 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign of a Bio-Inspired Miniature Submarine for Low-Cost Water Quality Monitoring
Mar 15, 2026Water quality monitoring is essential for protecting aquatic ecosystems and detecting environmental pollution. This paper presents the design and experimental validation of a bio-inspired miniature submarine for low-cost water quality monitoring. Inspired by the jet propulsion mechanism of squids, the proposed system employs pump-driven water jets for propulsion and steering, combined with a pump-based buoyancy control mechanism that enables both depth regulation and water sampling. The vehicle integrates low-cost, commercially available components including an ESP32 microcontroller, IMU, pressure sensor, GPS receiver, and LoRa communication module. The complete system can be constructed at a hardware cost of approximately $122.5, making it suitable for educational and environmental monitoring applications. Experimental validation was conducted through pool tests and field trials in a lake. During a 360 degrees rotation test, roll and pitch deviations remained within +/-2 degrees and +/-1.5 degrees, respectively, demonstrating stable attitude control. Steering experiments showed a heading step response with approximately 2 s rise time and 5 s settling time. Depth control experiments achieved a target depth of 2.5 m with steady-state error within +/-0.1 m. Field experiments further demonstrated reliable navigation and successful water sampling operations. The results confirm that the proposed platform provides a compact, stable, and cost-effective solution for small-scale aquatic environmental monitoring.
Benchmarking Political Persuasion Risks Across Frontier Large Language Models
Mar 10, 2026Concerns persist regarding the capacity of Large Language Models (LLMs) to sway political views. Although prior research has claimed that LLMs are not more persuasive than standard political campaign practices, the recent rise of frontier models warrants further study. In two survey experiments (N=19,145) across bipartisan issues and stances, we evaluate seven state-of-the-art LLMs developed by Anthropic, OpenAI, Google, and xAI. We find that LLMs outperform standard campaign advertisements, with heterogeneity in performance across models. Specifically, Claude models exhibit the highest persuasiveness, while Grok exhibits the lowest. The results are robust across issues and stances. Moreover, in contrast to the findings in Hackenburg et al. (2025b) and Lin et al. (2025) that information-based prompts boost persuasiveness, we find that the effectiveness of information-based prompts is model-dependent: they increase the persuasiveness of Claude and Grok while substantially reducing that of GPT. We introduce a data-driven and strategy-agnostic LLM-assisted conversation analysis approach to identify and assess underlying persuasive strategies. Our work benchmarks the persuasive risks of frontier models and provides a framework for cross-model comparative risk assessment.
A Framework to Assess the Persuasion Risks Large Language Model Chatbots Pose to Democratic Societies
Apr 29, 2025In recent years, significant concern has emerged regarding the potential threat that Large Language Models (LLMs) pose to democratic societies through their persuasive capabilities. We expand upon existing research by conducting two survey experiments and a real-world simulation exercise to determine whether it is more cost effective to persuade a large number of voters using LLM chatbots compared to standard political campaign practice, taking into account both the "receive" and "accept" steps in the persuasion process (Zaller 1992). These experiments improve upon previous work by assessing extended interactions between humans and LLMs (instead of using single-shot interactions) and by assessing both short- and long-run persuasive effects (rather than simply asking users to rate the persuasiveness of LLM-produced content). In two survey experiments (N = 10,417) across three distinct political domains, we find that while LLMs are about as persuasive as actual campaign ads once voters are exposed to them, political persuasion in the real-world depends on both exposure to a persuasive message and its impact conditional on exposure. Through simulations based on real-world parameters, we estimate that LLM-based persuasion costs between \$48-\$74 per persuaded voter compared to \$100 for traditional campaign methods, when accounting for the costs of exposure. However, it is currently much easier to scale traditional campaign persuasion methods than LLM-based persuasion. While LLMs do not currently appear to have substantially greater potential for large-scale political persuasion than existing non-LLM methods, this may change as LLM capabilities continue to improve and it becomes easier to scalably encourage exposure to persuasive LLMs.
Assessing the Impact of Packing on Machine Learning-Based Malware Detection and Classification Systems
Oct 31, 2024



The proliferation of malware, particularly through the use of packing, presents a significant challenge to static analysis and signature-based malware detection techniques. The application of packing to the original executable code renders extracting meaningful features and signatures challenging. To deal with the increasing amount of malware in the wild, researchers and anti-malware companies started harnessing machine learning capabilities with very promising results. However, little is known about the effects of packing on static machine learning-based malware detection and classification systems. This work addresses this gap by investigating the impact of packing on the performance of static machine learning-based models used for malware detection and classification, with a particular focus on those using visualisation techniques. To this end, we present a comprehensive analysis of various packing techniques and their effects on the performance of machine learning-based detectors and classifiers. Our findings highlight the limitations of current static detection and classification systems and underscore the need to be proactive to effectively counteract the evolving tactics of malware authors.
Certified Adversarial Robustness of Machine Learning-based Malware Detectors via (De)Randomized Smoothing
May 01, 2024
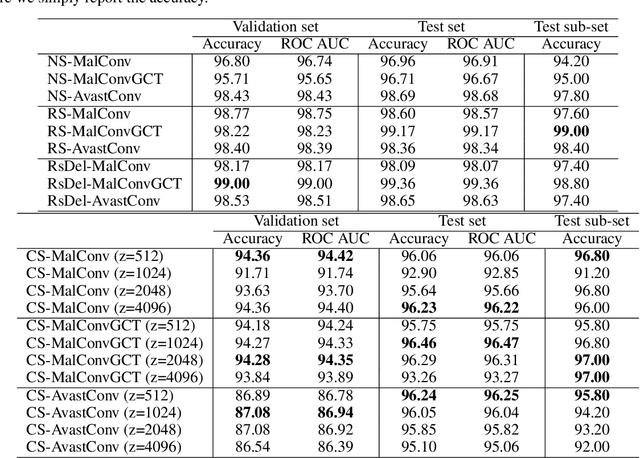


Deep learning-based malware detection systems are vulnerable to adversarial EXEmples - carefully-crafted malicious programs that evade detection with minimal perturbation. As such, the community is dedicating effort to develop mechanisms to defend against adversarial EXEmples. However, current randomized smoothing-based defenses are still vulnerable to attacks that inject blocks of adversarial content. In this paper, we introduce a certifiable defense against patch attacks that guarantees, for a given executable and an adversarial patch size, no adversarial EXEmple exist. Our method is inspired by (de)randomized smoothing which provides deterministic robustness certificates. During training, a base classifier is trained using subsets of continguous bytes. At inference time, our defense splits the executable into non-overlapping chunks, classifies each chunk independently, and computes the final prediction through majority voting to minimize the influence of injected content. Furthermore, we introduce a preprocessing step that fixes the size of the sections and headers to a multiple of the chunk size. As a consequence, the injected content is confined to an integer number of chunks without tampering the other chunks containing the real bytes of the input examples, allowing us to extend our certified robustness guarantees to content insertion attacks. We perform an extensive ablation study, by comparing our defense with randomized smoothing-based defenses against a plethora of content manipulation attacks and neural network architectures. Results show that our method exhibits unmatched robustness against strong content-insertion attacks, outperforming randomized smoothing-based defenses in the literature.
A Robust Defense against Adversarial Attacks on Deep Learning-based Malware Detectors via (De)Randomized Smoothing
Feb 26, 2024



Deep learning-based malware detectors have been shown to be susceptible to adversarial malware examples, i.e. malware examples that have been deliberately manipulated in order to avoid detection. In light of the vulnerability of deep learning detectors to subtle input file modifications, we propose a practical defense against adversarial malware examples inspired by (de)randomized smoothing. In this work, we reduce the chances of sampling adversarial content injected by malware authors by selecting correlated subsets of bytes, rather than using Gaussian noise to randomize inputs like in the Computer Vision (CV) domain. During training, our ablation-based smoothing scheme trains a base classifier to make classifications on a subset of contiguous bytes or chunk of bytes. At test time, a large number of chunks are then classified by a base classifier and the consensus among these classifications is then reported as the final prediction. We propose two strategies to determine the location of the chunks used for classification: (1) randomly selecting the locations of the chunks and (2) selecting contiguous adjacent chunks. To showcase the effectiveness of our approach, we have trained two classifiers with our chunk-based ablation schemes on the BODMAS dataset. Our findings reveal that the chunk-based smoothing classifiers exhibit greater resilience against adversarial malware examples generated with state-of-the-are evasion attacks, outperforming a non-smoothed classifier and a randomized smoothing-based classifier by a great margin.
American Stories: A Large-Scale Structured Text Dataset of Historical U.S. Newspapers
Aug 24, 2023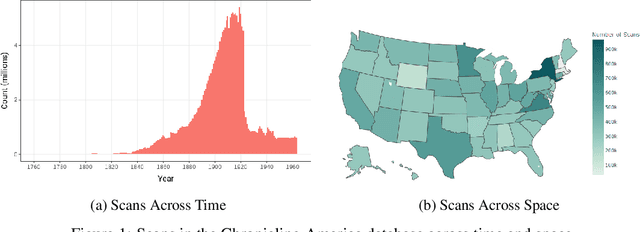
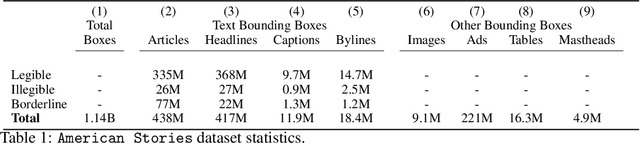

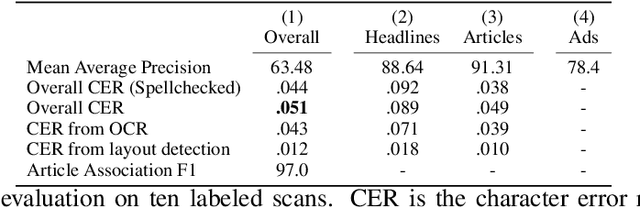
Existing full text datasets of U.S. public domain newspapers do not recognize the often complex layouts of newspaper scans, and as a result the digitized content scrambles texts from articles, headlines, captions, advertisements, and other layout regions. OCR quality can also be low. This study develops a novel, deep learning pipeline for extracting full article texts from newspaper images and applies it to the nearly 20 million scans in Library of Congress's public domain Chronicling America collection. The pipeline includes layout detection, legibility classification, custom OCR, and association of article texts spanning multiple bounding boxes. To achieve high scalability, it is built with efficient architectures designed for mobile phones. The resulting American Stories dataset provides high quality data that could be used for pre-training a large language model to achieve better understanding of historical English and historical world knowledge. The dataset could also be added to the external database of a retrieval-augmented language model to make historical information - ranging from interpretations of political events to minutiae about the lives of people's ancestors - more widely accessible. Furthermore, structured article texts facilitate using transformer-based methods for popular social science applications like topic classification, detection of reproduced content, and news story clustering. Finally, American Stories provides a massive silver quality dataset for innovating multimodal layout analysis models and other multimodal applications.
Towards a Practical Defense against Adversarial Attacks on Deep Learning-based Malware Detectors via Randomized Smoothing
Aug 17, 2023Malware detectors based on deep learning (DL) have been shown to be susceptible to malware examples that have been deliberately manipulated in order to evade detection, a.k.a. adversarial malware examples. More specifically, it has been show that deep learning detectors are vulnerable to small changes on the input file. Given this vulnerability of deep learning detectors, we propose a practical defense against adversarial malware examples inspired by randomized smoothing. In our work, instead of employing Gaussian or Laplace noise when randomizing inputs, we propose a randomized ablation-based smoothing scheme that ablates a percentage of the bytes within an executable. During training, our randomized ablation-based smoothing scheme trains a base classifier based on ablated versions of the executable files. At test time, the final classification for a given input executable is taken as the class most commonly predicted by the classifier on a set of ablated versions of the original executable. To demonstrate the suitability of our approach we have empirically evaluated the proposed ablation-based model against various state-of-the-art evasion attacks on the BODMAS dataset. Results show greater robustness and generalization capabilities to adversarial malware examples in comparison to a non-smoothed classifier.
Automated Artefact Relevancy Determination from Artefact Metadata and Associated Timeline Events
Dec 02, 2020

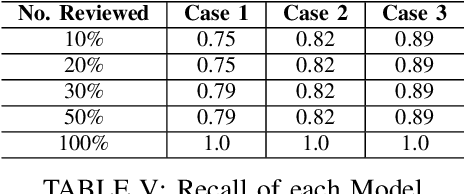
Case-hindering, multi-year digital forensic evidence backlogs have become commonplace in law enforcement agencies throughout the world. This is due to an ever-growing number of cases requiring digital forensic investigation coupled with the growing volume of data to be processed per case. Leveraging previously processed digital forensic cases and their component artefact relevancy classifications can facilitate an opportunity for training automated artificial intelligence based evidence processing systems. These can significantly aid investigators in the discovery and prioritisation of evidence. This paper presents one approach for file artefact relevancy determination building on the growing trend towards a centralised, Digital Forensics as a Service (DFaaS) paradigm. This approach enables the use of previously encountered pertinent files to classify newly discovered files in an investigation. Trained models can aid in the detection of these files during the acquisition stage, i.e., during their upload to a DFaaS system. The technique generates a relevancy score for file similarity using each artefact's filesystem metadata and associated timeline events. The approach presented is validated against three experimental usage scenarios.
Deep learning at the shallow end: Malware classification for non-domain experts
Jul 22, 2018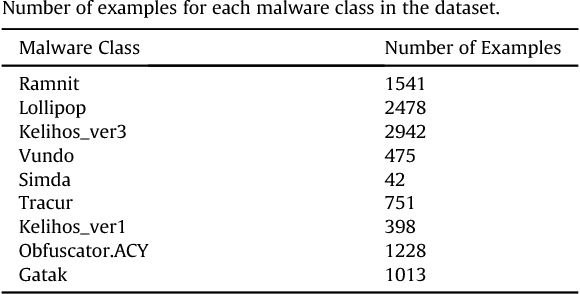
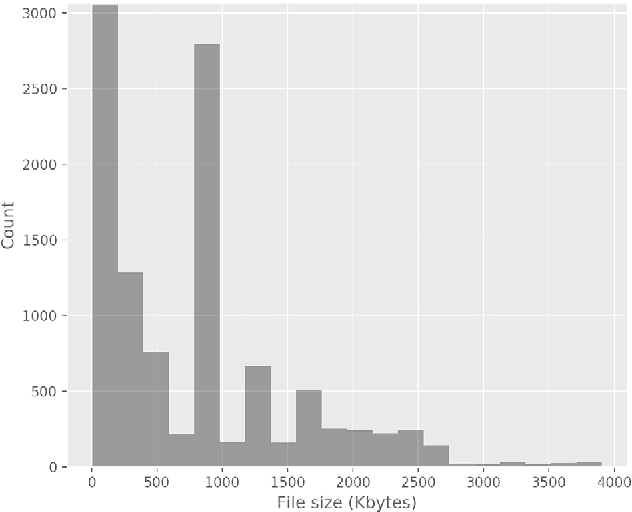

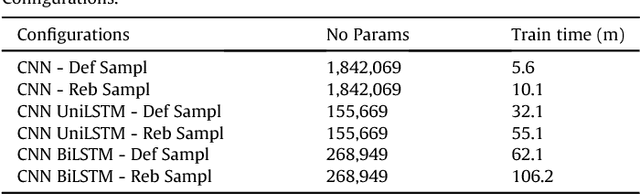
Current malware detection and classification approaches generally rely on time consuming and knowledge intensive processes to extract patterns (signatures) and behaviors from malware, which are then used for identification. Moreover, these signatures are often limited to local, contiguous sequences within the data whilst ignoring their context in relation to each other and throughout the malware file as a whole. We present a Deep Learning based malware classification approach that requires no expert domain knowledge and is based on a purely data driven approach for complex pattern and feature identification.