 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoCo: A One-Stop Shop for Model Collaboration Research
Jan 29, 2026Advancing beyond single monolithic language models (LMs), recent research increasingly recognizes the importance of model collaboration, where multiple LMs collaborate, compose, and complement each other. Existing research on this topic has mostly been disparate and disconnected, from different research communities, and lacks rigorous comparison. To consolidate existing research and establish model collaboration as a school of thought, we present MoCo: a one-stop Python library of executing, benchmarking, and comparing model collaboration algorithms at scale. MoCo features 26 model collaboration methods, spanning diverse levels of cross-model information exchange such as routing, text, logit, and model parameters. MoCo integrates 25 evaluation datasets spanning reasoning, QA, code, safety, and more, while users could flexibly bring their own data. Extensive experiments with MoCo demonstrate that most collaboration strategies outperform models without collaboration in 61.0% of (model, data) settings on average, with the most effective methods outperforming by up to 25.8%. We further analyze the scaling of model collaboration strategies, the training/inference efficiency of diverse methods, highlight that the collaborative system solves problems where single LMs struggle, and discuss future work in model collaboration, all made possible by MoCo. We envision MoCo as a valuable toolkit to facilitate and turbocharge the quest for an open, modular, decentralized, and collaborative AI future.
GRACE: Generative Representation Learning via Contrastive Policy Optimization
Oct 06, 2025Prevailing methods for training Large Language Models (LLMs) as text encoders rely on contrastive losses that treat the model as a black box function, discarding its generative and reasoning capabilities in favor of static embeddings. We introduce GRACE (Generative Representation Learning via Contrastive Policy Optimization), a novel framework that reimagines contrastive signals not as losses to be minimized, but as rewards that guide a generative policy. In GRACE, the LLM acts as a policy that produces explicit, human-interpretable rationales--structured natural language explanations of its semantic understanding. These rationales are then encoded into high-quality embeddings via mean pooling. Using policy gradient optimization, we train the model with a multi-component reward function that maximizes similarity between query positive pairs and minimizes similarity with negatives. This transforms the LLM from an opaque encoder into an interpretable agent whose reasoning process is transparent and inspectable. On MTEB benchmark, GRACE yields broad cross category gains: averaged over four backbones, the supervised setting improves overall score by 11.5% over base models, and the unsupervised variant adds 6.9%, while preserving general capabilities. This work treats contrastive objectives as rewards over rationales, unifying representation learning with generation to produce stronger embeddings and transparent rationales. The model, data and code are available at https://github.com/GasolSun36/GRACE.
UQ: Assessing Language Models on Unsolved Questions
Aug 25, 2025Benchmarks shape progress in AI research. A useful benchmark should be both difficult and realistic: questions should challenge frontier models while also reflecting real-world usage. Yet, current paradigms face a difficulty-realism tension: exam-style benchmarks are often made artificially difficult with limited real-world value, while benchmarks based on real user interaction often skew toward easy, high-frequency problems. In this work, we explore a radically different paradigm: assessing models on unsolved questions. Rather than a static benchmark scored once, we curate unsolved questions and evaluate models asynchronously over time with validator-assisted screening and community verification. We introduce UQ, a testbed of 500 challenging, diverse questions sourced from Stack Exchange, spanning topics from CS theory and math to sci-fi and history, probing capabilities including reasoning, factuality, and browsing. UQ is difficult and realistic by construction: unsolved questions are often hard and naturally arise when humans seek answers, thus solving them yields direct real-world value. Our contributions are threefold: (1) UQ-Dataset and its collection pipeline combining rule-based filters, LLM judges, and human review to ensure question quality (e.g., well-defined and difficult); (2) UQ-Validators, compound validation strategies that leverage the generator-validator gap to provide evaluation signals and pre-screen candidate solutions for human review; and (3) UQ-Platform, an open platform where experts collectively verify questions and solutions. The top model passes UQ-validation on only 15% of questions, and preliminary human verification has already identified correct answers among those that passed. UQ charts a path for evaluating frontier models on real-world, open-ended challenges, where success pushes the frontier of human knowledge. We release UQ at https://uq.stanford.edu.
FlexOlmo: Open Language Models for Flexible Data Use
Jul 09, 2025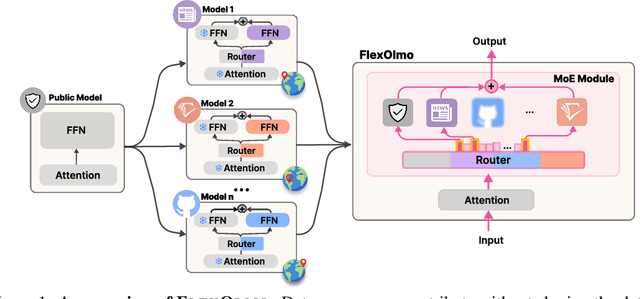
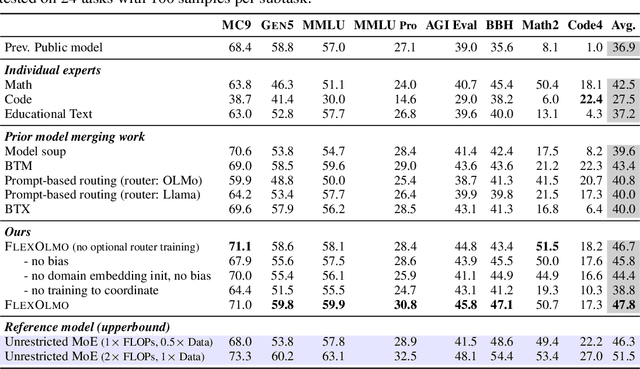
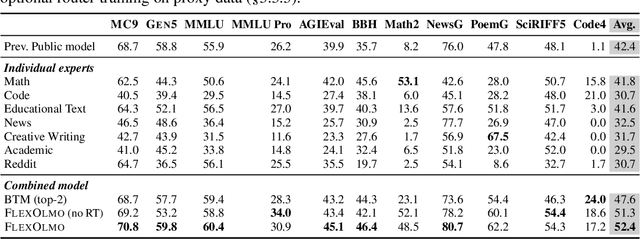
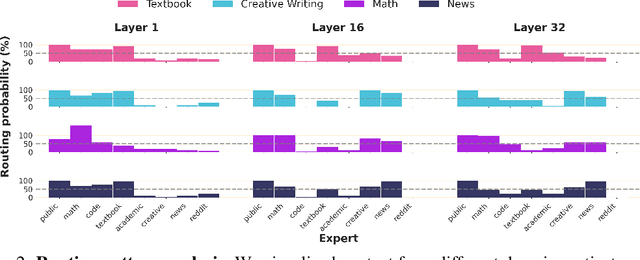
We introduce FlexOlmo, a new class of language models (LMs) that supports (1) distributed training without data sharing, where different model parameters are independently trained on closed datasets, and (2) data-flexible inference, where these parameters along with their associated data can be flexibly included or excluded from model inferences with no further training. FlexOlmo employs a mixture-of-experts (MoE) architecture where each expert is trained independently on closed datasets and later integrated through a new domain-informed routing without any joint training. FlexOlmo is trained on FlexMix, a corpus we curate comprising publicly available datasets alongside seven domain-specific sets, representing realistic approximations of closed sets. We evaluate models with up to 37 billion parameters (20 billion active) on 31 diverse downstream tasks. We show that a general expert trained on public data can be effectively combined with independently trained experts from other data owners, leading to an average 41% relative improvement while allowing users to opt out of certain data based on data licensing or permission requirements. Our approach also outperforms prior model merging methods by 10.1% on average and surpasses the standard MoE trained without data restrictions using the same training FLOPs. Altogether, this research presents a solution for both data owners and researchers in regulated industries with sensitive or protected data. FlexOlmo enables benefiting from closed data while respecting data owners' preferences by keeping their data local and supporting fine-grained control of data access during inference.
Precise Information Control in Long-Form Text Generation
Jun 06, 2025A central challenge in modern language models (LMs) is intrinsic hallucination: the generation of information that is plausible but unsubstantiated relative to input context. To study this problem, we propose Precise Information Control (PIC), a new task formulation that requires models to generate long-form outputs grounded in a provided set of short self-contained statements, known as verifiable claims, without adding any unsupported ones. For comprehensiveness, PIC includes a full setting that tests a model's ability to include exactly all input claims, and a partial setting that requires the model to selectively incorporate only relevant claims. We present PIC-Bench, a benchmark of eight long-form generation tasks (e.g., summarization, biography generation) adapted to the PIC setting, where LMs are supplied with well-formed, verifiable input claims. Our evaluation of a range of open and proprietary LMs on PIC-Bench reveals that, surprisingly, state-of-the-art LMs still intrinsically hallucinate in over 70% of outputs. To alleviate this lack of faithfulness, we introduce a post-training framework, using a weakly supervised preference data construction method, to train an 8B PIC-LM with stronger PIC ability--improving from 69.1% to 91.0% F1 in the full PIC setting. When integrated into end-to-end factual generation pipelines, PIC-LM improves exact match recall by 17.1% on ambiguous QA with retrieval, and factual precision by 30.5% on a birthplace verification task, underscoring the potential of precisely grounded generation.
ParaPO: Aligning Language Models to Reduce Verbatim Reproduction of Pre-training Data
Apr 20, 2025Language models (LMs) can memorize and reproduce segments from their pretraining data verbatim even in non-adversarial settings, raising concerns about copyright, plagiarism, privacy, and creativity. We introduce Paraphrase Preference Optimization (ParaPO), a post-training method that fine-tunes LMs to reduce unintentional regurgitation while preserving their overall utility. ParaPO trains LMs to prefer paraphrased versions of memorized segments over the original verbatim content from the pretraining data. To maintain the ability to recall famous quotations when appropriate, we develop a variant of ParaPO that uses system prompts to control regurgitation behavior. In our evaluation on Llama3.1-8B, ParaPO consistently reduces regurgitation across all tested datasets (e.g., reducing the regurgitation metric from 17.3 to 12.9 in creative writing), whereas unlearning methods used in prior work to mitigate regurgitation are less effective outside their targeted unlearned domain (from 17.3 to 16.9). When applied to the instruction-tuned Tulu3-8B model, ParaPO with system prompting successfully preserves famous quotation recall while reducing unintentional regurgitation (from 8.7 to 6.3 in creative writing) when prompted not to regurgitate. In contrast, without ParaPO tuning, prompting the model not to regurgitate produces only a marginal reduction (8.7 to 8.4).
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
When One LLM Drools, Multi-LLM Collaboration Rules
Feb 06, 2025This position paper argues that in many realistic (i.e., complex, contextualized, subjective) scenarios, one LLM is not enough to produce a reliable output. We challenge the status quo of relying solely on a single general-purpose LLM and argue for multi-LLM collaboration to better represent the extensive diversity of data, skills, and people. We first posit that a single LLM underrepresents real-world data distributions, heterogeneous skills, and pluralistic populations, and that such representation gaps cannot be trivially patched by further training a single LLM. We then organize existing multi-LLM collaboration methods into a hierarchy, based on the level of access and information exchange, ranging from API-level, text-level, logit-level, to weight-level collaboration. Based on these methods, we highlight how multi-LLM collaboration addresses challenges that a single LLM struggles with, such as reliability, democratization, and pluralism. Finally, we identify the limitations of existing multi-LLM methods and motivate future work. We envision multi-LLM collaboration as an essential path toward compositional intelligence and collaborative AI development.
Heterogeneous Swarms: Jointly Optimizing Model Roles and Weights for Multi-LLM Systems
Feb 06, 2025



We propose Heterogeneous Swarms, an algorithm to design multi-LLM systems by jointly optimizing model roles and weights. We represent multi-LLM systems as directed acyclic graphs (DAGs) of LLMs with topological message passing for collaborative generation. Given a pool of LLM experts and a utility function, Heterogeneous Swarms employs two iterative steps: role-step and weight-step. For role-step, we interpret model roles as learning a DAG that specifies the flow of inputs and outputs between LLMs. Starting from a swarm of random continuous adjacency matrices, we decode them into discrete DAGs, call the LLMs in topological order, evaluate on the utility function (e.g. accuracy on a task), and optimize the adjacency matrices with particle swarm optimization based on the utility score. For weight-step, we assess the contribution of individual LLMs in the multi-LLM systems and optimize model weights with swarm intelligence. We propose JFK-score to quantify the individual contribution of each LLM in the best-found DAG of the role-step, then optimize model weights with particle swarm optimization based on the JFK-score. Experiments demonstrate that Heterogeneous Swarms outperforms 15 role- and/or weight-based baselines by 18.5% on average across 12 tasks. Further analysis reveals that Heterogeneous Swarms discovers multi-LLM systems with heterogeneous model roles and substantial collaborative gains, and benefits from the diversity of language models.
s1: Simple test-time scaling
Jan 31, 2025



Test-time scaling is a promising new approach to language modeling that uses extra test-time compute to improve performance. Recently, OpenAI's o1 model showed this capability but did not publicly share its methodology, leading to many replication efforts. We seek the simplest approach to achieve test-time scaling and strong reasoning performance. First, we curate a small dataset s1K of 1,000 questions paired with reasoning traces relying on three criteria we validate through ablations: difficulty, diversity, and quality. Second, we develop budget forcing to control test-time compute by forcefully terminating the model's thinking process or lengthening it by appending "Wait" multiple times to the model's generation when it tries to end. This can lead the model to double-check its answer, often fixing incorrect reasoning steps. After supervised finetuning the Qwen2.5-32B-Instruct language model on s1K and equipping it with budget forcing, our model s1 exceeds o1-preview on competition math questions by up to 27% (MATH and AIME24). Further, scaling s1 with budget forcing allows extrapolating beyond its performance without test-time intervention: from 50% to 57% on AIME24. Our model, data, and code are open-source at https://github.com/simplescaling/s1.