 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGovScape: A Public Multimodal Search System for 70 Million Pages of Government PDFs
Nov 14, 2025Efforts over the past three decades have produced web archives containing billions of webpage snapshots and petabytes of data. The End of Term Web Archive alone contains, among other file types, millions of PDFs produced by the federal government. While preservation with web archives has been successful, significant challenges for access and discoverability remain. For example, current affordances for browsing the End of Term PDFs are limited to downloading and browsing individual PDFs, as well as performing basic keyword search across them. In this paper, we introduce GovScape, a public search system that supports multimodal searches across 10,015,993 federal government PDFs from the 2020 End of Term crawl (70,958,487 total PDF pages) - to our knowledge, all renderable PDFs in the 2020 crawl that are 50 pages or under. GovScape supports four primary forms of search over these 10 million PDFs: in addition to providing (1) filter conditions over metadata facets including domain and crawl date and (2) exact text search against the PDF text, we provide (3) semantic text search and (4) visual search against the PDFs across individual pages, enabling users to structure queries such as "redacted documents" or "pie charts." We detail the constituent components of GovScape, including the search affordances, embedding pipeline, system architecture, and open source codebase. Significantly, the total estimated compute cost for GovScape's pre-processing pipeline for 10 million PDFs was approximately $1,500, equivalent to 47,000 PDF pages per dollar spent on compute, demonstrating the potential for immediate scalability. Accordingly, we outline steps that we have already begun pursuing toward multimodal search at the 100+ million PDF scale. GovScape can be found at https://www.govscape.net.
Retrieval-Augmented Search for Large-Scale Map Collections with ColPali
Oct 29, 2025Multimodal approaches have shown great promise for searching and navigating digital collections held by libraries, archives, and museums. In this paper, we introduce map-RAS: a retrieval-augmented search system for historic maps. In addition to introducing our framework, we detail our publicly-hosted demo for searching 101,233 map images held by the Library of Congress. With our system, users can multimodally query the map collection via ColPali, summarize search results using Llama 3.2, and upload their own collections to perform inter-collection search. We articulate potential use cases for archivists, curators, and end-users, as well as future work with our system in both machine learning and the digital humanities. Our demo can be viewed at: http://www.mapras.com.
Digital Collections Explorer: An Open-Source, Multimodal Viewer for Searching Digital Collections
Jul 01, 2025We present Digital Collections Explorer, a web-based, open-source exploratory search platform that leverages CLIP (Contrastive Language-Image Pre-training) for enhanced visual discovery of digital collections. Our Digital Collections Explorer can be installed locally and configured to run on a visual collection of interest on disk in just a few steps. Building upon recent advances in multimodal search techniques, our interface enables natural language queries and reverse image searches over digital collections with visual features. This paper describes the system's architecture, implementation, and application to various cultural heritage collections, demonstrating its potential for democratizing access to digital archives, especially those with impoverished metadata. We present case studies with maps, photographs, and PDFs extracted from web archives in order to demonstrate the flexibility of the Digital Collections Explorer, as well as its ease of use. We demonstrate that the Digital Collections Explorer scales to hundreds of thousands of images on a MacBook Pro with an M4 chip. Lastly, we host a public demo of Digital Collections Explorer.
Integrating Visual and Textual Inputs for Searching Large-Scale Map Collections with CLIP
Oct 02, 2024



Despite the prevalence and historical importance of maps in digital collections, current methods of navigating and exploring map collections are largely restricted to catalog records and structured metadata. In this paper, we explore the potential for interactively searching large-scale map collections using natural language inputs ("maps with sea monsters"), visual inputs (i.e., reverse image search), and multimodal inputs (an example map + "more grayscale"). As a case study, we adopt 562,842 images of maps publicly accessible via the Library of Congress's API. To accomplish this, we use the mulitmodal Contrastive Language-Image Pre-training (CLIP) machine learning model to generate embeddings for these maps, and we develop code to implement exploratory search capabilities with these input strategies. We present results for example searches created in consultation with staff in the Library of Congress's Geography and Map Division and describe the strengths, weaknesses, and possibilities for these search queries. Moreover, we introduce a fine-tuning dataset of 10,504 map-caption pairs, along with an architecture for fine-tuning a CLIP model on this dataset. To facilitate re-use, we provide all of our code in documented, interactive Jupyter notebooks and place all code into the public domain. Lastly, we discuss the opportunities and challenges for applying these approaches across both digitized and born-digital collections held by galleries, libraries, archives, and museums.
The "Collections as ML Data" Checklist for Machine Learning & Cultural Heritage
Jul 06, 2022
Within the cultural heritage sector, there has been a growing and concerted effort to consider a critical sociotechnical lens when applying machine learning techniques to digital collections. Though the cultural heritage community has collectively developed an emerging body of work detailing responsible operations for machine learning in libraries and other cultural heritage institutions at the organizational level, there remains a paucity of guidelines created specifically for practitioners embarking on machine learning projects. The manifold stakes and sensitivities involved in applying machine learning to cultural heritage underscore the importance of developing such guidelines. This paper contributes to this need by formulating a detailed checklist with guiding questions and practices that can be employed while developing a machine learning project that utilizes cultural heritage data. I call the resulting checklist the "Collections as ML Data" checklist, which, when completed, can be published with the deliverables of the project. By surveying existing projects, including my own project, Newspaper Navigator, I justify the "Collections as ML Data" checklist and demonstrate how the formulated guiding questions can be employed and operationalized.
Grappling with the Scale of Born-Digital Government Publications: Toward Pipelines for Processing and Searching Millions of PDFs
Dec 05, 2021



Official government publications are key sources for understanding the history of societies. Web publishing has fundamentally changed the scale and processes by which governments produce and disseminate information. Significantly, a range of web archiving programs have captured massive troves of government publications. For example, hundreds of millions of unique U.S. Government documents posted to the web in PDF form have been archived by libraries to date. Yet, these PDFs remain largely unutilized and understudied in part due to the challenges surrounding the development of scalable pipelines for searching and analyzing them. This paper utilizes a Library of Congress dataset of 1,000 government PDFs in order to offer initial approaches for searching and analyzing these PDFs at scale. In addition to demonstrating the utility of PDF metadata, this paper offers computationally-efficient machine learning approaches to search and discovery that utilize the PDFs' textual and visual features as well. We conclude by detailing how these methods can be operationalized at scale in order to support systems for navigating millions of PDFs.
Navigating the Mise-en-Page: Interpretive Machine Learning Approaches to the Visual Layouts of Multi-Ethnic Periodicals
Sep 03, 2021



This paper presents a computational method of analysis that draws from machine learning, library science, and literary studies to map the visual layouts of multi-ethnic newspapers from the late 19th and early 20th century United States. This work departs from prior approaches to newspapers that focus on individual pieces of textual and visual content. Our method combines Chronicling America's MARC data and the Newspaper Navigator machine learning dataset to identify the visual patterns of newspaper page layouts. By analyzing high-dimensional visual similarity, we aim to better understand how editors spoke and protested through the layout of their papers.
LayoutParser: A Unified Toolkit for Deep Learning Based Document Image Analysis
Mar 29, 2021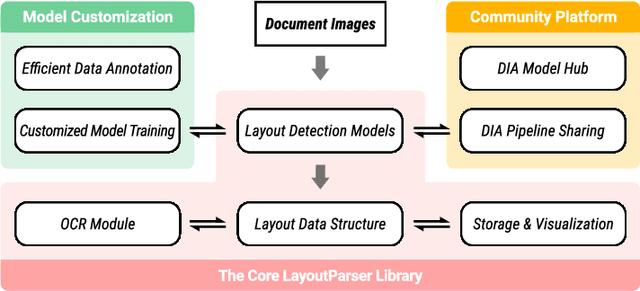
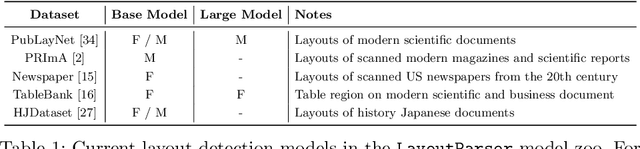

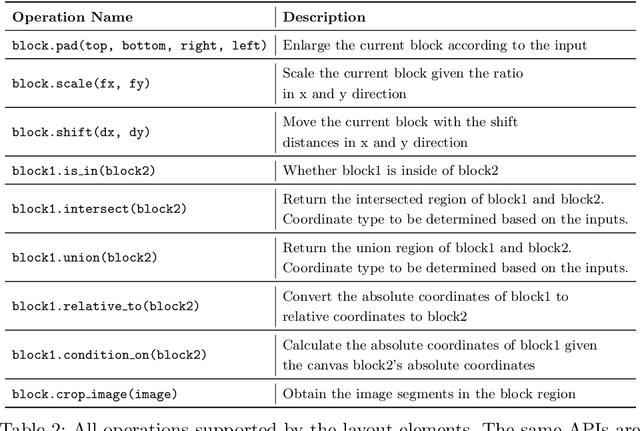
Recent advances in document image analysis (DIA) have been primarily driven by the application of neural networks. Ideally, research outcomes could be easily deployed in production and extended for further investigation. However, various factors like loosely organized codebases and sophisticated model configurations complicate the easy reuse of important innovations by a wide audience. Though there have been on-going efforts to improve reusability and simplify deep learning (DL) model development in disciplines like natural language processing and computer vision, none of them are optimized for challenges in the domain of DIA. This represents a major gap in the existing toolkit, as DIA is central to academic research across a wide range of disciplines in the social sciences and humanities. This paper introduces layoutparser, an open-source library for streamlining the usage of DL in DIA research and applications. The core layoutparser library comes with a set of simple and intuitive interfaces for applying and customizing DL models for layout detection, character recognition, and many other document processing tasks. To promote extensibility, layoutparser also incorporates a community platform for sharing both pre-trained models and full document digitization pipelines. We demonstrate that layoutparser is helpful for both lightweight and large-scale digitization pipelines in real-word use cases. The library is publicly available at https://layout-parser.github.io/.
The Newspaper Navigator Dataset: Extracting And Analyzing Visual Content from 16 Million Historic Newspaper Pages in Chronicling America
May 04, 2020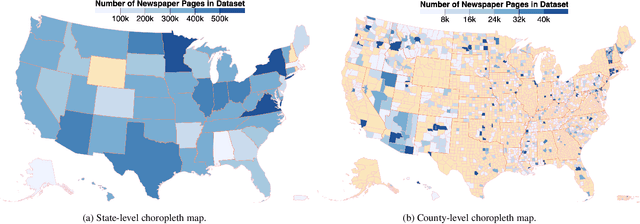
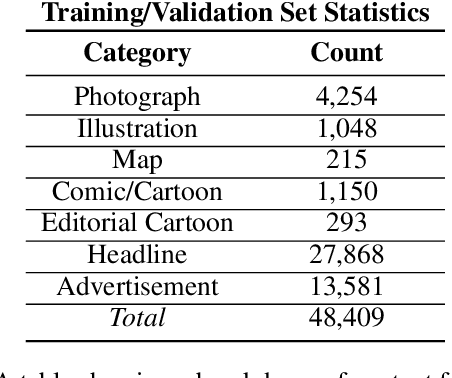
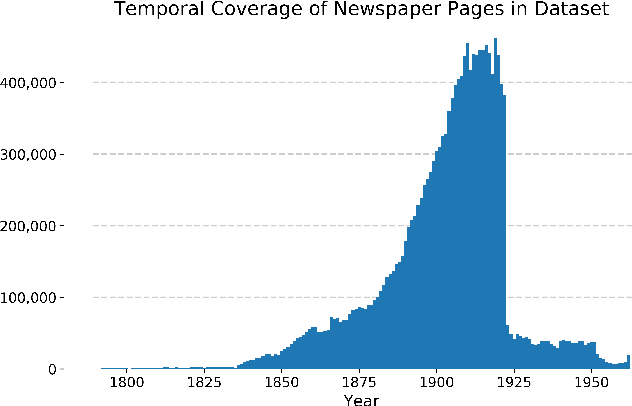

Chronicling America is a product of the National Digital Newspaper Program, a partnership between the Library of Congress and the National Endowment for the Humanities to digitize historic newspapers. Over 16 million pages of historic American newspapers have been digitized for Chronicling America to date, complete with high-resolution images and machine-readable METS/ALTO OCR. Of considerable interest to Chronicling America users is a semantified corpus, complete with extracted visual content and headlines. To accomplish this, we introduce a visual content recognition model trained on bounding box annotations of photographs, illustrations, maps, comics, and editorial cartoons collected as part of the Library of Congress's Beyond Words crowdsourcing initiative and augmented with additional annotations including those of headlines and advertisements. We describe our pipeline that utilizes this deep learning model to extract 7 classes of visual content: headlines, photographs, illustrations, maps, comics, editorial cartoons, and advertisements, complete with textual content such as captions derived from the METS/ALTO OCR, as well as image embeddings for fast image similarity querying. We report the results of running the pipeline on 16.3 million pages from the Chronicling America corpus and describe the resulting Newspaper Navigator dataset, the largest dataset of extracted visual content from historic newspapers ever produced. The Newspaper Navigator dataset, finetuned visual content recognition model, and all source code are placed in the public domain for unrestricted re-use.
Explanation-Based Tuning of Opaque Machine Learners with Application to Paper Recommendation
Mar 09, 2020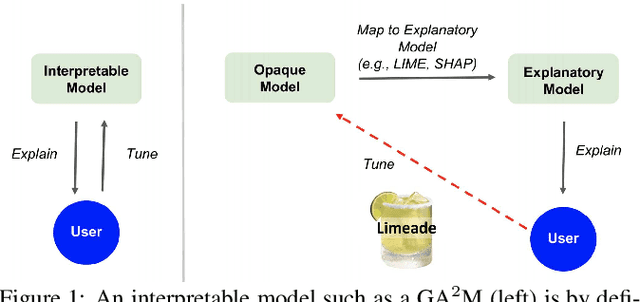



Research in human-centered AI has shown the benefits of machine-learning systems that can explain their predictions. Methods that allow users to tune a model in response to the explanations are similarly useful. While both capabilities are well-developed for transparent learning models (e.g., linear models and GA2Ms), and recent techniques (e.g., LIME and SHAP) can generate explanations for opaque models, no method currently exists for tuning of opaque models in response to explanations. This paper introduces LIMEADE, a general framework for tuning an arbitrary machine learning model based on an explanation of the model's prediction. We apply our framework to Semantic Sanity, a neural recommender system for scientific papers, and report on a detailed user study, showing that our framework leads to significantly higher perceived user control, trust, and satisfaction.