 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePluriHarms: Benchmarking the Full Spectrum of Human Judgments on AI Harm
Jan 13, 2026Current AI safety frameworks, which often treat harmfulness as binary, lack the flexibility to handle borderline cases where humans meaningfully disagree. To build more pluralistic systems, it is essential to move beyond consensus and instead understand where and why disagreements arise. We introduce PluriHarms, a benchmark designed to systematically study human harm judgments across two key dimensions -- the harm axis (benign to harmful) and the agreement axis (agreement to disagreement). Our scalable framework generates prompts that capture diverse AI harms and human values while targeting cases with high disagreement rates, validated by human data. The benchmark includes 150 prompts with 15,000 ratings from 100 human annotators, enriched with demographic and psychological traits and prompt-level features of harmful actions, effects, and values. Our analyses show that prompts that relate to imminent risks and tangible harms amplify perceived harmfulness, while annotator traits (e.g., toxicity experience, education) and their interactions with prompt content explain systematic disagreement. We benchmark AI safety models and alignment methods on PluriHarms, finding that while personalization significantly improves prediction of human harm judgments, considerable room remains for future progress. By explicitly targeting value diversity and disagreement, our work provides a principled benchmark for moving beyond "one-size-fits-all" safety toward pluralistically safe AI.
Balancing Quality and Variation: Spam Filtering Distorts Data Label Distributions
Sep 10, 2025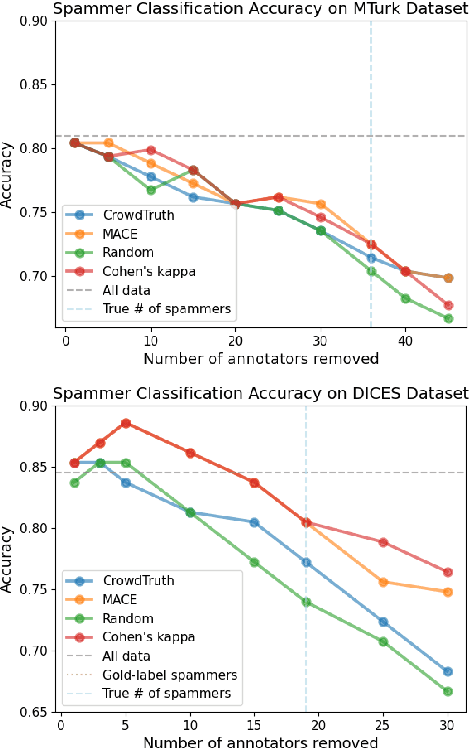
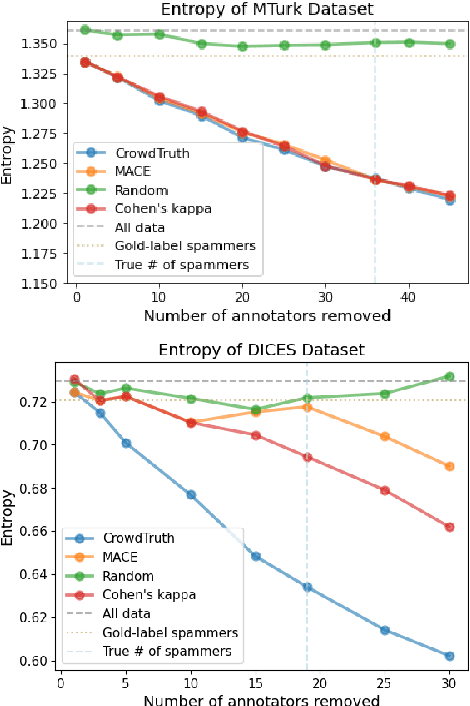
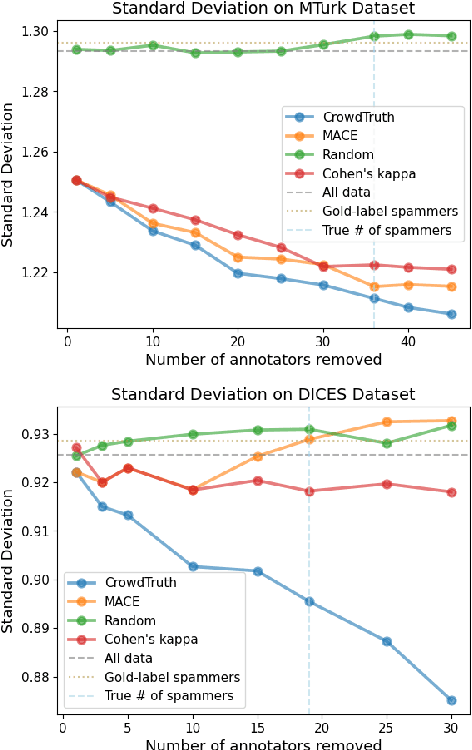
For machine learning datasets to accurately represent diverse opinions in a population, they must preserve variation in data labels while filtering out spam or low-quality responses. How can we balance annotator reliability and representation? We empirically evaluate how a range of heuristics for annotator filtering affect the preservation of variation on subjective tasks. We find that these methods, designed for contexts in which variation from a single ground-truth label is considered noise, often remove annotators who disagree instead of spam annotators, introducing suboptimal tradeoffs between accuracy and label diversity. We find that conservative settings for annotator removal (<5%) are best, after which all tested methods increase the mean absolute error from the true average label. We analyze performance on synthetic spam to observe that these methods often assume spam annotators are less random than real spammers tend to be: most spammers are distributionally indistinguishable from real annotators, and the minority that are distinguishable tend to give fixed answers, not random ones. Thus, tasks requiring the preservation of variation reverse the intuition of existing spam filtering methods: spammers tend to be less random than non-spammers, so metrics that assume variation is spam fare worse. These results highlight the need for spam removal methods that account for label diversity.
GRACE: A Granular Benchmark for Evaluating Model Calibration against Human Calibration
Feb 27, 2025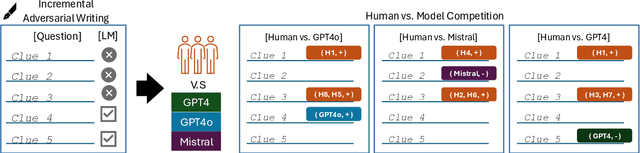
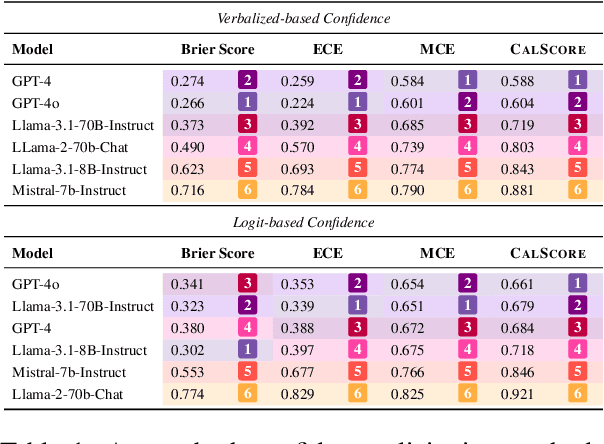
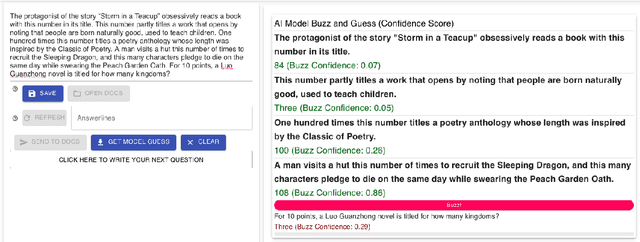
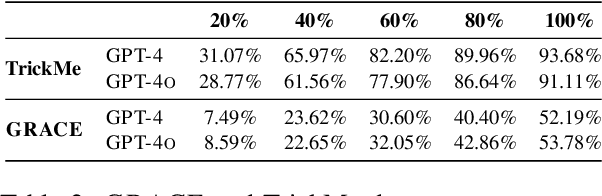
Language models are often miscalibrated, leading to confidently incorrect answers. We introduce GRACE, a benchmark for language model calibration that incorporates comparison with human calibration. GRACE consists of question-answer pairs, in which each question contains a series of clues that gradually become easier, all leading to the same answer; models must answer correctly as early as possible as the clues are revealed. This setting permits granular measurement of model calibration based on how early, accurately, and confidently a model answers. After collecting these questions, we host live human vs. model competitions to gather 1,749 data points on human and model teams' timing, accuracy, and confidence. We propose a metric, CalScore, that uses GRACE to analyze model calibration errors and identify types of model miscalibration that differ from human behavior. We find that although humans are less accurate than models, humans are generally better calibrated. Since state-of-the-art models struggle on GRACE, it effectively evaluates progress on improving model calibration.
Accurate and Data-Efficient Toxicity Prediction when Annotators Disagree
Oct 16, 2024



When annotators disagree, predicting the labels given by individual annotators can capture nuances overlooked by traditional label aggregation. We introduce three approaches to predicting individual annotator ratings on the toxicity of text by incorporating individual annotator-specific information: a neural collaborative filtering (NCF) approach, an in-context learning (ICL) approach, and an intermediate embedding-based architecture. We also study the utility of demographic information for rating prediction. NCF showed limited utility; however, integrating annotator history, demographics, and survey information permits both the embedding-based architecture and ICL to substantially improve prediction accuracy, with the embedding-based architecture outperforming the other methods. We also find that, if demographics are predicted from survey information, using these imputed demographics as features performs comparably to using true demographic data. This suggests that demographics may not provide substantial information for modeling ratings beyond what is captured in survey responses. Our findings raise considerations about the relative utility of different types of annotator information and provide new approaches for modeling annotators in subjective NLP tasks.
ADVSCORE: A Metric for the Evaluation and Creation of Adversarial Benchmarks
Jun 24, 2024



Adversarial benchmarks validate model abilities by providing samples that fool models but not humans. However, despite the proliferation of datasets that claim to be adversarial, there does not exist an established metric to evaluate how adversarial these datasets are. To address this lacuna, we introduce ADVSCORE, a metric which quantifies how adversarial and discriminative an adversarial dataset is and exposes the features that make data adversarial. We then use ADVSCORE to underpin a dataset creation pipeline that incentivizes writing a high-quality adversarial dataset. As a proof of concept, we use ADVSCORE to collect an adversarial question answering (QA) dataset, ADVQA, from our pipeline. The high-quality questions in ADVQA surpasses three adversarial benchmarks across domains at fooling several models but not humans. We validate our result based on difficulty estimates from 9,347 human responses on four datasets and predictions from three models. Moreover, ADVSCORE uncovers which adversarial tactics used by human writers fool models (e.g., GPT-4) but not humans. Through ADVSCORE and its analyses, we offer guidance on revealing language model vulnerabilities and producing reliable adversarial examples.
Standard Language Ideology in AI-Generated Language
Jun 13, 2024
In this position paper, we explore standard language ideology in language generated by large language models (LLMs). First, we outline how standard language ideology is reflected and reinforced in LLMs. We then present a taxonomy of open problems regarding standard language ideology in AI-generated language with implications for minoritized language communities. We introduce the concept of standard AI-generated language ideology, the process by which AI-generated language regards Standard American English (SAE) as a linguistic default and reinforces a linguistic bias that SAE is the most "appropriate" language. Finally, we discuss tensions that remain, including reflecting on what desirable system behavior looks like, as well as advantages and drawbacks of generative AI tools imitating--or often not--different English language varieties. Throughout, we discuss standard language ideology as a manifestation of existing global power structures in and through AI-generated language before ending with questions to move towards alternative, more emancipatory digital futures.
Linguistic Bias in ChatGPT: Language Models Reinforce Dialect Discrimination
Jun 13, 2024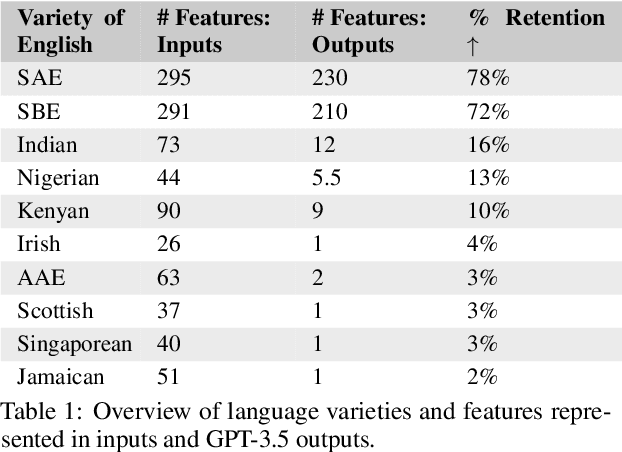
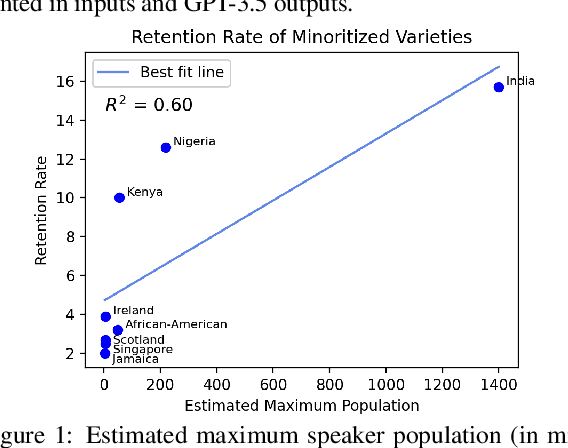
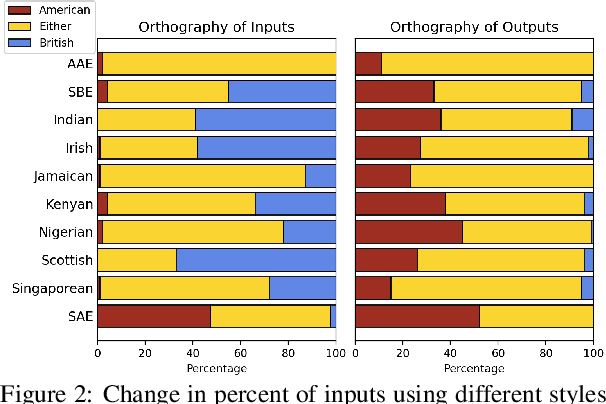
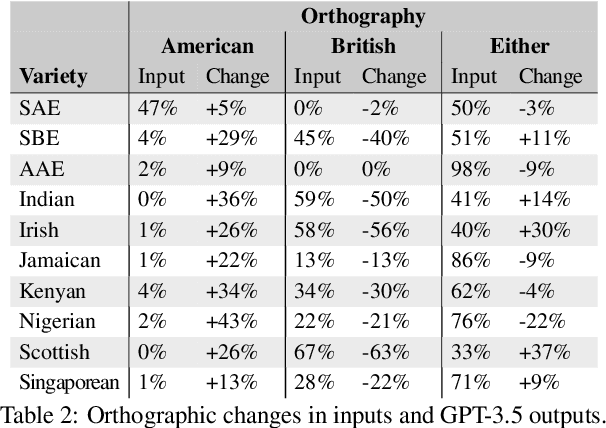
We present a large-scale study of linguistic bias exhibited by ChatGPT covering ten dialects of English (Standard American English, Standard British English, and eight widely spoken non-"standard" varieties from around the world). We prompted GPT-3.5 Turbo and GPT-4 with text by native speakers of each variety and analyzed the responses via detailed linguistic feature annotation and native speaker evaluation. We find that the models default to "standard" varieties of English; based on evaluation by native speakers, we also find that model responses to non-"standard" varieties consistently exhibit a range of issues: lack of comprehension (10% worse compared to "standard" varieties), stereotyping (16% worse), demeaning content (22% worse), and condescending responses (12% worse). We also find that if these models are asked to imitate the writing style of prompts in non-"standard" varieties, they produce text that exhibits lower comprehension of the input and is especially prone to stereotyping. GPT-4 improves on GPT-3.5 in terms of comprehension, warmth, and friendliness, but it also results in a marked increase in stereotyping (+17%). The results suggest that GPT-3.5 Turbo and GPT-4 exhibit linguistic discrimination in ways that can exacerbate harms for speakers of non-"standard" varieties.
The Perspectivist Paradigm Shift: Assumptions and Challenges of Capturing Human Labels
May 09, 2024Longstanding data labeling practices in machine learning involve collecting and aggregating labels from multiple annotators. But what should we do when annotators disagree? Though annotator disagreement has long been seen as a problem to minimize, new perspectivist approaches challenge this assumption by treating disagreement as a valuable source of information. In this position paper, we examine practices and assumptions surrounding the causes of disagreement--some challenged by perspectivist approaches, and some that remain to be addressed--as well as practical and normative challenges for work operating under these assumptions. We conclude with recommendations for the data labeling pipeline and avenues for future research engaging with subjectivity and disagreement.
Mapping Social Choice Theory to RLHF
Apr 19, 2024
Recent work on the limitations of using reinforcement learning from human feedback (RLHF) to incorporate human preferences into model behavior often raises social choice theory as a reference point. Social choice theory's analysis of settings such as voting mechanisms provides technical infrastructure that can inform how to aggregate human preferences amid disagreement. We analyze the problem settings of social choice and RLHF, identify key differences between them, and discuss how these differences may affect the RLHF interpretation of well-known technical results in social choice.
Incorporating Worker Perspectives into MTurk Annotation Practices for NLP
Nov 16, 2023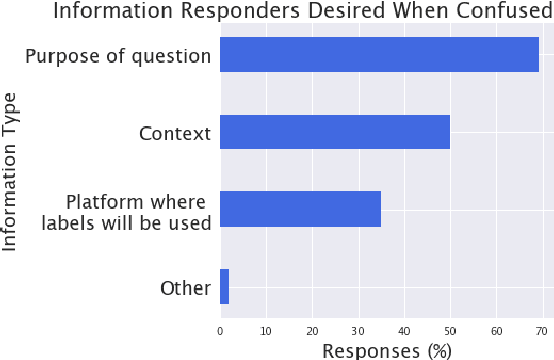
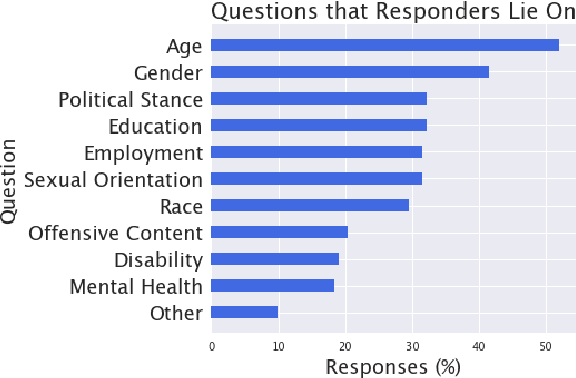
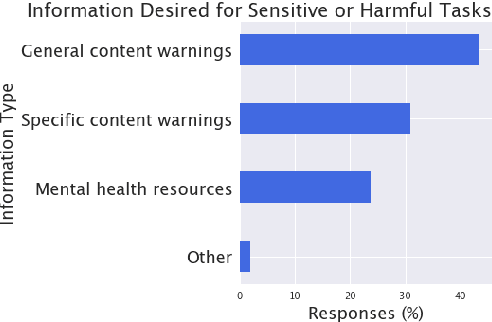

Current practices regarding data collection for natural language processing on Amazon Mechanical Turk (MTurk) often rely on a combination of studies on data quality and heuristics shared among NLP researchers. However, without considering the perspectives of MTurk workers, these approaches are susceptible to issues regarding workers' rights and poor response quality. We conducted a critical literature review and a survey of MTurk workers aimed at addressing open questions regarding best practices for fair payment, worker privacy, data quality, and considering worker incentives. We found that worker preferences are often at odds with received wisdom among NLP researchers. Surveyed workers preferred reliable, reasonable payments over uncertain, very high payments; reported frequently lying on demographic questions; and expressed frustration at having work rejected with no explanation. We also found that workers view some quality control methods, such as requiring minimum response times or Master's qualifications, as biased and largely ineffective. Based on the survey results, we provide recommendations on how future NLP studies may better account for MTurk workers' experiences in order to respect workers' rights and improve data quality.