-sound explanations for the concrete case of two well-known examples of tree ensembles, namely random forests and boosted trees.
The Explanation Game -- Rekindled (Extended Version)
Jan 20, 2025
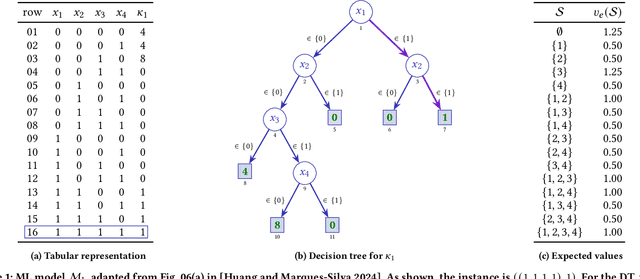

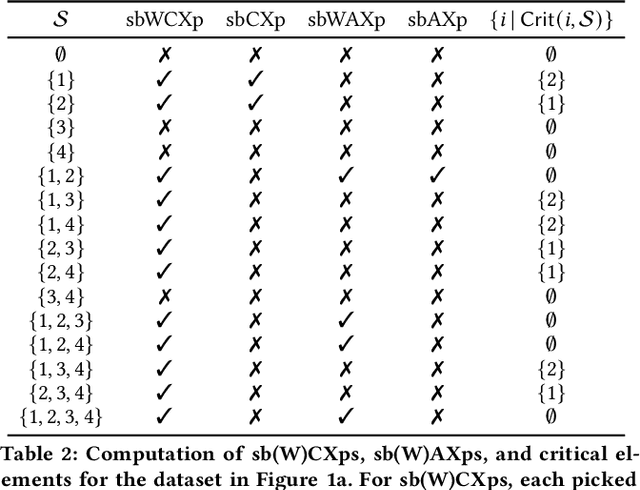
Recent work demonstrated the existence of critical flaws in the current use of Shapley values in explainable AI (XAI), i.e. the so-called SHAP scores. These flaws are significant in that the scores provided to a human decision-maker can be misleading. Although these negative results might appear to indicate that Shapley values ought not be used in XAI, this paper argues otherwise. Concretely, this paper proposes a novel definition of SHAP scores that overcomes existing flaws. Furthermore, the paper outlines a practically efficient solution for the rigorous estimation of the novel SHAP scores. Preliminary experimental results confirm our claims, and further underscore the flaws of the current SHAP scores.
SHAP scores fail pervasively even when Lipschitz succeeds
Dec 18, 2024The ubiquitous use of Shapley values in eXplainable AI (XAI) has been triggered by the tool SHAP, and as a result are commonly referred to as SHAP scores. Recent work devised examples of machine learning (ML) classifiers for which the computed SHAP scores are thoroughly unsatisfactory, by allowing human decision-makers to be misled. Nevertheless, such examples could be perceived as somewhat artificial, since the selected classes must be interpreted as numeric. Furthermore, it was unclear how general were the issues identified with SHAP scores. This paper answers these criticisms. First, the paper shows that for Boolean classifiers there are arbitrarily many examples for which the SHAP scores must be deemed unsatisfactory. Second, the paper shows that the issues with SHAP scores are also observed in the case of regression models. In addition, the paper studies the class of regression models that respect Lipschitz continuity, a measure of a function's rate of change that finds important recent uses in ML, including model robustness. Concretely, the paper shows that the issues with SHAP scores occur even for regression models that respect Lipschitz continuity. Finally, the paper shows that the same issues are guaranteed to exist for arbitrarily differentiable regression models.
From SHAP Scores to Feature Importance Scores
May 20, 2024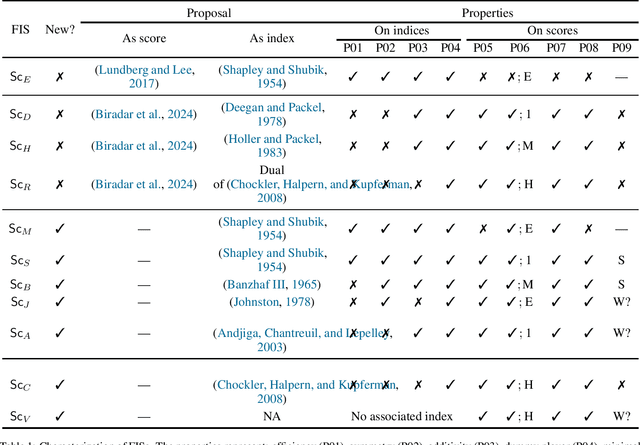
A central goal of eXplainable Artificial Intelligence (XAI) is to assign relative importance to the features of a Machine Learning (ML) model given some prediction. The importance of this task of explainability by feature attribution is illustrated by the ubiquitous recent use of tools such as SHAP and LIME. Unfortunately, the exact computation of feature attributions, using the game-theoretical foundation underlying SHAP and LIME, can yield manifestly unsatisfactory results, that tantamount to reporting misleading relative feature importance. Recent work targeted rigorous feature attribution, by studying axiomatic aggregations of features based on logic-based definitions of explanations by feature selection. This paper shows that there is an essential relationship between feature attribution and a priori voting power, and that those recently proposed axiomatic aggregations represent a few instantiations of the range of power indices studied in the past. Furthermore, it remains unclear how some of the most widely used power indices might be exploited as feature importance scores (FISs), i.e. the use of power indices in XAI, and which of these indices would be the best suited for the purposes of XAI by feature attribution, namely in terms of not producing results that could be deemed as unsatisfactory. This paper proposes novel desirable properties that FISs should exhibit. In addition, the paper also proposes novel FISs exhibiting the proposed properties. Finally, the paper conducts a rigorous analysis of the best-known power indices in terms of the proposed properties.
Distance-Restricted Explanations: Theoretical Underpinnings & Efficient Implementation
May 14, 2024



The uses of machine learning (ML) have snowballed in recent years. In many cases, ML models are highly complex, and their operation is beyond the understanding of human decision-makers. Nevertheless, some uses of ML models involve high-stakes and safety-critical applications. Explainable artificial intelligence (XAI) aims to help human decision-makers in understanding the operation of such complex ML models, thus eliciting trust in their operation. Unfortunately, the majority of past XAI work is based on informal approaches, that offer no guarantees of rigor. Unsurprisingly, there exists comprehensive experimental and theoretical evidence confirming that informal methods of XAI can provide human-decision makers with erroneous information. Logic-based XAI represents a rigorous approach to explainability; it is model-based and offers the strongest guarantees of rigor of computed explanations. However, a well-known drawback of logic-based XAI is the complexity of logic reasoning, especially for highly complex ML models. Recent work proposed distance-restricted explanations, i.e. explanations that are rigorous provided the distance to a given input is small enough. Distance-restricted explainability is tightly related with adversarial robustness, and it has been shown to scale for moderately complex ML models, but the number of inputs still represents a key limiting factor. This paper investigates novel algorithms for scaling up the performance of logic-based explainers when computing and enumerating ML model explanations with a large number of inputs.
On Correcting SHAP Scores
Apr 30, 2024Recent work uncovered examples of classifiers for which SHAP scores yield misleading feature attributions. While such examples might be perceived as suggesting the inadequacy of Shapley values for explainability, this paper shows that the source of the identified shortcomings of SHAP scores resides elsewhere. Concretely, the paper makes the case that the failings of SHAP scores result from the characteristic functions used in earlier works. Furthermore, the paper identifies a number of properties that characteristic functions ought to respect, and proposes several novel characteristic functions, each exhibiting one or more of the desired properties. More importantly, some of the characteristic functions proposed in this paper are guaranteed not to exhibit any of the shortcomings uncovered by earlier work. The paper also investigates the impact of the new characteristic functions on the complexity of computing SHAP scores. Finally, the paper proposes modifications to the tool SHAP to use instead one of our novel characteristic functions, thereby eliminating some of the limitations reported for SHAP scores.
Refutation of Shapley Values for XAI -- Additional Evidence
Sep 30, 2023Recent work demonstrated the inadequacy of Shapley values for explainable artificial intelligence (XAI). Although to disprove a theory a single counterexample suffices, a possible criticism of earlier work is that the focus was solely on Boolean classifiers. To address such possible criticism, this paper demonstrates the inadequacy of Shapley values for families of classifiers where features are not boolean, but also for families of classifiers for which multiple classes can be picked. Furthermore, the paper shows that the features changed in any minimal $l_0$ distance adversarial examples do not include irrelevant features, thus offering further arguments regarding the inadequacy of Shapley values for XAI.
A Refutation of Shapley Values for Explainability
Sep 06, 2023
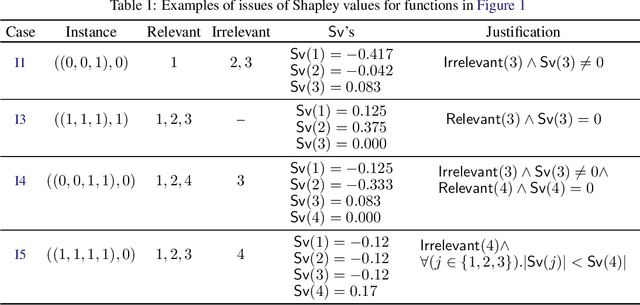
Recent work demonstrated the existence of Boolean functions for which Shapley values provide misleading information about the relative importance of features in rule-based explanations. Such misleading information was broadly categorized into a number of possible issues. Each of those issues relates with features being relevant or irrelevant for a prediction, and all are significant regarding the inadequacy of Shapley values for rule-based explainability. This earlier work devised a brute-force approach to identify Boolean functions, defined on small numbers of features, and also associated instances, which displayed such inadequacy-revealing issues, and so served as evidence to the inadequacy of Shapley values for rule-based explainability. However, an outstanding question is how frequently such inadequacy-revealing issues can occur for Boolean functions with arbitrary large numbers of features. It is plain that a brute-force approach would be unlikely to provide insights on how to tackle this question. This paper answers the above question by proving that, for any number of features, there exist Boolean functions that exhibit one or more inadequacy-revealing issues, thereby contributing decisive arguments against the use of Shapley values as the theoretical underpinning of feature-attribution methods in explainability.
Explainability is NOT a Game
Jun 27, 2023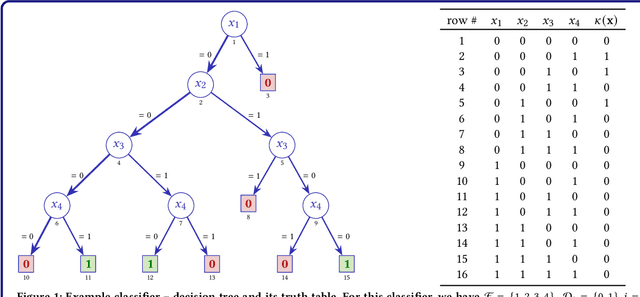
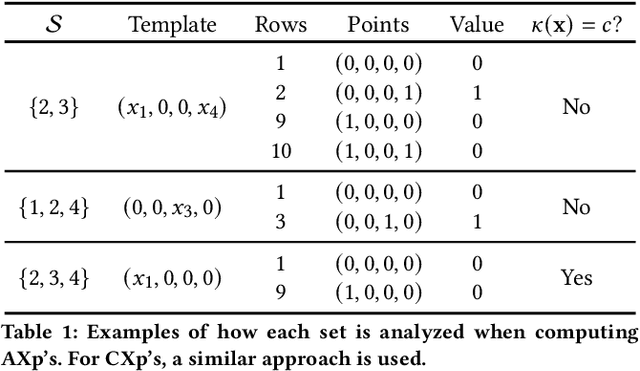
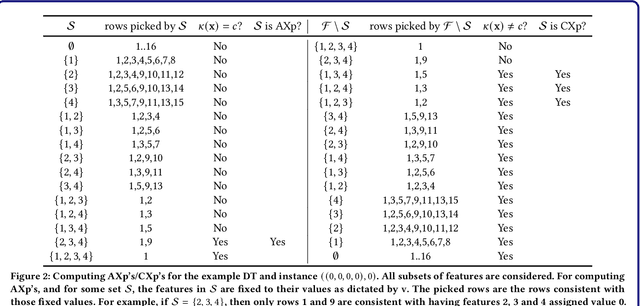
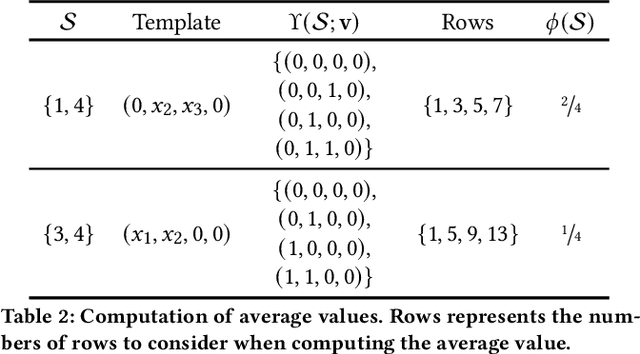
Explainable artificial intelligence (XAI) aims to help human decision-makers in understanding complex machine learning (ML) models. One of the hallmarks of XAI are measures of relative feature importance, which are theoretically justified through the use of Shapley values. This paper builds on recent work and offers a simple argument for why Shapley values can provide misleading measures of relative feature importance, by assigning more importance to features that are irrelevant for a prediction, and assigning less importance to features that are relevant for a prediction. The significance of these results is that they effectively challenge the many proposed uses of measures of relative feature importance in a fast-growing range of high-stakes application domains.