 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLugha-Llama: Adapting Large Language Models for African Languages
Apr 09, 2025



Large language models (LLMs) have achieved impressive results in a wide range of natural language applications. However, they often struggle to recognize low-resource languages, in particular African languages, which are not well represented in large training corpora. In this paper, we consider how to adapt LLMs to low-resource African languages. We find that combining curated data from African languages with high-quality English educational texts results in a training mix that substantially improves the model's performance on these languages. On the challenging IrokoBench dataset, our models consistently achieve the best performance amongst similarly sized baselines, particularly on knowledge-intensive multiple-choice questions (AfriMMLU). Additionally, on the cross-lingual question answering benchmark AfriQA, our models outperform the base model by over 10%. To better understand the role of English data during training, we translate a subset of 200M tokens into Swahili language and perform an analysis which reveals that the content of these data is primarily responsible for the strong performance. We release our models and data to encourage future research on African languages.
Human and Automatic Interpretation of Romanian Noun Compounds
Mar 11, 2024Determining the intended, context-dependent meanings of noun compounds like "shoe sale" and "fire sale" remains a challenge for NLP. Previous work has relied on inventories of semantic relations that capture the different meanings between compound members. Focusing on Romanian compounds, whose morphosyntax differs from that of their English counterparts, we propose a new set of relations and test it with human annotators and a neural net classifier. Results show an alignment of the network's predictions and human judgments, even where the human agreement rate is low. Agreement tracks with the frequency of the selected relations, regardless of structural differences. However, the most frequently selected relation was none of the sixteen labeled semantic relations, indicating the need for a better relation inventory.
MABEL: Attenuating Gender Bias using Textual Entailment Data
Oct 26, 2022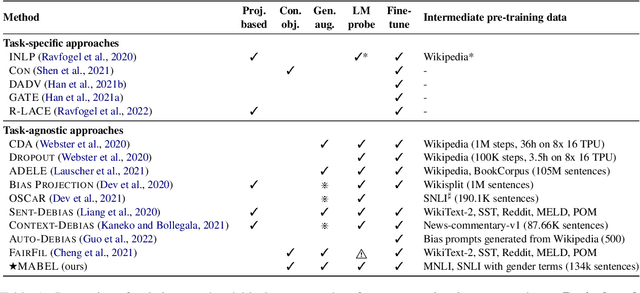
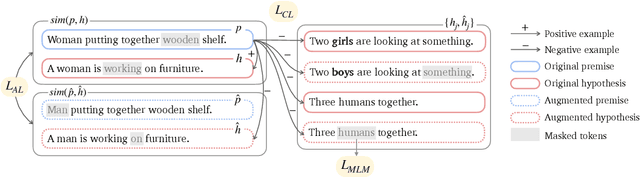
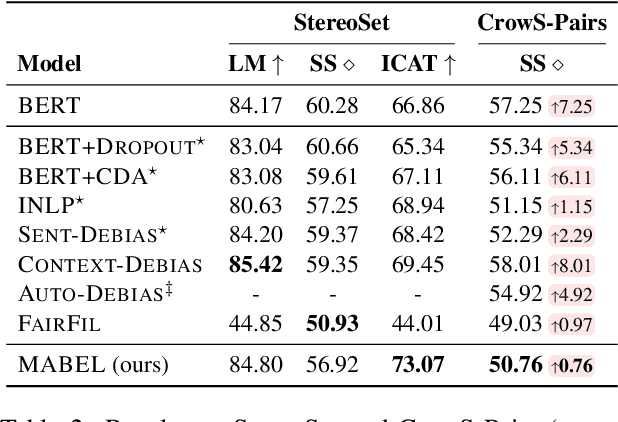
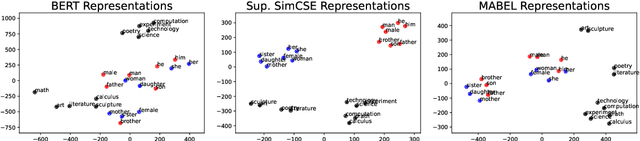
Pre-trained language models encode undesirable social biases, which are further exacerbated in downstream use. To this end, we propose MABEL (a Method for Attenuating Gender Bias using Entailment Labels), an intermediate pre-training approach for mitigating gender bias in contextualized representations. Key to our approach is the use of a contrastive learning objective on counterfactually augmented, gender-balanced entailment pairs from natural language inference (NLI) datasets. We also introduce an alignment regularizer that pulls identical entailment pairs along opposite gender directions closer. We extensively evaluate our approach on intrinsic and extrinsic metrics, and show that MABEL outperforms previous task-agnostic debiasing approaches in terms of fairness. It also preserves task performance after fine-tuning on downstream tasks. Together, these findings demonstrate the suitability of NLI data as an effective means of bias mitigation, as opposed to only using unlabeled sentences in the literature. Finally, we identify that existing approaches often use evaluation settings that are insufficient or inconsistent. We make an effort to reproduce and compare previous methods, and call for unifying the evaluation settings across gender debiasing methods for better future comparison.
Mitigating Gender Bias in Machine Translation through Adversarial Learning
Mar 20, 2022
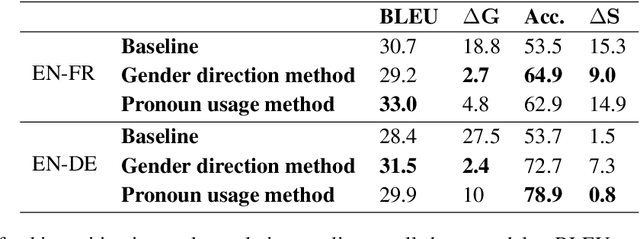
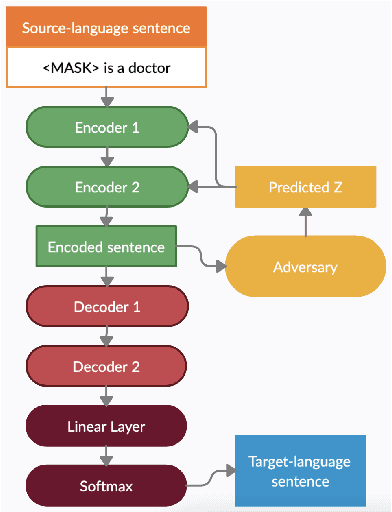

Machine translation and other NLP systems often contain significant biases regarding sensitive attributes, such as gender or race, that worsen system performance and perpetuate harmful stereotypes. Recent preliminary research suggests that adversarial learning can be used as part of a model-agnostic bias mitigation method that requires no data modifications. However, adapting this strategy for machine translation and other modern NLP domains requires (1) restructuring training objectives in the context of fine-tuning pretrained large language models and (2) developing measures for gender or other protected variables for tasks in which these attributes must be deduced from the data itself. We present an adversarial learning framework that addresses these challenges to mitigate gender bias in seq2seq machine translation. Our framework improves the disparity in translation quality for sentences with male vs. female entities by 86% for English-German translation and 91% for English-French translation, with minimal effect on translation quality. The results suggest that adversarial learning is a promising technique for mitigating gender bias in machine translation.
Extending and Improving Wordnet via Unsupervised Word Embeddings
Apr 29, 2017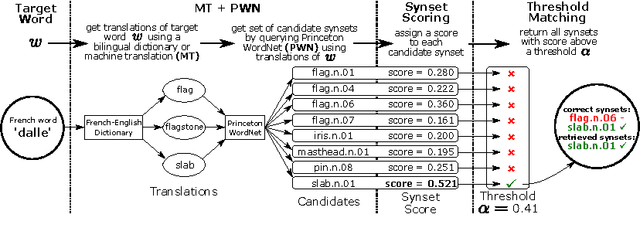
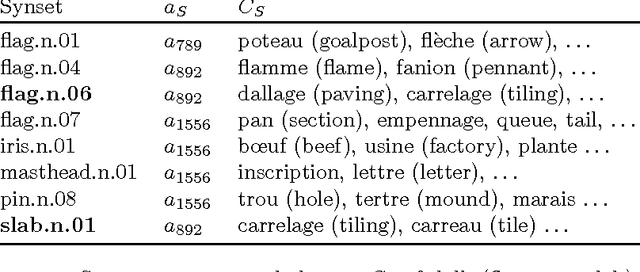
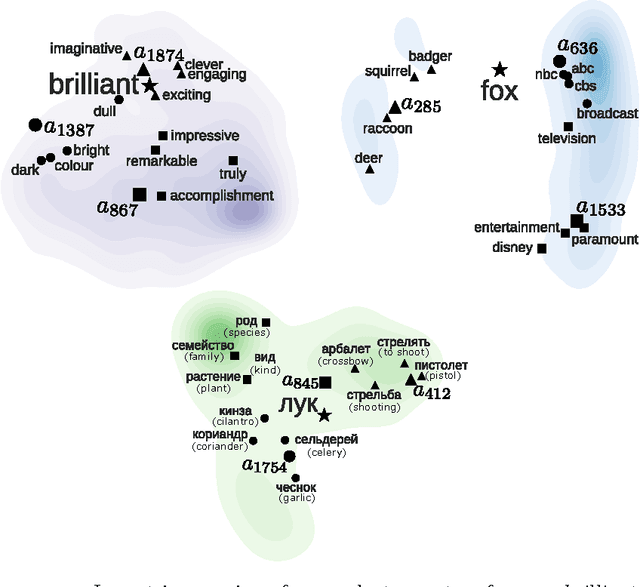
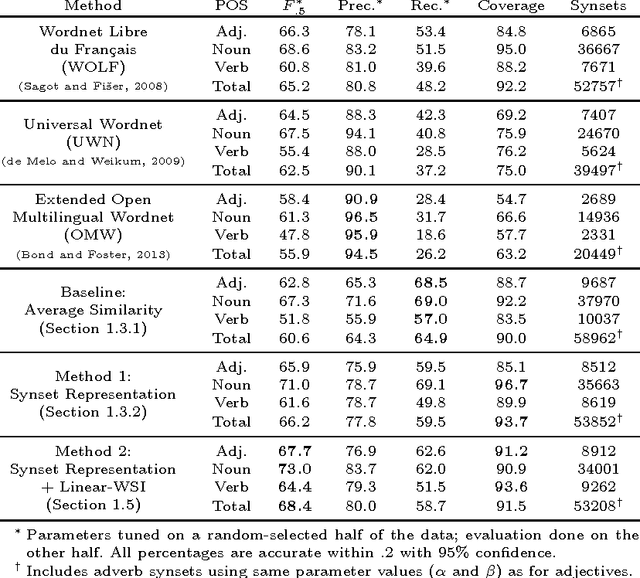
This work presents an unsupervised approach for improving WordNet that builds upon recent advances in document and sense representation via distributional semantics. We apply our methods to construct Wordnets in French and Russian, languages which both lack good manual constructions.1 These are evaluated on two new 600-word test sets for word-to-synset matching and found to improve greatly upon synset recall, outperforming the best automated Wordnets in F-score. Our methods require very few linguistic resources, thus being applicable for Wordnet construction in low-resources languages, and may further be applied to sense clustering and other Wordnet improvements.