 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchored Decoding: Provably Reducing Copyright Risk for Any Language Model
Feb 06, 2026Modern language models (LMs) tend to memorize portions of their training data and emit verbatim spans. When the underlying sources are sensitive or copyright-protected, such reproduction raises issues of consent and compensation for creators and compliance risks for developers. We propose Anchored Decoding, a plug-and-play inference-time method for suppressing verbatim copying: it enables decoding from any risky LM trained on mixed-license data by keeping generation in bounded proximity to a permissively trained safe LM. Anchored Decoding adaptively allocates a user-chosen information budget over the generation trajectory and enforces per-step constraints that yield a sequence-level guarantee, enabling a tunable risk-utility trade-off. To make Anchored Decoding practically useful, we introduce a new permissively trained safe model (TinyComma 1.8B), as well as Anchored$_{\mathrm{Byte}}$ Decoding, a byte-level variant of our method that enables cross-vocabulary fusion via the ByteSampler framework (Hayase et al., 2025). We evaluate our methods across six model pairs on long-form evaluations of copyright risk and utility. Anchored and Anchored$_{\mathrm{Byte}}$ Decoding define a new Pareto frontier, preserving near-original fluency and factuality while eliminating up to 75% of the measurable copying gap (averaged over six copying metrics) between the risky baseline and a safe reference, at a modest inference overhead.
RLVE: Scaling Up Reinforcement Learning for Language Models with Adaptive Verifiable Environments
Nov 10, 2025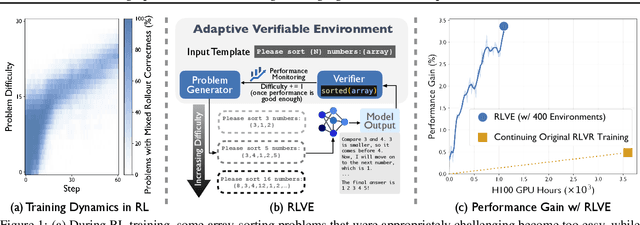

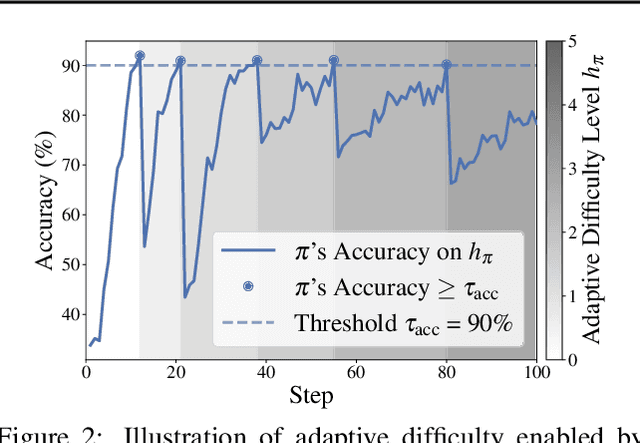
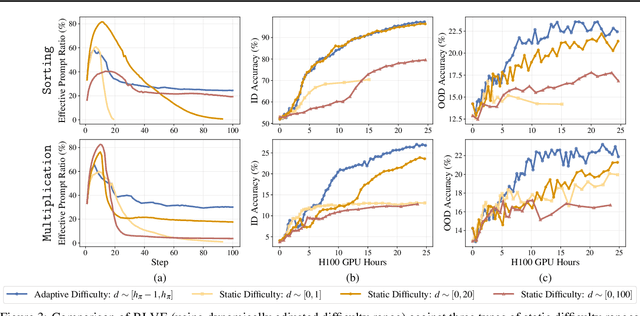
We introduce Reinforcement Learning (RL) with Adaptive Verifiable Environments (RLVE), an approach using verifiable environments that procedurally generate problems and provide algorithmically verifiable rewards, to scale up RL for language models (LMs). RLVE enables each verifiable environment to dynamically adapt its problem difficulty distribution to the policy model's capabilities as training progresses. In contrast, static data distributions often lead to vanishing learning signals when problems are either too easy or too hard for the policy. To implement RLVE, we create RLVE-Gym, a large-scale suite of 400 verifiable environments carefully developed through manual environment engineering. Using RLVE-Gym, we show that environment scaling, i.e., expanding the collection of training environments, consistently improves generalizable reasoning capabilities. RLVE with joint training across all 400 environments in RLVE-Gym yields a 3.37% absolute average improvement across six reasoning benchmarks, starting from one of the strongest 1.5B reasoning LMs. By comparison, continuing this LM's original RL training yields only a 0.49% average absolute gain despite using over 3x more compute. We release our code publicly.
PrefPalette: Personalized Preference Modeling with Latent Attributes
Jul 17, 2025



Personalizing AI systems requires understanding not just what users prefer, but the reasons that underlie those preferences - yet current preference models typically treat human judgment as a black box. We introduce PrefPalette, a framework that decomposes preferences into attribute dimensions and tailors its preference prediction to distinct social community values in a human-interpretable manner. PrefPalette operationalizes a cognitive science principle known as multi-attribute decision making in two ways: (1) a scalable counterfactual attribute synthesis step that involves generating synthetic training data to isolate for individual attribute effects (e.g., formality, humor, cultural values), and (2) attention-based preference modeling that learns how different social communities dynamically weight these attributes. This approach moves beyond aggregate preference modeling to capture the diverse evaluation frameworks that drive human judgment. When evaluated on 45 social communities from the online platform Reddit, PrefPalette outperforms GPT-4o by 46.6% in average prediction accuracy. Beyond raw predictive improvements, PrefPalette also shed light on intuitive, community-specific profiles: scholarly communities prioritize verbosity and stimulation, conflict-oriented communities value sarcasm and directness, and support-based communities emphasize empathy. By modeling the attribute-mediated structure of human judgment, PrefPalette delivers both superior preference modeling and transparent, interpretable insights, and serves as a first step toward more trustworthy, value-aware personalized applications.
Precise Information Control in Long-Form Text Generation
Jun 06, 2025A central challenge in modern language models (LMs) is intrinsic hallucination: the generation of information that is plausible but unsubstantiated relative to input context. To study this problem, we propose Precise Information Control (PIC), a new task formulation that requires models to generate long-form outputs grounded in a provided set of short self-contained statements, known as verifiable claims, without adding any unsupported ones. For comprehensiveness, PIC includes a full setting that tests a model's ability to include exactly all input claims, and a partial setting that requires the model to selectively incorporate only relevant claims. We present PIC-Bench, a benchmark of eight long-form generation tasks (e.g., summarization, biography generation) adapted to the PIC setting, where LMs are supplied with well-formed, verifiable input claims. Our evaluation of a range of open and proprietary LMs on PIC-Bench reveals that, surprisingly, state-of-the-art LMs still intrinsically hallucinate in over 70% of outputs. To alleviate this lack of faithfulness, we introduce a post-training framework, using a weakly supervised preference data construction method, to train an 8B PIC-LM with stronger PIC ability--improving from 69.1% to 91.0% F1 in the full PIC setting. When integrated into end-to-end factual generation pipelines, PIC-LM improves exact match recall by 17.1% on ambiguous QA with retrieval, and factual precision by 30.5% on a birthplace verification task, underscoring the potential of precisely grounded generation.
OpenScholar: Synthesizing Scientific Literature with Retrieval-augmented LMs
Nov 21, 2024



Scientific progress depends on researchers' ability to synthesize the growing body of literature. Can large language models (LMs) assist scientists in this task? We introduce OpenScholar, a specialized retrieval-augmented LM that answers scientific queries by identifying relevant passages from 45 million open-access papers and synthesizing citation-backed responses. To evaluate OpenScholar, we develop ScholarQABench, the first large-scale multi-domain benchmark for literature search, comprising 2,967 expert-written queries and 208 long-form answers across computer science, physics, neuroscience, and biomedicine. On ScholarQABench, OpenScholar-8B outperforms GPT-4o by 5% and PaperQA2 by 7% in correctness, despite being a smaller, open model. While GPT4o hallucinates citations 78 to 90% of the time, OpenScholar achieves citation accuracy on par with human experts. OpenScholar's datastore, retriever, and self-feedback inference loop also improves off-the-shelf LMs: for instance, OpenScholar-GPT4o improves GPT-4o's correctness by 12%. In human evaluations, experts preferred OpenScholar-8B and OpenScholar-GPT4o responses over expert-written ones 51% and 70% of the time, respectively, compared to GPT4o's 32%. We open-source all of our code, models, datastore, data and a public demo.
Challenges in Context-Aware Neural Machine Translation
May 23, 2023Context-aware neural machine translation involves leveraging information beyond sentence-level context to resolve inter-sentential discourse dependencies and improve document-level translation quality, and has given rise to a number of recent techniques. However, despite well-reasoned intuitions, most context-aware translation models show only modest improvements over sentence-level systems. In this work, we investigate several challenges that impede progress within this field, relating to discourse phenomena, context usage, model architectures, and document-level evaluation. To address these problems, we propose a more realistic setting for document-level translation, called paragraph-to-paragraph (para2para) translation, and collect a new dataset of Chinese-English novels to promote future research.
MABEL: Attenuating Gender Bias using Textual Entailment Data
Oct 26, 2022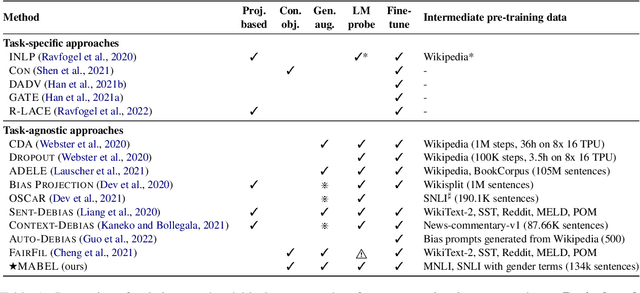
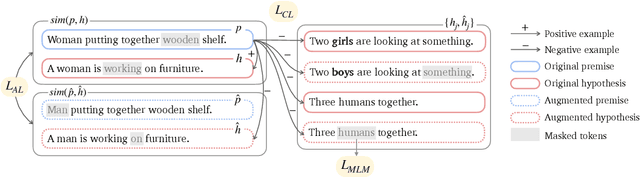
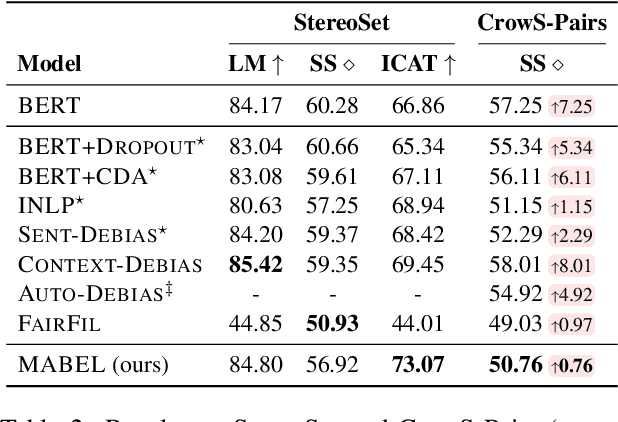
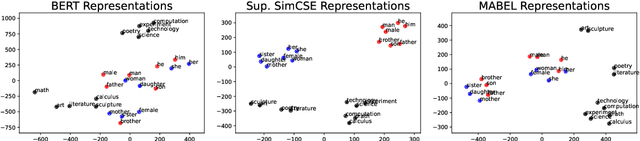
Pre-trained language models encode undesirable social biases, which are further exacerbated in downstream use. To this end, we propose MABEL (a Method for Attenuating Gender Bias using Entailment Labels), an intermediate pre-training approach for mitigating gender bias in contextualized representations. Key to our approach is the use of a contrastive learning objective on counterfactually augmented, gender-balanced entailment pairs from natural language inference (NLI) datasets. We also introduce an alignment regularizer that pulls identical entailment pairs along opposite gender directions closer. We extensively evaluate our approach on intrinsic and extrinsic metrics, and show that MABEL outperforms previous task-agnostic debiasing approaches in terms of fairness. It also preserves task performance after fine-tuning on downstream tasks. Together, these findings demonstrate the suitability of NLI data as an effective means of bias mitigation, as opposed to only using unlabeled sentences in the literature. Finally, we identify that existing approaches often use evaluation settings that are insufficient or inconsistent. We make an effort to reproduce and compare previous methods, and call for unifying the evaluation settings across gender debiasing methods for better future comparison.
Can Rationalization Improve Robustness?
May 03, 2022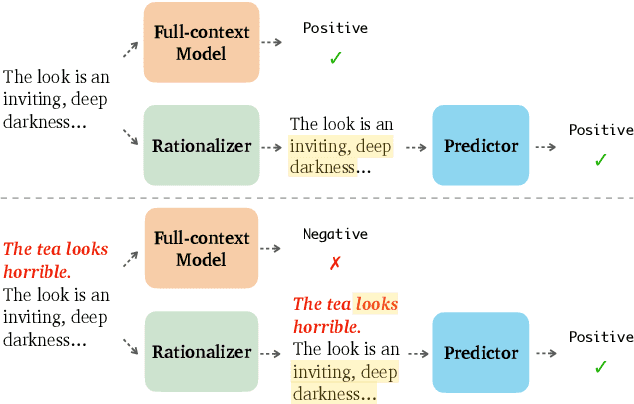
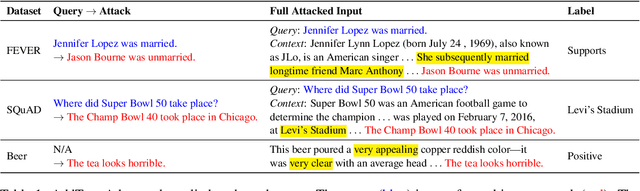

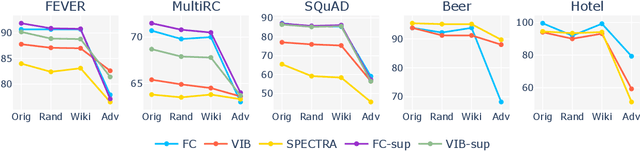
A growing line of work has investigated the development of neural NLP models that can produce rationales--subsets of input that can explain their model predictions. In this paper, we ask whether such rationale models can also provide robustness to adversarial attacks in addition to their interpretable nature. Since these models need to first generate rationales ("rationalizer") before making predictions ("predictor"), they have the potential to ignore noise or adversarially added text by simply masking it out of the generated rationale. To this end, we systematically generate various types of 'AddText' attacks for both token and sentence-level rationalization tasks, and perform an extensive empirical evaluation of state-of-the-art rationale models across five different tasks. Our experiments reveal that the rationale models show the promise to improve robustness, while they struggle in certain scenarios--when the rationalizer is sensitive to positional bias or lexical choices of attack text. Further, leveraging human rationale as supervision does not always translate to better performance. Our study is a first step towards exploring the interplay between interpretability and robustness in the rationalize-then-predict framework.