 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unifying Framework for Robust and Efficient Inference with Unstructured Data
May 01, 2025This paper presents a general framework for conducting efficient and robust inference on parameters derived from unstructured data, which include text, images, audio, and video. Economists have long incorporated data extracted from texts and images into their analyses, a practice that has accelerated with advancements in deep neural networks. However, neural networks do not generically produce unbiased predictions, potentially propagating bias to estimators that use their outputs. To address this challenge, we reframe inference with unstructured data as a missing structured data problem, where structured data are imputed from unstructured inputs using deep neural networks. This perspective allows us to apply classic results from semiparametric inference, yielding valid, efficient, and robust estimators based on unstructured data. We formalize this approach with MARS (Missing At Random Structured Data), a unifying framework that integrates and extends existing methods for debiased inference using machine learning predictions, linking them to a variety of older, familiar problems such as causal inference. We develop robust and efficient estimators for both descriptive and causal estimands and address challenges such as inference using aggregated and transformed predictions from unstructured data. Importantly, MARS applies to common empirical settings that have received limited attention in the existing literature. Finally, we reanalyze prominent studies that use unstructured data, demonstrating the practical value of MARS.
EfficientOCR: An Extensible, Open-Source Package for Efficiently Digitizing World Knowledge
Oct 16, 2023
Billions of public domain documents remain trapped in hard copy or lack an accurate digitization. Modern natural language processing methods cannot be used to index, retrieve, and summarize their texts; conduct computational textual analyses; or extract information for statistical analyses, and these texts cannot be incorporated into language model training. Given the diversity and sheer quantity of public domain texts, liberating them at scale requires optical character recognition (OCR) that is accurate, extremely cheap to deploy, and sample-efficient to customize to novel collections, languages, and character sets. Existing OCR engines, largely designed for small-scale commercial applications in high resource languages, often fall short of these requirements. EffOCR (EfficientOCR), a novel open-source OCR package, meets both the computational and sample efficiency requirements for liberating texts at scale by abandoning the sequence-to-sequence architecture typically used for OCR, which takes representations from a learned vision model as inputs to a learned language model. Instead, EffOCR models OCR as a character or word-level image retrieval problem. EffOCR is cheap and sample efficient to train, as the model only needs to learn characters' visual appearance and not how they are used in sequence to form language. Models in the EffOCR model zoo can be deployed off-the-shelf with only a few lines of code. Importantly, EffOCR also allows for easy, sample efficient customization with a simple model training interface and minimal labeling requirements due to its sample efficiency. We illustrate the utility of EffOCR by cheaply and accurately digitizing 20 million historical U.S. newspaper scans, evaluating zero-shot performance on randomly selected documents from the U.S. National Archives, and accurately digitizing Japanese documents for which all other OCR solutions failed.
American Stories: A Large-Scale Structured Text Dataset of Historical U.S. Newspapers
Aug 24, 2023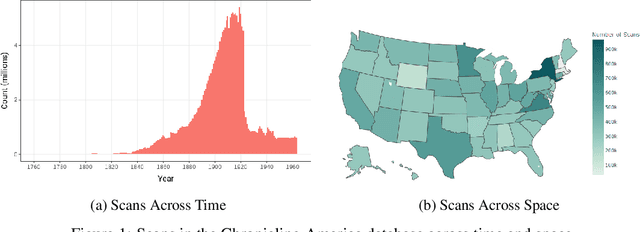
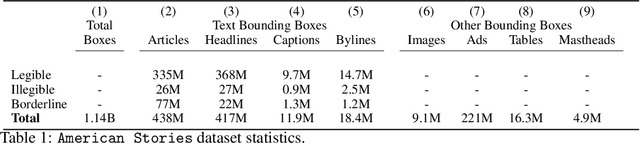

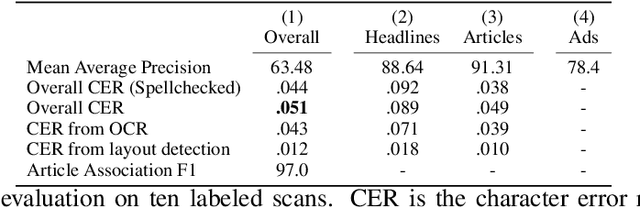
Existing full text datasets of U.S. public domain newspapers do not recognize the often complex layouts of newspaper scans, and as a result the digitized content scrambles texts from articles, headlines, captions, advertisements, and other layout regions. OCR quality can also be low. This study develops a novel, deep learning pipeline for extracting full article texts from newspaper images and applies it to the nearly 20 million scans in Library of Congress's public domain Chronicling America collection. The pipeline includes layout detection, legibility classification, custom OCR, and association of article texts spanning multiple bounding boxes. To achieve high scalability, it is built with efficient architectures designed for mobile phones. The resulting American Stories dataset provides high quality data that could be used for pre-training a large language model to achieve better understanding of historical English and historical world knowledge. The dataset could also be added to the external database of a retrieval-augmented language model to make historical information - ranging from interpretations of political events to minutiae about the lives of people's ancestors - more widely accessible. Furthermore, structured article texts facilitate using transformer-based methods for popular social science applications like topic classification, detection of reproduced content, and news story clustering. Finally, American Stories provides a massive silver quality dataset for innovating multimodal layout analysis models and other multimodal applications.
Efficient OCR for Building a Diverse Digital History
Apr 05, 2023



Thousands of users consult digital archives daily, but the information they can access is unrepresentative of the diversity of documentary history. The sequence-to-sequence architecture typically used for optical character recognition (OCR) - which jointly learns a vision and language model - is poorly extensible to low-resource document collections, as learning a language-vision model requires extensive labeled sequences and compute. This study models OCR as a character level image retrieval problem, using a contrastively trained vision encoder. Because the model only learns characters' visual features, it is more sample efficient and extensible than existing architectures, enabling accurate OCR in settings where existing solutions fail. Crucially, the model opens new avenues for community engagement in making digital history more representative of documentary history.
LayoutParser: A Unified Toolkit for Deep Learning Based Document Image Analysis
Mar 29, 2021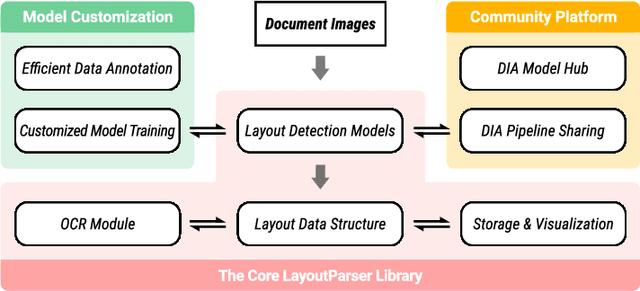
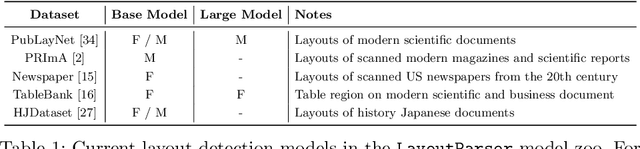

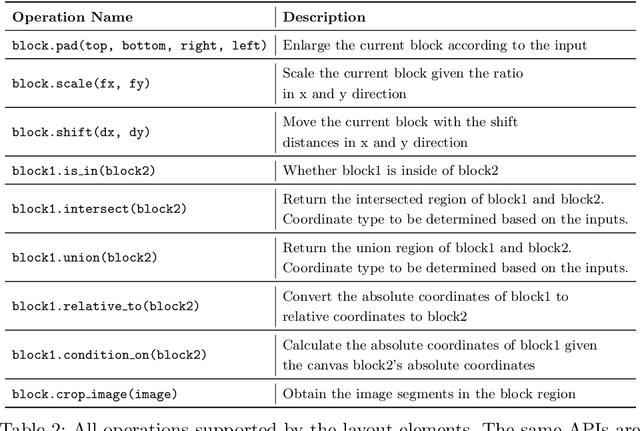
Recent advances in document image analysis (DIA) have been primarily driven by the application of neural networks. Ideally, research outcomes could be easily deployed in production and extended for further investigation. However, various factors like loosely organized codebases and sophisticated model configurations complicate the easy reuse of important innovations by a wide audience. Though there have been on-going efforts to improve reusability and simplify deep learning (DL) model development in disciplines like natural language processing and computer vision, none of them are optimized for challenges in the domain of DIA. This represents a major gap in the existing toolkit, as DIA is central to academic research across a wide range of disciplines in the social sciences and humanities. This paper introduces layoutparser, an open-source library for streamlining the usage of DL in DIA research and applications. The core layoutparser library comes with a set of simple and intuitive interfaces for applying and customizing DL models for layout detection, character recognition, and many other document processing tasks. To promote extensibility, layoutparser also incorporates a community platform for sharing both pre-trained models and full document digitization pipelines. We demonstrate that layoutparser is helpful for both lightweight and large-scale digitization pipelines in real-word use cases. The library is publicly available at https://layout-parser.github.io/.