 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Trustworthy Rule-Based Models and Explanations
Jul 10, 2025


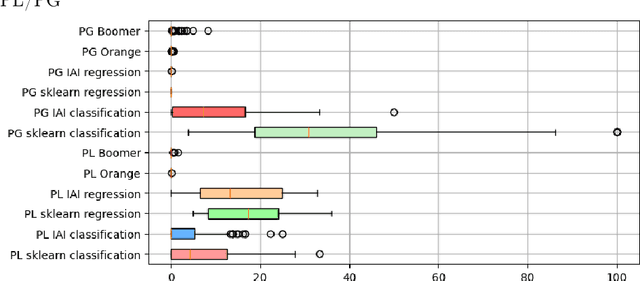
A task of interest in machine learning (ML) is that of ascribing explanations to the predictions made by ML models. Furthermore, in domains deemed high risk, the rigor of explanations is paramount. Indeed, incorrect explanations can and will mislead human decision makers. As a result, and even if interpretability is acknowledged as an elusive concept, so-called interpretable models are employed ubiquitously in high-risk uses of ML and data mining (DM). This is the case for rule-based ML models, which encompass decision trees, diagrams, sets and lists. This paper relates explanations with well-known undesired facets of rule-based ML models, which include negative overlap and several forms of redundancy. The paper develops algorithms for the analysis of these undesired facets of rule-based systems, and concludes that well-known and widely used tools for learning rule-based ML models will induce rule sets that exhibit one or more negative facets.
Distance-Restricted Explanations: Theoretical Underpinnings & Efficient Implementation
May 14, 2024



The uses of machine learning (ML) have snowballed in recent years. In many cases, ML models are highly complex, and their operation is beyond the understanding of human decision-makers. Nevertheless, some uses of ML models involve high-stakes and safety-critical applications. Explainable artificial intelligence (XAI) aims to help human decision-makers in understanding the operation of such complex ML models, thus eliciting trust in their operation. Unfortunately, the majority of past XAI work is based on informal approaches, that offer no guarantees of rigor. Unsurprisingly, there exists comprehensive experimental and theoretical evidence confirming that informal methods of XAI can provide human-decision makers with erroneous information. Logic-based XAI represents a rigorous approach to explainability; it is model-based and offers the strongest guarantees of rigor of computed explanations. However, a well-known drawback of logic-based XAI is the complexity of logic reasoning, especially for highly complex ML models. Recent work proposed distance-restricted explanations, i.e. explanations that are rigorous provided the distance to a given input is small enough. Distance-restricted explainability is tightly related with adversarial robustness, and it has been shown to scale for moderately complex ML models, but the number of inputs still represents a key limiting factor. This paper investigates novel algorithms for scaling up the performance of logic-based explainers when computing and enumerating ML model explanations with a large number of inputs.
Certified Adversarial Robustness of Machine Learning-based Malware Detectors via (De)Randomized Smoothing
May 01, 2024
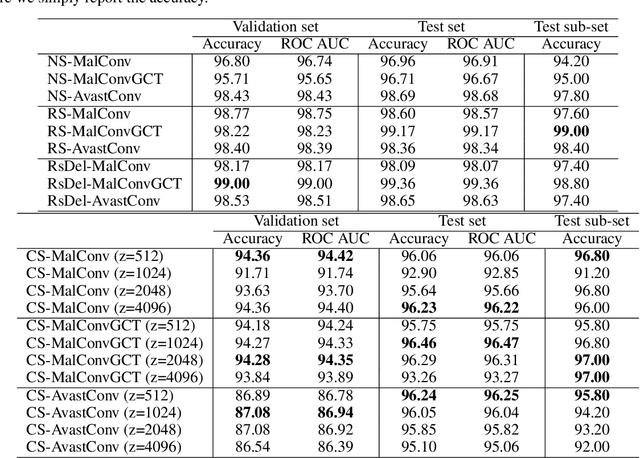


Deep learning-based malware detection systems are vulnerable to adversarial EXEmples - carefully-crafted malicious programs that evade detection with minimal perturbation. As such, the community is dedicating effort to develop mechanisms to defend against adversarial EXEmples. However, current randomized smoothing-based defenses are still vulnerable to attacks that inject blocks of adversarial content. In this paper, we introduce a certifiable defense against patch attacks that guarantees, for a given executable and an adversarial patch size, no adversarial EXEmple exist. Our method is inspired by (de)randomized smoothing which provides deterministic robustness certificates. During training, a base classifier is trained using subsets of continguous bytes. At inference time, our defense splits the executable into non-overlapping chunks, classifies each chunk independently, and computes the final prediction through majority voting to minimize the influence of injected content. Furthermore, we introduce a preprocessing step that fixes the size of the sections and headers to a multiple of the chunk size. As a consequence, the injected content is confined to an integer number of chunks without tampering the other chunks containing the real bytes of the input examples, allowing us to extend our certified robustness guarantees to content insertion attacks. We perform an extensive ablation study, by comparing our defense with randomized smoothing-based defenses against a plethora of content manipulation attacks and neural network architectures. Results show that our method exhibits unmatched robustness against strong content-insertion attacks, outperforming randomized smoothing-based defenses in the literature.
A Robust Defense against Adversarial Attacks on Deep Learning-based Malware Detectors via (De)Randomized Smoothing
Feb 26, 2024



Deep learning-based malware detectors have been shown to be susceptible to adversarial malware examples, i.e. malware examples that have been deliberately manipulated in order to avoid detection. In light of the vulnerability of deep learning detectors to subtle input file modifications, we propose a practical defense against adversarial malware examples inspired by (de)randomized smoothing. In this work, we reduce the chances of sampling adversarial content injected by malware authors by selecting correlated subsets of bytes, rather than using Gaussian noise to randomize inputs like in the Computer Vision (CV) domain. During training, our ablation-based smoothing scheme trains a base classifier to make classifications on a subset of contiguous bytes or chunk of bytes. At test time, a large number of chunks are then classified by a base classifier and the consensus among these classifications is then reported as the final prediction. We propose two strategies to determine the location of the chunks used for classification: (1) randomly selecting the locations of the chunks and (2) selecting contiguous adjacent chunks. To showcase the effectiveness of our approach, we have trained two classifiers with our chunk-based ablation schemes on the BODMAS dataset. Our findings reveal that the chunk-based smoothing classifiers exhibit greater resilience against adversarial malware examples generated with state-of-the-are evasion attacks, outperforming a non-smoothed classifier and a randomized smoothing-based classifier by a great margin.
On Logic-Based Explainability with Partially Specified Inputs
Jun 27, 2023



In the practical deployment of machine learning (ML) models, missing data represents a recurring challenge. Missing data is often addressed when training ML models. But missing data also needs to be addressed when deciding predictions and when explaining those predictions. Missing data represents an opportunity to partially specify the inputs of the prediction to be explained. This paper studies the computation of logic-based explanations in the presence of partially specified inputs. The paper shows that most of the algorithms proposed in recent years for computing logic-based explanations can be generalized for computing explanations given the partially specified inputs. One related result is that the complexity of computing logic-based explanations remains unchanged. A similar result is proved in the case of logic-based explainability subject to input constraints. Furthermore, the proposed solution for computing explanations given partially specified inputs is applied to classifiers obtained from well-known public datasets, thereby illustrating a number of novel explainability use cases.
Feature Necessity & Relevancy in ML Classifier Explanations
Oct 27, 2022Given a machine learning (ML) model and a prediction, explanations can be defined as sets of features which are sufficient for the prediction. In some applications, and besides asking for an explanation, it is also critical to understand whether sensitive features can occur in some explanation, or whether a non-interesting feature must occur in all explanations. This paper starts by relating such queries respectively with the problems of relevancy and necessity in logic-based abduction. The paper then proves membership and hardness results for several families of ML classifiers. Afterwards the paper proposes concrete algorithms for two classes of classifiers. The experimental results confirm the scalability of the proposed algorithms.
Algorithms for Weighted Boolean Optimization
Mar 06, 2009
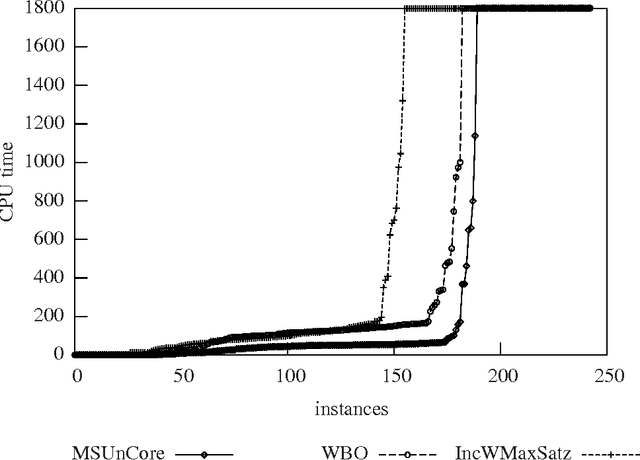

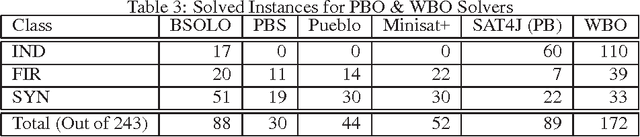
The Pseudo-Boolean Optimization (PBO) and Maximum Satisfiability (MaxSAT) problems are natural optimization extensions of Boolean Satisfiability (SAT). In the recent past, different algorithms have been proposed for PBO and for MaxSAT, despite the existence of straightforward mappings from PBO to MaxSAT and vice-versa. This papers proposes Weighted Boolean Optimization (WBO), a new unified framework that aggregates and extends PBO and MaxSAT. In addition, the paper proposes a new unsatisfiability-based algorithm for WBO, based on recent unsatisfiability-based algorithms for MaxSAT. Besides standard MaxSAT, the new algorithm can also be used to solve weighted MaxSAT and PBO, handling pseudo-Boolean constraints either natively or by translation to clausal form. Experimental results illustrate that unsatisfiability-based algorithms for MaxSAT can be orders of magnitude more efficient than existing dedicated algorithms. Finally, the paper illustrates how other algorithms for either PBO or MaxSAT can be extended to WBO.
On Using Unsatisfiability for Solving Maximum Satisfiability
Dec 07, 2007



Maximum Satisfiability (MaxSAT) is a well-known optimization pro- blem, with several practical applications. The most widely known MAXS AT algorithms are ineffective at solving hard problems instances from practical application domains. Recent work proposed using efficient Boolean Satisfiability (SAT) solvers for solving the MaxSAT problem, based on identifying and eliminating unsatisfiable subformulas. However, these algorithms do not scale in practice. This paper analyzes existing MaxSAT algorithms based on unsatisfiable subformula identification. Moreover, the paper proposes a number of key optimizations to these MaxSAT algorithms and a new alternative algorithm. The proposed optimizations and the new algorithm provide significant performance improvements on MaxSAT instances from practical applications. Moreover, the efficiency of the new generation of unsatisfiability-based MaxSAT solvers becomes effectively indexed to the ability of modern SAT solvers to proving unsatisfiability and identifying unsatisfiable subformulas.