 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen One LLM Drools, Multi-LLM Collaboration Rules
Feb 06, 2025This position paper argues that in many realistic (i.e., complex, contextualized, subjective) scenarios, one LLM is not enough to produce a reliable output. We challenge the status quo of relying solely on a single general-purpose LLM and argue for multi-LLM collaboration to better represent the extensive diversity of data, skills, and people. We first posit that a single LLM underrepresents real-world data distributions, heterogeneous skills, and pluralistic populations, and that such representation gaps cannot be trivially patched by further training a single LLM. We then organize existing multi-LLM collaboration methods into a hierarchy, based on the level of access and information exchange, ranging from API-level, text-level, logit-level, to weight-level collaboration. Based on these methods, we highlight how multi-LLM collaboration addresses challenges that a single LLM struggles with, such as reliability, democratization, and pluralism. Finally, we identify the limitations of existing multi-LLM methods and motivate future work. We envision multi-LLM collaboration as an essential path toward compositional intelligence and collaborative AI development.
Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research
Jan 31, 2024



Language models have become a critical technology to tackling a wide range of natural language processing tasks, yet many details about how the best-performing language models were developed are not reported. In particular, information about their pretraining corpora is seldom discussed: commercial language models rarely provide any information about their data; even open models rarely release datasets they are trained on, or an exact recipe to reproduce them. As a result, it is challenging to conduct certain threads of language modeling research, such as understanding how training data impacts model capabilities and shapes their limitations. To facilitate open research on language model pretraining, we release Dolma, a three trillion tokens English corpus, built from a diverse mixture of web content, scientific papers, code, public-domain books, social media, and encyclopedic materials. In addition, we open source our data curation toolkit to enable further experimentation and reproduction of our work. In this report, we document Dolma, including its design principles, details about its construction, and a summary of its contents. We interleave this report with analyses and experimental results from training language models on intermediate states of Dolma to share what we have learned about important data curation practices, including the role of content or quality filters, deduplication, and multi-source mixing. Dolma has been used to train OLMo, a state-of-the-art, open language model and framework designed to build and study the science of language modeling.
American Stories: A Large-Scale Structured Text Dataset of Historical U.S. Newspapers
Aug 24, 2023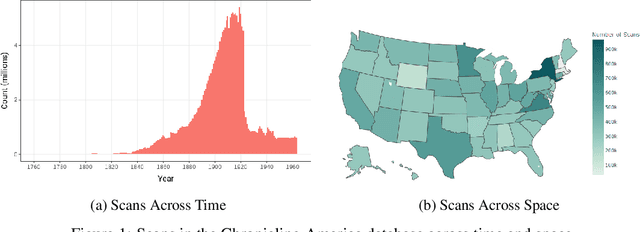
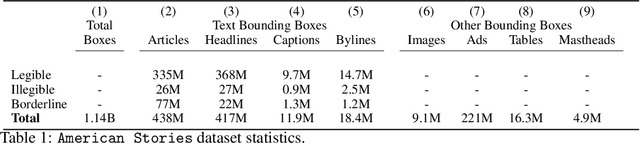

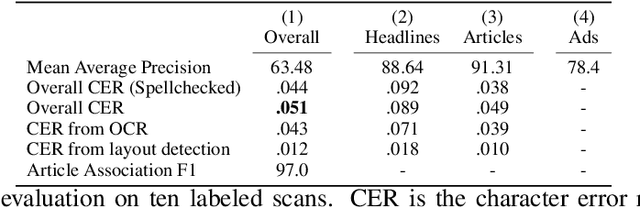
Existing full text datasets of U.S. public domain newspapers do not recognize the often complex layouts of newspaper scans, and as a result the digitized content scrambles texts from articles, headlines, captions, advertisements, and other layout regions. OCR quality can also be low. This study develops a novel, deep learning pipeline for extracting full article texts from newspaper images and applies it to the nearly 20 million scans in Library of Congress's public domain Chronicling America collection. The pipeline includes layout detection, legibility classification, custom OCR, and association of article texts spanning multiple bounding boxes. To achieve high scalability, it is built with efficient architectures designed for mobile phones. The resulting American Stories dataset provides high quality data that could be used for pre-training a large language model to achieve better understanding of historical English and historical world knowledge. The dataset could also be added to the external database of a retrieval-augmented language model to make historical information - ranging from interpretations of political events to minutiae about the lives of people's ancestors - more widely accessible. Furthermore, structured article texts facilitate using transformer-based methods for popular social science applications like topic classification, detection of reproduced content, and news story clustering. Finally, American Stories provides a massive silver quality dataset for innovating multimodal layout analysis models and other multimodal applications.
Are Layout-Infused Language Models Robust to Layout Distribution Shifts? A Case Study with Scientific Documents
Jun 01, 2023Recent work has shown that infusing layout features into language models (LMs) improves processing of visually-rich documents such as scientific papers. Layout-infused LMs are often evaluated on documents with familiar layout features (e.g., papers from the same publisher), but in practice models encounter documents with unfamiliar distributions of layout features, such as new combinations of text sizes and styles, or new spatial configurations of textual elements. In this work we test whether layout-infused LMs are robust to layout distribution shifts. As a case study we use the task of scientific document structure recovery, segmenting a scientific paper into its structural categories (e.g., "title", "caption", "reference"). To emulate distribution shifts that occur in practice we re-partition the GROTOAP2 dataset. We find that under layout distribution shifts model performance degrades by up to 20 F1. Simple training strategies, such as increasing training diversity, can reduce this degradation by over 35% relative F1; however, models fail to reach in-distribution performance in any tested out-of-distribution conditions. This work highlights the need to consider layout distribution shifts during model evaluation, and presents a methodology for conducting such evaluations.
Beyond Summarization: Designing AI Support for Real-World Expository Writing Tasks
Apr 05, 2023Large language models have introduced exciting new opportunities and challenges in designing and developing new AI-assisted writing support tools. Recent work has shown that leveraging this new technology can transform writing in many scenarios such as ideation during creative writing, editing support, and summarization. However, AI-supported expository writing--including real-world tasks like scholars writing literature reviews or doctors writing progress notes--is relatively understudied. In this position paper, we argue that developing AI supports for expository writing has unique and exciting research challenges and can lead to high real-world impacts. We characterize expository writing as evidence-based and knowledge-generating: it contains summaries of external documents as well as new information or knowledge. It can be seen as the product of authors' sensemaking process over a set of source documents, and the interplay between reading, reflection, and writing opens up new opportunities for designing AI support. We sketch three components for AI support design and discuss considerations for future research.
The Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces
Mar 25, 2023



Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the need for new technology to support the reading process grows. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. The PDF format for sharing research papers is widely used due to its portability, but it has significant downsides including: static content, poor accessibility for low-vision readers, and difficulty reading on mobile devices. This paper explores the question "Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces -- even for legacy PDFs?" We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we've developed ten research prototype interfaces and conducted usability studies with more than 300 participants and real-world users showing improved reading experiences for scholars. We've also released a production reading interface for research papers that will incorporate the best features as they mature. We structure this paper around challenges scholars and the public face when reading research papers -- Discovery, Efficiency, Comprehension, Synthesis, and Accessibility -- and present an overview of our progress and remaining open challenges.
The Semantic Scholar Open Data Platform
Jan 24, 2023



The volume of scientific output is creating an urgent need for automated tools to help scientists keep up with developments in their field. Semantic Scholar (S2) is an open data platform and website aimed at accelerating science by helping scholars discover and understand scientific literature. We combine public and proprietary data sources using state-of-the-art techniques for scholarly PDF content extraction and automatic knowledge graph construction to build the Semantic Scholar Academic Graph, the largest open scientific literature graph to-date, with 200M+ papers, 80M+ authors, 550M+ paper-authorship edges, and 2.4B+ citation edges. The graph includes advanced semantic features such as structurally parsed text, natural language summaries, and vector embeddings. In this paper, we describe the components of the S2 data processing pipeline and the associated APIs offered by the platform. We will update this living document to reflect changes as we add new data offerings and improve existing services.
Multi-LexSum: Real-World Summaries of Civil Rights Lawsuits at Multiple Granularities
Jun 23, 2022
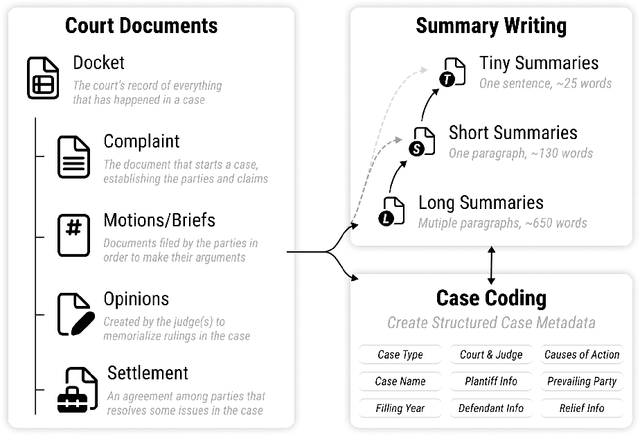
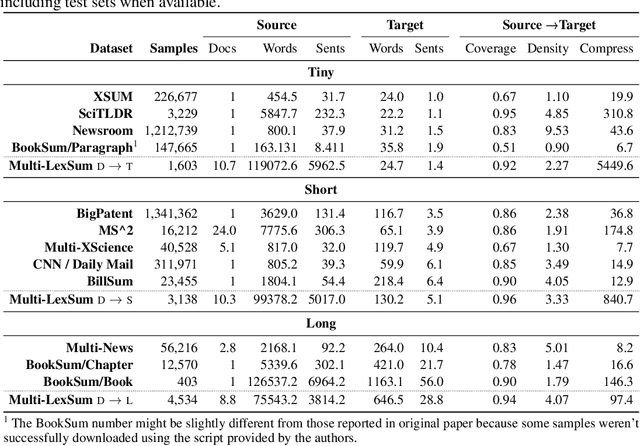

With the advent of large language models, methods for abstractive summarization have made great strides, creating potential for use in applications to aid knowledge workers processing unwieldy document collections. One such setting is the Civil Rights Litigation Clearinghouse (CRLC) (https://clearinghouse.net),which posts information about large-scale civil rights lawsuits, serving lawyers, scholars, and the general public. Today, summarization in the CRLC requires extensive training of lawyers and law students who spend hours per case understanding multiple relevant documents in order to produce high-quality summaries of key events and outcomes. Motivated by this ongoing real-world summarization effort, we introduce Multi-LexSum, a collection of 9,280 expert-authored summaries drawn from ongoing CRLC writing. Multi-LexSum presents a challenging multi-document summarization task given the length of the source documents, often exceeding two hundred pages per case. Furthermore, Multi-LexSum is distinct from other datasets in its multiple target summaries, each at a different granularity (ranging from one-sentence "extreme" summaries to multi-paragraph narrations of over five hundred words). We present extensive analysis demonstrating that despite the high-quality summaries in the training data (adhering to strict content and style guidelines), state-of-the-art summarization models perform poorly on this task. We release Multi-LexSum for further research in summarization methods as well as to facilitate development of applications to assist in the CRLC's mission at https://multilexsum.github.io.
Don't Say What You Don't Know: Improving the Consistency of Abstractive Summarization by Constraining Beam Search
Mar 16, 2022


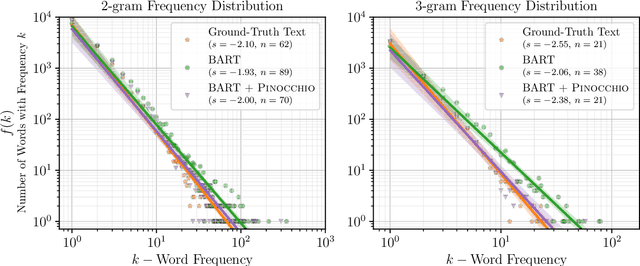
Abstractive summarization systems today produce fluent and relevant output, but often "hallucinate" statements not supported by the source text. We analyze the connection between hallucinations and training data, and find evidence that models hallucinate because they train on target summaries that are unsupported by the source. Based on our findings, we present PINOCCHIO, a new decoding method that improves the consistency of a transformer-based abstractive summarizer by constraining beam search to avoid hallucinations. Given the model states and outputs at a given step, PINOCCHIO detects likely model hallucinations based on various measures of attribution to the source text. PINOCCHIO backtracks to find more consistent output, and can opt to produce no summary at all when no consistent generation can be found. In experiments, we find that PINOCCHIO improves the consistency of generation (in terms of F1) by an average of~67% on two abstractive summarization datasets.
Incorporating Visual Layout Structures for Scientific Text Classification
Jun 21, 2021



Classifying the core textual components of a scientific paper-title, author, body text, etc.-is a critical first step in automated scientific document understanding. Previous work has shown how using elementary layout information, i.e., each token's 2D position on the page, leads to more accurate classification. We introduce new methods for incorporating VIsual LAyout (VILA) structures, e.g., the grouping of page texts into text lines or text blocks, into language models to further improve performance. We show that the I-VILA approach, which simply adds special tokens denoting the boundaries of layout structures into model inputs, can lead to 1.9% Macro F1 improvements for token classification. Moreover, we design a hierarchical model, H-VILA, that encodes the text based on layout structures and record an up-to 47% inference time reduction with less than 1.5% Macro F1 loss for the text classification models. Experiments are conducted on a newly curated evaluation suite, S2-VLUE, with a novel metric measuring classification uniformity within visual groups and a new dataset of gold annotations covering papers from 19 scientific disciplines. Pre-trained weights, benchmark datasets, and source code will be available at https://github.com/allenai/VILA.